
Aaron Benton is an experienced architect who specializes in creative solutions to develop innovative mobile applications. He has over 10 years experience in full stack development, including ColdFusion, SQL, NoSQL, JavaScript, HTML, and CSS. Aaron is currently an Applications Architect for Shop.com in Greensboro, North Carolina and is a Couchbase Community Champion.

FakeIt Series 3 of 5: Lean Models through Definitions
In our previous post FakeIt Series 2 of 5: Shared Data and Dependencies we saw how to create multi-model dependencies with FakeIt. Today we are going to look at how we can create the same, but smaller models by leveraging definitions.
Definitions are a way of creating reusable set(s) within your model. It allows you to define a set of properties / values one time, referencing them multiple times throughout your model. Definitions in a FakeIt model are very similar to how definitions are used in the Swagger / Open API Specification.
Users Model
We will start with our users.yaml model that we defined in our first post.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
name: Users type: object key: _id properties: _id: type: string description: The document id built by the prefix "user_" and the users id data: post_build: `user_${this.user_id}` doc_type: type: string description: The document type data: value: user user_id: type: integer description: An auto-incrementing number data: build: document_index first_name: type: string description: The users first name data: build: faker.name.firstName() last_name: type: string description: The users last name data: build: faker.name.lastName() username: type: string description: The username data: build: faker.internet.userName() password: type: string description: The users password data: build: faker.internet.password() email_address: type: string description: The users email address data: build: faker.internet.email() created_on: type: integer description: An epoch time of when the user was created data: build: new Date(faker.date.past()).getTime() |
Lets say that we have a new requirement where we have to support a home and work address for each user. Based on this requirement, we have decided to create a top-level property named addresses that will contain nested properties of home and work.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ ... "addresses": { "home": { "address_1": "123 Broadway St", "address_2": "Apt. C", "locality": "Greensboro", "region": "NC", "postal_code": "27409", "country": "US" }, "work": { "address_1": "321 Morningside Ave", "address_2": "", "locality": "Greensboro", "region": "NC", "postal_code": "27409", "country": "US" } } } |
Our users.yaml model will need to be updated to support these new address properties.
(For brevity the other properties have been left off of the model definition)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
... properties: ... addresses: type: object description: An object containing the home and work addresses for the user properties: home: type: object description: The users home address properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() work: type: object description: The users home address properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() |
As you can see our home and work address properties contain the exact same nested properties. This duplication makes our model bigger and more verbose. Additionally, what happens if our address requirements need to change? We’d have to make two updates to keep the structure the same. This is where we can take advantage of definitions, by defining a single way to create an address and reference it.
(For brevity the other properties have been left off of the model definition)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
... properties: ... addresses: type: object description: An object containing the home and work addresses for the user properties: home: description: The users home address schema: $ref: '#/definitions/Address' work: description: The users work address schema: $ref: '#/definitions/Address' definitions: Address: type: object properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() |
Definitions are defined at the root of the model by specifying a definitions: property, then the name of the definition. Definitions are referenced by using $ref with the value being the path to the definition, for example #/definitions/Address. By using definitions we have saved almost 30 lines of code in our model and created a single place for how an Address is to be defined and generated within our Users model.
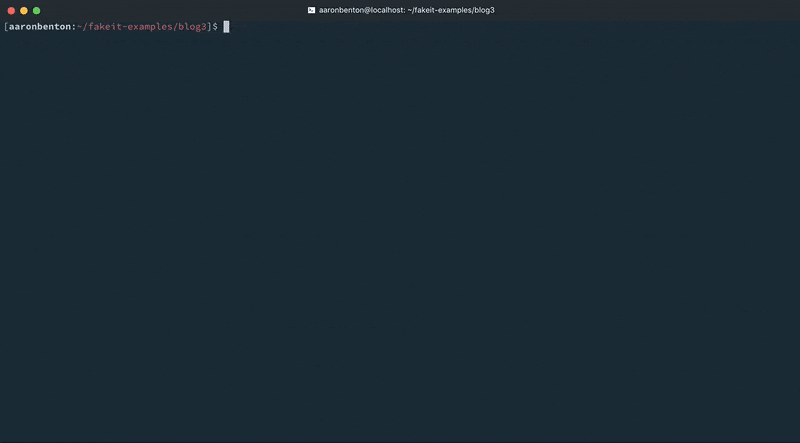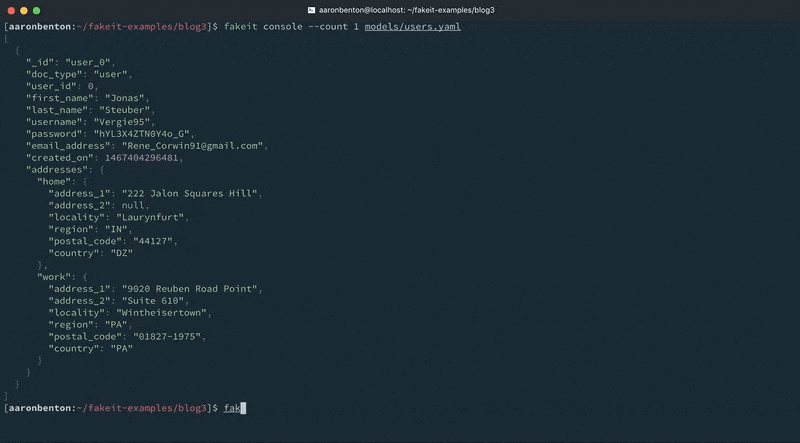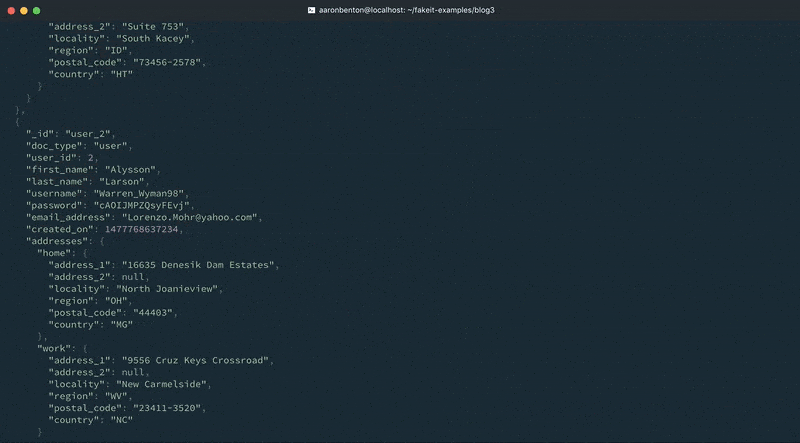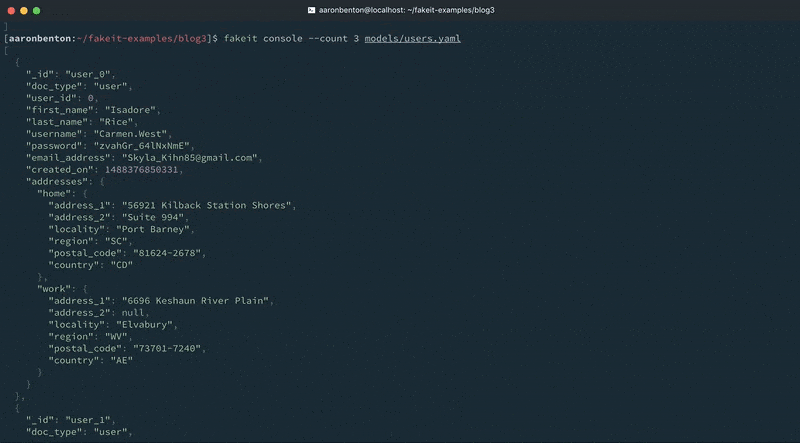
We can test the output of our updated Users model addresses using the following command:
|
1 |
fakeit console --count 1 models/users.yaml |
Now, lets say we have a requirement to store a Users main phone number, and then store optional additional phone numbers i.e. Home, Work, Mobile, Fax, etc. For this change we will use two new top-level properties: main_phone and additional_phones that is an array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ ... "main_phone": { "phone_number": "7852322322", "extension": null }, "additional_phones": [ { "phone_number": "3368232032", "extension": "3233", "type": "Work" }, { "phone_number": "4075922921", "extension": null, "type": "Mobile" } ] } |
While this may not be the most practical data model, or how I personally would have modeled this data we can use this example again to illustrate how we can take advantage of using definitions within our FakeIt model.
(For brevity the other properties have been left off of the model definition)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
... properties: ... main_phone: description: The users main phone number schema: $ref: '#/definitions/Phone' data: post_build: | delete this.main_phone.type return this.main_phone additional_phones: type: array description: The users additional phone numbers items: $ref: '#/definitions/Phone' data: min: 1 max: 4 definitions: Phone: type: object properties: type: type: string description: The phone type data: build: faker.random.arrayElement([ 'Home', 'Work', 'Mobile', 'Other' ]) phone_number: type: string description: The phone number data: build: faker.phone.phoneNumber().replace(/[^0-9]+/g, '') extension: type: string description: The phone extension data: build: chance.bool({ likelihood: 30 }) ? chance.integer({ min: 1000, max: 9999 }) : null |
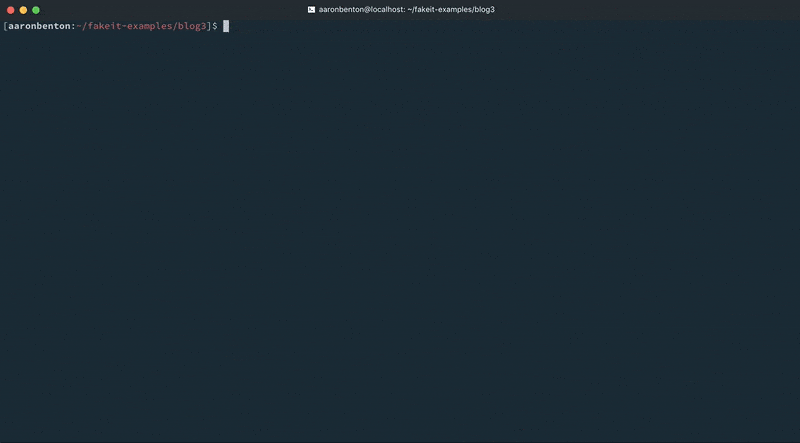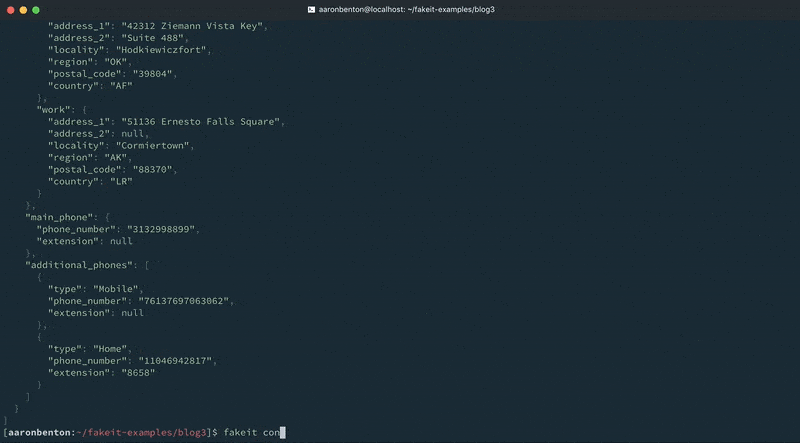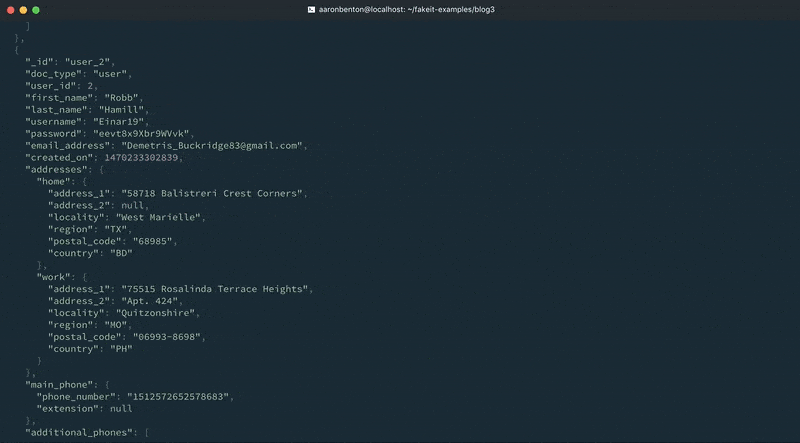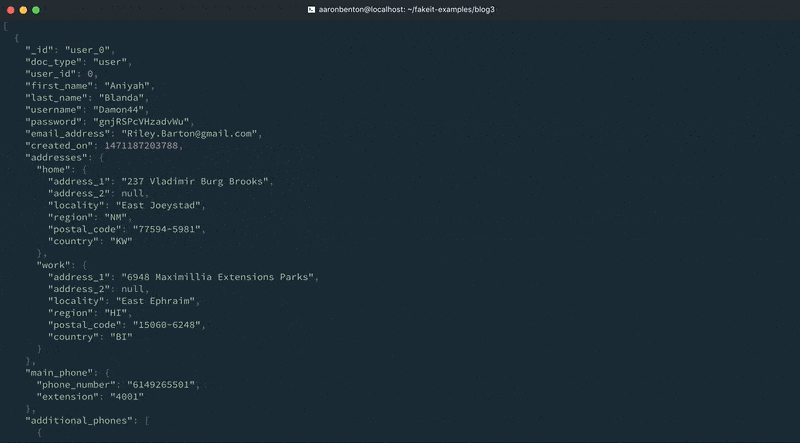
For this example we have created a Phone definition that contains 3 properties: type, phone_number and extension. You will notice that we have defined a post_build function on the main_phone property that removes the type attribute. This is illustrating how definitions can be used in conjunction with a build function to manipulate what is returned by the definition. The additional_phones property is an array of Phone definitions that will generate between 1 – 4 phones. We can test the output of our updated Users model phone numbers using the following command:
|
1 |
fakeit console --count 1 models/users.yaml |
Conclusion
Definitions allow you to streamline your FakeIt models by creating reusable sets of code for smaller more efficient models.
Up Next
- FakeIt Series 4 of 5: Working with Existing Data
- FakeIt Series 5 of 5: Rapid Mobile Development w/ Sync-Gateway
Previous
 This post is part of the Couchbase Community Writing Program
This post is part of the Couchbase Community Writing Program