Search was probably one the most overlooked features in past applications. However, in recent years, it has really gotten all the attention it deserves as we have finally realized how it can increase sales or shape user’s behavior and engagement.
In this new blog series, I would like to go from zero to expert. As such, at the end of it, you will be able to implement searches “like a pro”.
Why “Like %” isn’t good enough?
A well-implemented search should essentially be fast and relevant; “Like %” is neither of them. Let’s see why:
The problem with Speed
Let’s say we would like to implement a search for a movie according to its title. A naive SQL query looking for all “Star Trek” movies would look like the following:
|
1 |
Select * from Movies where title like “Star Trek%” |
By default, it will execute a full table scan trying to match this term to all rows. But it can be optimized with an index, which will create most likely a B-Tree structure. Therefore, even searches like the following would still partially leverage the index:
|
1 2 |
Select * from Movies where title like “Star%Trek” Select * from Movies where title like “St%Trek” |
But what if the user is a big fan of Batman and decides to search for the term “Dark Knight”? According to the previous example, our query will look like the following:
|
1 |
Select * from Movies where title like “Dark Knight%” |
The search above has the won’t bring any results as the real name of the movie is “The Dark Knight Rises”. To fix this problem, let’s add a wildcard at the beginning of our search term:
|
1 |
Select * from Movies where title like “%Dark Knight%” |
Fixed! Right!? Unfortunately, not really. The query above will fina a result like “The Dark Knight Rises”, but it won’t leverage the index anymore and definitely won’t perform well at scale. Like % does not “understand” the content of your field. Rather, it treats a text as a single thing, which makes it not the best choice to deal with anything that has some sort of underlying structure.
A possible solution is to use MATCH, but it has also been reported to be slow in some databases.
The problem with Relevancy
What if we’d like to also search for the movie’s overview? A naive solution would be to just add a new field to the query:
|
1 |
Select * from Movies where title like “%Dark Knight%” or overview like “%Dark Knight%” |
This approach introduces a new problem: any movie with mentions “Dark Knight” in the overview has the same relevance as the ones with it in the title, and the order of the results are totally uncertain.
A common mistake is to think that UNION DISTINCT could solve this problem. However, most of the query planners nowadays execute each block of the union in parallel, which will again mess up with the order/relevancy.
If you really want to implement some sort of relevancy using plain SQL, a simple solution is to execute two separate queries and append the result of one to the other. Of course, this strategy is far from optimal and you’d still need to handle duplication manually.
The examples above show one of the unspoken truths about search: The real challenge in search is not finding a match but how to sort them. After all, matching a text is a very straightforward task, but giving it the right score is something that should be carefully crafted.
Full-Text search comes to the rescue!
There are many different ways to search for a term, each one focusing on a specific strategy. We will cover the majority of them in the upcoming articles, but for now, let’s focus on why FTS is so much better than “Like %”:
The solution for Speed
In order to be able to query a database using FTS, you must create an inverted index first. This index, roughly speaking, is a map of words and their occurrences:
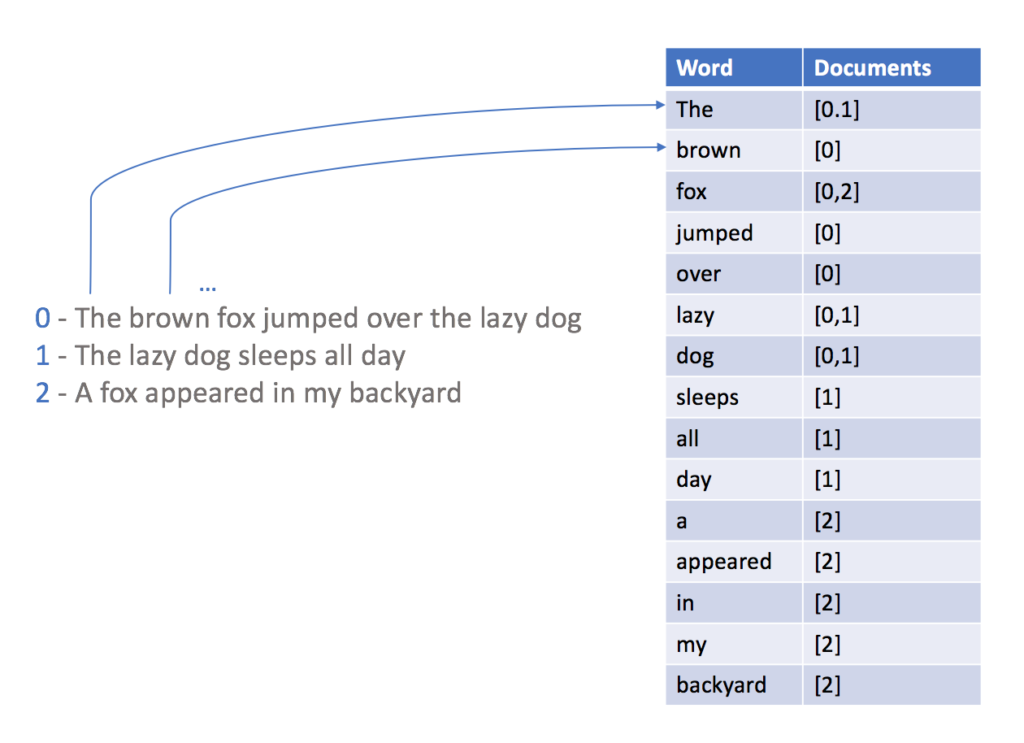
With the index above in place, searching for a word becomes a simple task, as you can easily get only the documents which contain the target term.
Notice that during the creation of the inverted index, we have converted phrases to an array of words, so wildcards aren’t necessary, as we can directly match the target terms against our inverted index. Nonetheless, even the use of wildcards here (Ex: *star*) will still run faster at scale, as you will only need to iterate through your index to find all matches instead of scanning all documents in your database.
I haven’t mentioned anything about dictionaries, stemming, analyzers, tokenizers and synonymous yet. I will get there in part 2 of this series.
The solution for Relevance
The strategy to implement a relevant search result might vary according to the domain you are working on. In general, the relevance can be manipulated in different multiple ways, the simplest one is called boosting. Roughly speaking, boosting is just a simple way to assign a weight for your field matches:
Query:
Title:”Star Trek”^2 | Overview:”Star Trek”
In the example above, the score of a match for “Star Trek” in the title will be worth twice as much as a match in the overview one. This is basically how you can suggest how your search results should be sorted.
Why isn’t everybody using Full-Text Search then?
FTS usually demands you to set up a whole new infrastructure, add new dependencies, create multiple indexes, and then push all your document changes to an external system like Elastic Search or Solr, even if you just want to implement a very simple search like our previous example. Thus, developers tend to avoid this huge amount of work until it becomes strictly necessary.
That is one of the reasons why we have decided to incorporate an FTS Engine called Bleve into Couchbase, then all you need to do is to create a new index in the Web Console:
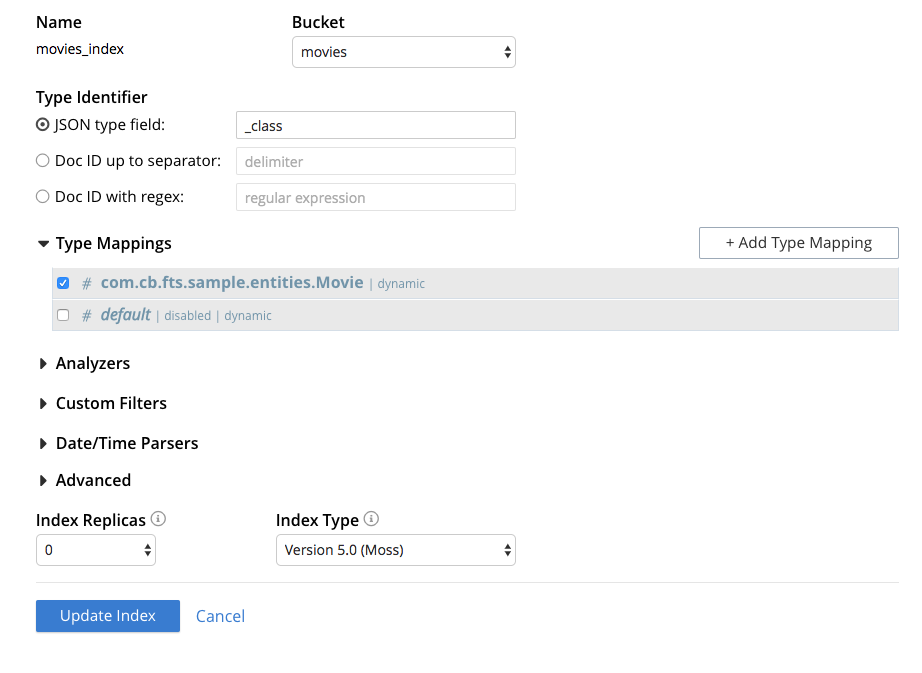
And you will automatically be able to make full-text searches using the default Couchbase SDK:
|
1 2 3 4 |
String indexName = "movies_index"; PhraseQuery query = SearchQuery.phrase("Star Trek"); SearchQueryResult result = movieRepository.getCouchbaseOperations().getCouchbaseBucket().query( new SearchQuery(indexName, query).highlight().limit(20)); |
Most of the relational databases already have support for full-text search, why not just use them?
Actually, it could be a nice choice for small use cases, and I have heard a few positive feedbacks from developers doing so. My personal recommendation is that you should consider a proper tool, such as Bleve, whenever you have a considerable volume of data, or whenever you will need to scale massively.
There is another big plus of using a proper FTS engine: the query language. The majority of the relational databases try to reuse SQL for that, and it can get really messy if you try to write advanced searches. After all, SQL wasn’t designed to deal with conjunction/disjunction queries, facets, complex ranking factors, etc.
Full-Text Search Series
- Understanding analyzers and tokenizers – Part 2
- Fuzzy Matching – Part 3