
Intro
For the last couple weeks, I’ve had Spark on the brain. It’s understandable, really, since I’ve been preparing an O’Reilly webinar “How to Leverage Spark and NoSQL for Data Driven Applications” with Michael Nitschinger and a different talk, “Spark and Couchbase: Augmenting the Operational Database with Spark” for Spark Summit 2016 with Matt Ingenthron. Elsewhere you can learn about the Couchbase Spark Connector, what’s in our new release, and how to use it. In this blog, I want to talk about why the best database combination is Apache Spark and a NoSQL database make a good combination.
Spark 101
If you’re not familiar with it, Spark is a big data processing framework that does analytics, machine learning, graph processing and more on top of large volumes of data. It’s similar to Map Reduce, Hive, Impala, Mahout, and the other data processing layers built on top of HDFS in Hadoop. Like Hadoop, it is focused on optimizing through but better in many respects: it’s generally speaking faster, much nicer to program, and has good connectors to almost everything. Unlike Hadoop, it’s easy to get started writing and running Spark from the command line on your laptop and then deploy to a cluster to run on a full dataset.
What I’ve said so far might make it sound like Spark is a database, but it’s emphatically not a database. It’s actually a data processing engine. Spark reads data en masse that’s stored somewhere like HDFS, Amazon S3 or Couchbase Server, does some processing on that data, and then writes its results out so they can be used further. It’s a job based system, like Hadoop, rather than an online system, like Couchbase or Oracle. That means Spark always pays a startup cost that rules it out for quick random read / write type workloads. Like Hadoop, Spark rocks when it comes to overall throughput of the system but that comes at the expense of latency.
In short, Couchbase Server and Spark solve different problems but they are both good problems to solve. Let’s talk about why people use them together.
NoSQL and Spark Use Case #1: Operationalizing Analytics / Machine Learning
No question about it: data is great stuff. The large online applications that run on Couchbase tend to have a lot of it. People create more of it every day when they shop online, book travel, or send each other messages. When I browse a product catalog and put a new camera lens in my cart, some information has to be stored in Couchbase so that I can complete my purchase and get my new goodies in the mail.
A lot more can be done with data from my shopping trip that’s invisible to me: it’s analyzed to see what products are commonly purchased together, so that the next person who puts that lens in their shopping cart gets better product recommendations so that they are more likely to buy. It may be checked for signs of fraud to help protect me and the retailer from bad guys. It might be tracked to figure out if I need a coupon or some other incentive to complete a purchase I’m otherwise on the fence about. These are all examples of machine learning and data mining that companies can do using Spark.
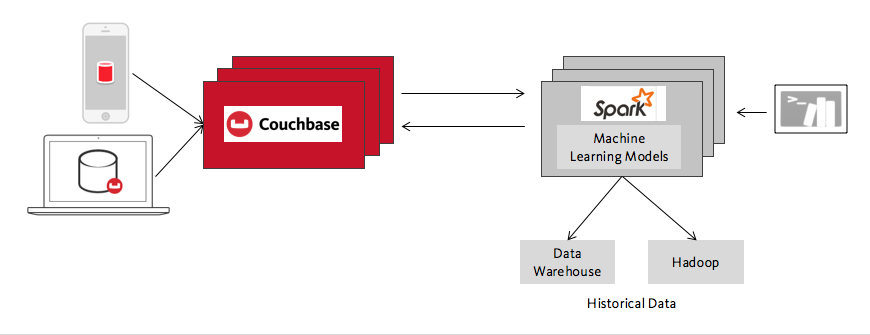
In this broad family of use cases, Spark provides machine learning models, predictions, the results of big analytics jobs, and so forth, and Couchbase makes them interactive and scales them to large numbers of users. Some other examples of this besides online shopping recommendations include spam classifiers for real time communication apps, predictive analytics that personalize playlists for users of an online music app, and fraud detection models for mobile applications that need to make instant decisions to accept or reject a payment. I would also include in this category a broad group of applications that are really “next-gen” data warehousing, where large amounts of data needs to be processed inexpensively and then served in an interactive form to many, many users. Finally, internet of things scenarios fit in here as well, with the obvious difference that the data represents the actions of machines instead of people.
What these use cases all have in common technically is the division into an operational database and an analytic processing cluster, each optimized for its workload. This split is like the division between OLTP and OLAP systems, updated for the age of big data. We’ve talked about the analytical side Spark, now let’s talk about Couchbase and the operational side.
Couchbase: Fast Access to Operational Data at Scale
Couchbase Server was made to run applications that are fast, scalable, easy to manage, and agile enough to evolve along with your business requirements. The types of applications that tend to use Spark machine learning and analytics also tend to need the capabilities that Couchbase delivers:
- Flexible data model, dynamic schemas
- Powerful query language (N1QL)
- Native SDKs
- Sub-millisecond latencies for key value operations at scale
- Elastic Scaling
- Ease of Administration
- XDCR (Cross Datacenter Replication)
- High Availability & Geographic distribution
Your operational data processing layer has to be distributed for resiliency, high availability, and for performance reasons because proximity to a user’s geographic location matters. The distribution mechanism should be transparent to developers, and should be simple to operate. All these properties, which are true whether or not you’re using Spark, have been covered extensively elsewhere.
The Couchbase Spark Connector provides an open source integration between the two technologies, and it has some benefits of its own:
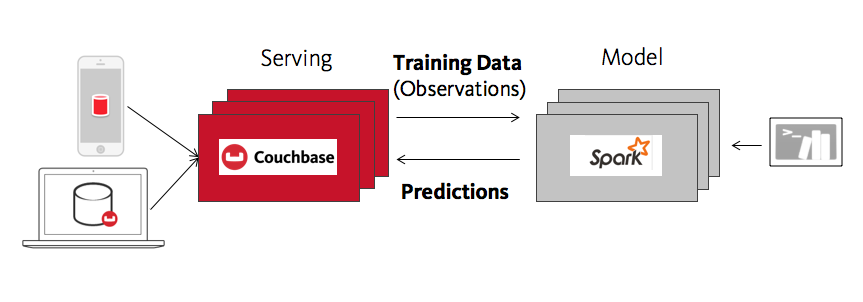
- Memory-Centric. Both Spark and Couchbase are memory-centric. This can significantly reduce the first round trip data processing time, or to also reduce end-to-end time to insight / time to action. Time to insight refers to the round trip from “making an observation” (storing some data about what a user or machine is doing) to analyzing that data, often in the context of building or updating a machine learning model, and then feeding that back to the user in a form they can use, like a new and improved prediction.
- Fast. In addition to the fact that both Spark and Couchbase are memory centric, the Couchbase Spark Connector includes a range of performance enhancements including predicate push down, data locality / topology awareness, sub-document API support and implicit batching.
- Functionality. The Couchbase Spark Connector lets you use the full range of data access methods to work with data in Spark and Couchbase Server: RDDs, DataFrames, Datasets, DStreams, KV operations, N1QL queries, Map Reduce and Spatial Views, and even DCP are all supported from Scala and Java.
NoSQL and Spark Use Case #2: Data Integration Toolkit
The wide range of functionality supported by the Couchbase Spark Connector brings us to the other major use case for Spark and Couchbase: Data Integration.
Interest in Spark has exploded in recent years, with the result that Spark Connects to nearly everything, from databases to Elasticsearch to Kafka to HDFS to Amazon S3 and much more. It can read data in nearly any format too, like Parquet, Avro, CSV, Apache Arrow, you name it. All this connectivity makes Spark a great toolkit for solving data integration challenges.
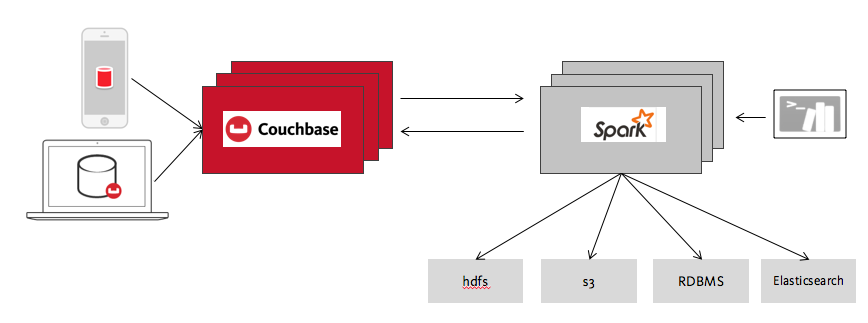
For example, imagine you are a data engineer. You need to load information about your users’ interests into their user profiles to support a new premium feature you’re adding to your mobile application. Let’s say your user profiles are in Couchbase Server, your user interests will come from HDFS and your list of premium users is based on payment information in your data warehouse.
This sounds like a relatively simple but tedious task, where you go to each system in turn to dump out the information you need and then import it into the next system. Spark provides a handy alternative. Once you know your way around, you can perform this task using a few simple queries from your command line. Using the native capabilities of each of the systems, you can JOIN the tables in Spark and write the results to Couchbase in one step. It doesn’t get more convenient. The same steps can be scaled up to create data pipelines that combine data from multiple sources and feed it to applications or other consumers.
Try it out
Whether you’re developing a big application with sophisticated machine learning as part of a large engineering team or you’re a lone wolf developer, Spark and Couchbase has something to offer. Try it out and let us know what you think. As always, we like to hear from you. Happy coding!
[…] Still wondering Why Spark and NoSQL? […]