
This article builds on top of the session “When Couchbase meets Splunk, the real-time, AI-driven data analytics platform” presented at Couchbase Connect Online 2020 by James Powenski and Andrea Vasco.
The Wall of Confusion
Ever since I was a University student, I had always been fascinated with data science. Back in the day, it was not yet a thing one would brag about – but I still remember how I felt the first time I stumbled upon estimation theory.
We now live in a Golden Age of Data, an era in which datasets grew exponentially, becoming publicly available; today, many great platforms provide streamlined ways to take advantage of machine learning and deep learning techniques to bring the decision-making process to a superhuman level.
Multi-Dimensional Scaling (MDS) is one of my preferred Couchbase features, with a soft spot for Indexing, Querying, and Analytics workloads isolation: I spent several years mining data on relational databases looking for patterns and correlations across large datasets, and many times I found myself – needless to say – running complex queries that would generate friction with DBAs about locks, degradation of performance, and so on.
I hit hard on the so-called Wall of Confusion, I guess. This problem was (and is) too so dear to me that in 2013 we wrote a paper about the demystification of Oracle workload characterization.
Setting the scene: bringing Continuous Intelligence in ACME
In 2019, Gartner identified Continuous Intelligence as a Top-10 Analytics trend, estimating that by 2022 “more than 50% of all business initiatives will require continuous intelligence, leveraging streaming data to enhance real-time decision-making”.
In this article – and series – we will walk you through a practical way to get yourself started with Continuous Intelligence with Couchbase, aiming at disrupting your business towards digital transformation without significantly impacting your daily operations; we will pretend to be a Site Reliability Engineer (SRE) at ACME Inc., tasked with the mission of implementing Continuous Intelligence for ACME’s online store.
We will assume you have a basic familiarity with Couchbase Analytics. As shown in the picture below, Couchbase Analytics allows to create, in real-time, shadow copies of data stored into the KV Engine within a Massive Parallel Processing (MPP) architecture, that can be used to either query the shadow data using a SQL-like language (SQL++) and expose large, pre-aggregated datasets to third party solutions for further processing.
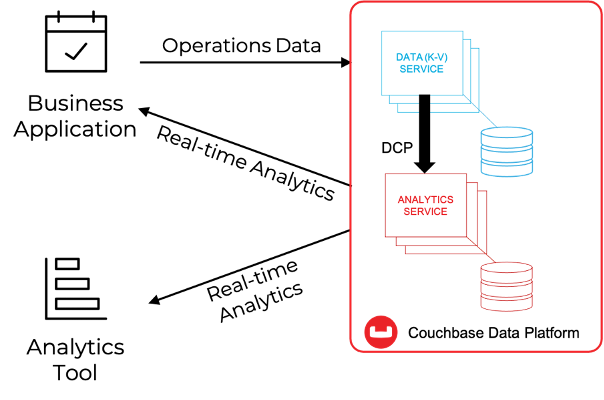
Couchbase provides the foundational technology needed to kickstart ACME’s journey towards Continuous Intelligence: the flexibility of NoSQL built onto a platform capable of sub-millisecond operations, workload isolation, multi-dimensional linear scalability, and integration with third-party solutions, all combined in one elegant platform spanning from the Multi-cloud to the Edge.
As SRE at ACME, we can easily understand how Couchbase can provide a world-class enterprise data plane for the next-gen online store. What about business logic, though?
Well, it depends on what kind of business logic is needed from our business: Couchbase provides, out of the box, a complete set of capabilities required to either programmatically retrieve individual documents or run ad-hoc/a priori queries (query or analyze). But for ACME’s next-gen online store, we may want to elevate our game and scout synergies with the many enterprise solutions in today’s market that ship the full analytics arsenal – data exploration, observability, data navigation, real-time dashboarding, Machine Learning, and AI.
It goes without saying, Couchbase is designed to integrate with them, and in today’s example, we will be using Couchbase Analytics REST APIs to integrate with Splunk.
Why Splunk? Here are a few compelling reasons – without getting too much into detail:
- Level of Adoption and Maturity: Splunk is a market leader in the ITOM space, so chances are that your organization already as skills and environments for you to experiment with
- Local Trial Version: if you are on a tight budget, you can install Splunk locally and use it for free for a 60 days trial period
- Ease of Use: Splunk Search Processing Language (SPL) is quite easy to learn yet powerful, and there are tons of resources available to get you started
- Splunk Apps: Splunk comes with a vibrant ecosystem of one-click-install applications, including a Machine Learning Toolkit capable of unlocking ML models without the need of coding – and ideal tool for beginners and those not entirely familiar with libraries like Pytorch, Pandas, TensorFlow.
As an ACME SRE, we might ask ourselves: will a simple implementation be capable of delivering significant results? Data scientists will hopefully be willing to confirm, at the current state of the industry, the market’s need for AI does not necessarily require the latest, cutting edge algorithms; as it turns out, traditional techniques like regression, outlier detection, clustering, sentiment analysis are the most effective tools that an organization can implement today to drive digital transformation.
Naturally, it’s a good practice to have a basic understanding of the theory behind these techniques. In contrast, you will not need to know about Convolutional Networks, Reinforcement Learning, Generative Adversarial Networks, Blenders, and so on.
Well, it sounds like we have the plan – time for the rubber to hit the road! In the next paragraphs, we are going to:
- Generate and import into Couchbase a series of JSON documents representative of transactions performed onto the online store;
- Replicate this information into an Analytics dataset
- Use SQL++ to run queries on this Dataset, and collect the results into Splunk via the Analytics REST APIs.
- Use Splunk to create dashboards to showcase operational data and Machine Learning predictions in real time[1]
Grab a cup of tea, and get ready: we are about to take off. Let’s go!
6 Steps to Continuous Intelligence
Step #1: Generating Data
To ensure compliance with the data regulations, we will use an online tool called JSON generator[2] to generate JSON documents representative of transactions on ACME’s online store; below how we have configured the generation parameters[3]:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[ '{{repeat(120 ,2000 )}}', { _id: 'order_{{objectId()}}', orderId:'{{integer(90000,1256748321)}}', transaction:'{{random("declined","approved")}}', name: '{{firstName()}} {{surname()}}', gender: '{{gender()}}', email: '{{email()}}', country: '{{country()}}', city: '{{city()}}', phone: '{{phone()}}', ts: Date.now()+600000, product: [ '{{repeat(1,9)}}', 'product: {{random("apples", "tea bags", "butter", "milk", "kale", "wine", "cookies", "hamburgers", "sweet potatoes", "brown rice", "barley" ) }}' ] } ] |
Once you click on “Generate”, the tool will respond with a variable set of JSON documents (between 120 and 2000), as per the screenshot below.
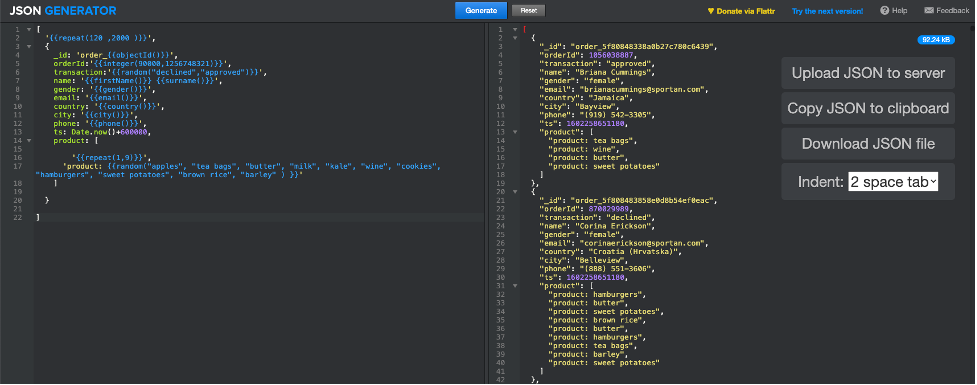
We have our baseline, time to move to Couchbase!
Step #2: Importing data in Couchbase
We will assume to have a Couchbase cluster already available, running at least the data and the analytics service.
As a first step, we will create a bucket named couchmart (feel free to name it as you like) in which the JSON documents will be loaded.
We will then upload the JSON files to the Couchbase cluster; pick a node running the data service, and import the files into the /tmp folder (you can use any folder you like). If you have SCP available, run this command from the terminal of your local machine:
|
1 |
Scp <jsonfile> <couchbaseuser>@<couchbaseserver>:/tmp |
Just make sure to set <jsonfile>, <couchbaseuser> and <couchbaseserver> according to your environment.
Last, we will import the JSON files into the couchmart bucket, using the cbimport command (more information here); first, log into the data node into which you previously uploaded the files via SSH:
|
1 |
ssh <couchbaseuser>@<couchbaseserver> |
Once successfully logged in, run the cbimport command as described below, making sure to set the fields between <> according to your environment:
|
1 2 |
$CBHOME/bin/cbimport json -c couchbase://localhost -b <bucketname> -u <user> - p <password> -f list -d file:///tmp/<jsonfile> -g %_id% -t 4 |
The import should complete in a bat of an eyelid, as Couchbase can handle orders of magnitude more. You should confirm that our bucket now has some documents from the Couchbase Admin UI in the buckets section – see screenshot below.
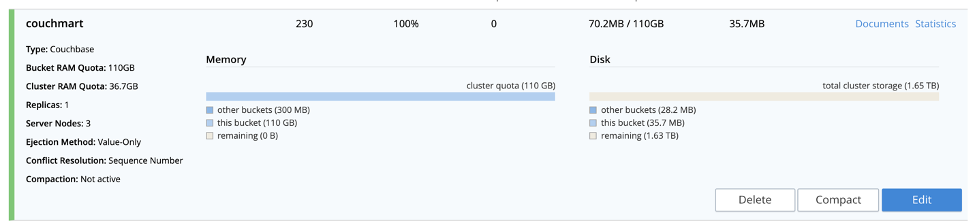
We have data; it’s time for some Analytics!
Step #3: Create and test Analytics Datasets
As a first step, we will create a dataset named acmeorders (guess what? you can name it however you want!) as a shadow replica of the couchmart bucket; this dataset will contain all the information exposed downstream to Splunk.
If you are not familiar with creating datasets, we recommend checking the documentation and this tutorial. Two SQL++ commands are all it takes to create a full replica of the couchmart buckets:
|
1 |
CREATE DATASET acmeorders ON couchmart; |
followed by:
|
1 |
CONNECT LINK Local; |
It can’t get any easier than this!
Since we are going to use the rest APIs, now is a good time to test them using the handy curl command below; as always, double-check the values within <> and the configured port for the analytics service:
|
1 |
curl -v -u <user>:<password> --data-urlencode "statement=select * from acmeorders;" http://<couchbaseserver>:8095/analytics/service |
If this command works, Couchbase is ready to roll. Before we move on to Splunk, please remember that:
- Couchbase Analytics service relies on a massive parallel processing architecture (MPP) that scales linearly; that means that should you need to double the performances, just double the nodes.
- In version 6.6, we introduced many great features to the Analytics service; make sure to check them out!
All right, Couchbase has our back, time for some actionable intelligence!
Step #4: Setting up and configuring Splunk
For the rest of this document, we will assume to have Splunk running on Linux, so the paths might change if you are on Mac or Windows.
If you don’t have a Splunk instance available, you can install a local instance taking advantage of a 60-days free trial. A brand new local installation should take you no longer than 10 minutes to complete.
Make sure to install the Splunk Machine Learning Toolkit, as well; if you need to know more about how to install a Splunk app, click here – it’s super simple!
To effectively set up the integration with Couchbase (or any other source), it’s fundamental to configure Splunk to correctly interpret the output of the REST call from Couchbase and store the information in a format effective for SPL. We will accomplish this by creating a new source type: in short, a source type defines how Splunk parses data in input; we will not deep dive into how to create a source type, but will provide with a workable solution.
Connect via SSH to your Splunk server, and then browse to:
|
1 |
Cd $SPLUNKBASE/etc/system/local |
Create a new file called props.conf as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[couchbase] SEDCMD-remove_header = s/(.+\"results\":\s\[\s)//g SEDCMD-remove_trailing_commas = s/\},/}/g SEDCMD-remove_footer = s/(\],\s\"plans\".+)//g TIME_PREFIX = \" ts\":\s+ category = Structure disabled = false pulldown_type = 1 BREAK_ONLY_BEFORE_DATE = DATETIME_CONFIG = LINE_BREAKER = (,)\s\{ NO_BINARY_CHECK = true SHOULD_LINEMERGE = false |
Once saved, restart Splunk. You should now be able to use a new source type called couchbase; just browse over Settings > Source Types to double-check all looks good:
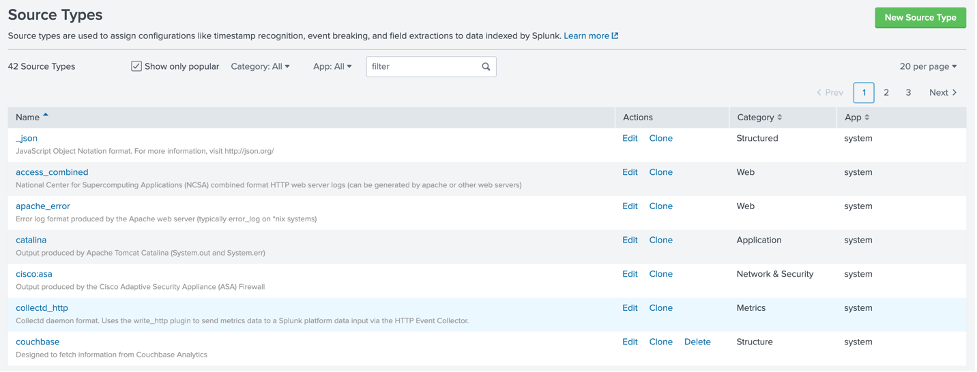
It’s now time to create a new Splunk Events Index that we will use to capture the ACME store transactions as queried from Couchbase; in Splunk, browse under Settings > Indexes and click New, then configure a new Index as follows:
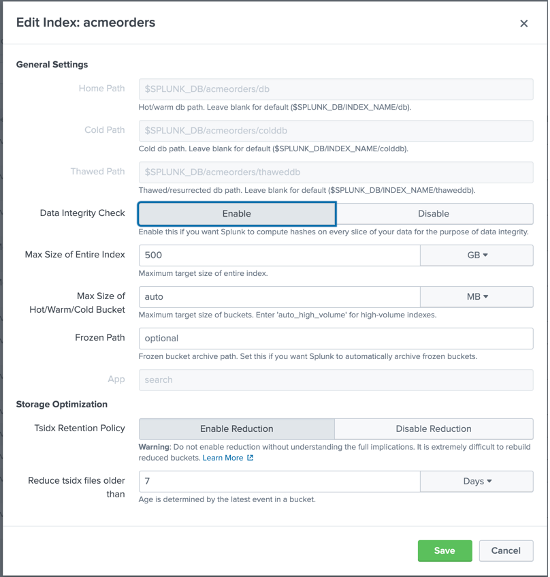
Please notice that we named the index acmeorders, and even though you can name it however you want, we strongly encourage you to keep the same name – so you will be able to use the files we’ll share with you without modifying the underlying SPL code.
Splunk is ready; let’s open up the gates and let Couchbase feed some data!
Step #5: Importing data into Splunk
Importing data into Splunk comes down to defining a new data input. Notice that many Splunk extensions are available to handle REST inputs; however, for simplicity, we will configure a script-based local input[4].
First, we need to create a script; connect via SSH to your Splunk server, and then browse to:
|
1 |
Cd $SPLUNKBASE/bin/scripts |
Create a new file called acmeorders.sh as follows; make sure to grant execution permissions to the splunk user:
|
1 2 |
#!/bin/bash curl -v -u <user>:<password> --data-urlencode "statement=select * from acmeorders where ts>unix_time_from_datetime_in_ms(current_datetime()) - 90000;" http:// <couchbasenode>:8095/analytics/service |
As you might have noticed, the script uses the same curl command we used earlier while testing the acmeorders dataset, with a catch: a where condition. It’s important to limit the amount of data being imported at each run to avoid massive data duplication, as we will be polling Couchbase every 30 seconds.
The SQL++ where condition:
|
1 |
Where ts>unix_time_from_datetime_in_ms(current_datetime()) - 90000 |
will retrieve only those documents whose timestamp is at least 90 seconds old; in other words, we will be able to survive 2 failed polls without losing any data.
Before moving on, it’s important to underline how this approach may work well to run a proof of concept, while for production, you should consider more efficient ways to use placeholders and bookmarks to make sure only new data is read at any given time, or consider an eventing-based strategy if applicable.
Test the script by prompting on terminal:
|
1 |
$SPLUNKBASE/bin/scripts/acmescript.sh |
If this test is successful, it’s time to set up the new data input. In Splunk, navigate under Settings > Data inputs, and choose a new local input based on a script.
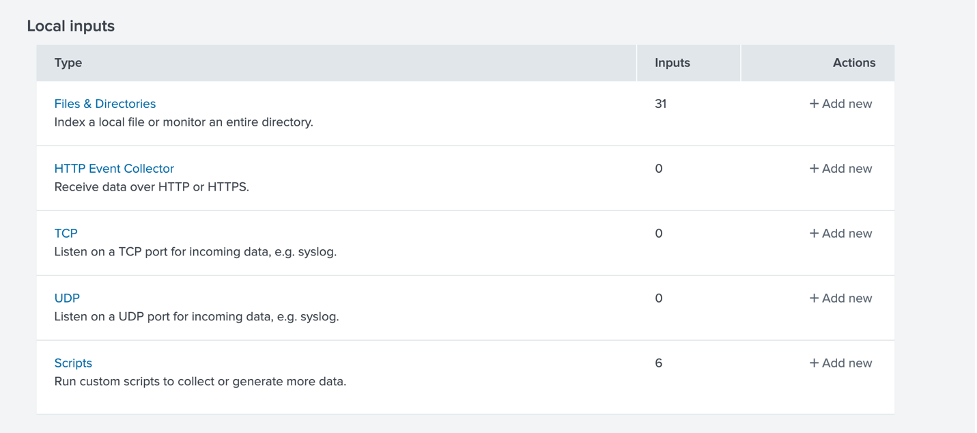
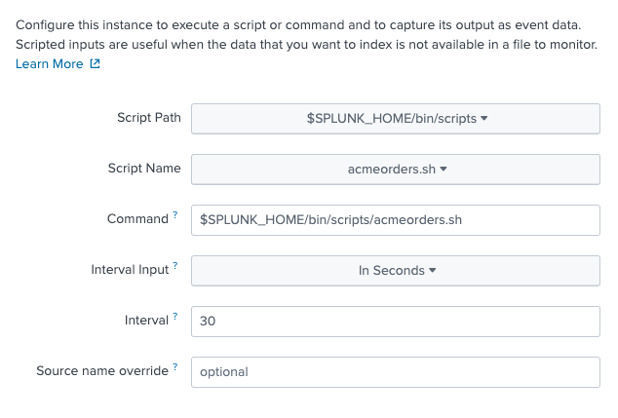
Click on Scripts, then New Local Scripts, and configure a new script as follows; first, configure the script path and polling frequency:
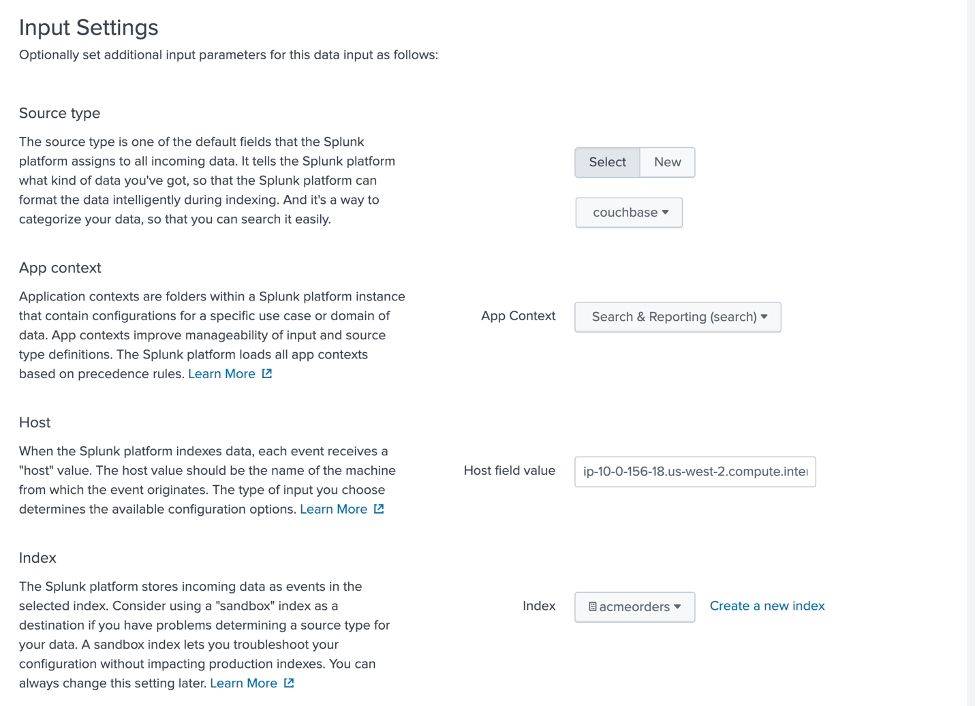
Then, configure the input settings as shown below – paying attention to select couchbase as a source type, Search & Reporting as App Context, and acmeorders as an index.
Review and submit to save. To make sure that data is flowing into Splunk correctly, access the Search and Reporting App:
and try the following SPL query – making sure to select All Time instead of Last 24 hours from the time filter combo box:
|
1 |
index="acmeorders" sourcetype="couchbase" | dedup acmeorders.orderId | search acmeorders.product{}=* | table _time, acmeorders.name, acmeorders.gender, acmeorders.country, acmeorders.gender, acmeorders.city, acmeorders.orderId, acmeorders.product{} , acmeorders.transaction | rename acmeorders.product{} as product | rename acmeorders.gender as gender | rename "acmeorders.transaction" as approval | rename acmeorders.orderId as orderId | rename acmeorders.name as name | rename acmeorders.country as country | rename acmeorders.city as city |
You should see something similar to the picture below:
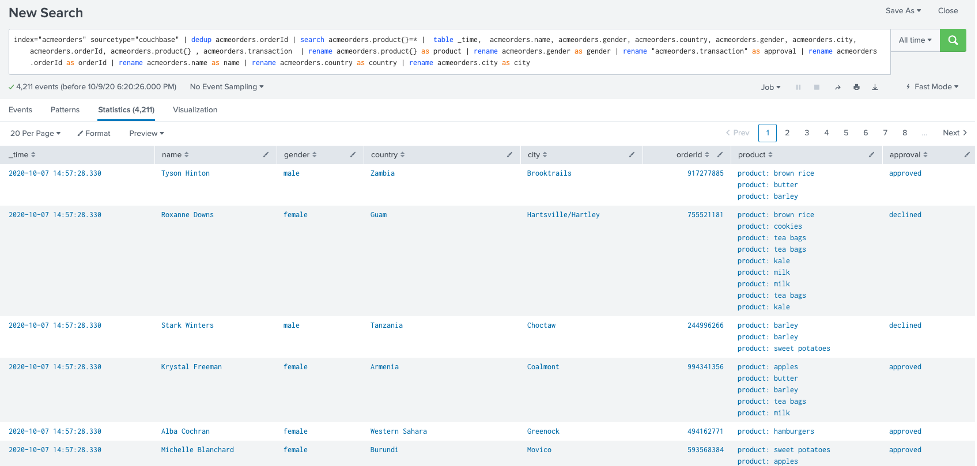
If this test succeeds… Congratulations! You have integrated Splunk with Couchbase!
One final step: unleash Continuous Intelligence!
Step #6: Deploying a Splunk dashboard with ML-driven anomaly detection
To be considerate of time, we will not deep dive into how to create Dashboards and Machine Learning models in Splunk; instead, we will provide you with a fully functional dashboard configured to refresh itself every 30 seconds, taking advantage of the Simple XML Reference featured in Splunk.
To import the template dashboard, log into Splunk, and in the Search and Reporting App click on Dashboards and then “Create a New Dashboard”; give it a name of your choice, click on “Create Dashboard”.
On the top of the screen, you should now see the “Source” button – click on it:

Just paste the XML code contained in this file. Once done, click Save, and kick back… We are done!
As in the below picture, you should now have access to a dashboard showing the total orders ingested, information about products and transaction approvals, and outliers detected using Machine Learning – updated in real-time!
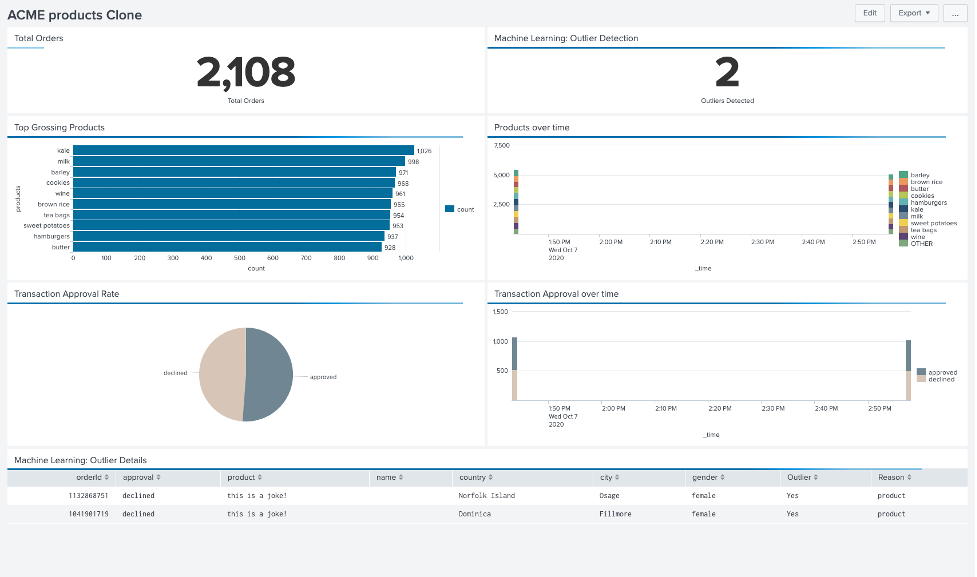
Call to Action: get the genie out of the bottle!
Before letting you go unleash Continuous Intelligence in your organization, here is our call to action for you:
- Review the session James Powesnki, and I hosted at Couchbase Connect 2020, “When Couchbase meets Splunk/ the real-time, AI-driven data analytics platform.”
- Run multiple new data imports using JSON generator and the same procedure we used before (or any equivalent solution) to better appreciate how fast changes are propagated downstream
- Experiment with outliers, in example running JSON generator with the configuration shown below, that will generate up to two documents, with a null name attribute and a dummy product name that should trigger the outlier detection:
123456789101112131415161718['{{repeat(1,2)}}',{_id: 'order_{{objectId()}}',orderId:'{{integer(90000,1256748321)}}',transaction:'{{random("declined","approved")}}',name: '',gender: '{{gender()}}',email: '{{email()}}',country: '{{country()}}',city: '{{city()}}',phone: '{{phone()}}',ts: Date.now()+600000,product: ['this is a joke']}] - Experiment with other ML-driven insight! For the purpose of this article, we focused on Outlier Detection as it is the only analysis that could be easily exported into XML; there are many other value routes worth exploring, though:
- Clustering: to segment the customer base
- Forecasts: to predict the demand for goods, taking into account seasonality
- Category Predictions: to anticipate customer’s needs and drive retention
- Enhance the analytics datasets taking advantage of the new Remote Links and External Data features introduced in Couchbase 6.6
Thanks for reading through the full post; I hope you have found it insightful. If you have any questions, please feel free to reach out to me or get in touch with your closest Couchbase representative!
Now get out there, and lead your business to the next level!
[1] Refresh every 30 seconds
[2] FakeIt would make another great option as well, more powerful yet slightly more complicated
[3] We adjusted the timestamp ts to match the clock on the Couchbase Cluster; feel free to modify it accordingly to your needs
[4] Depending on your needs, it might not be the most efficient solution, but it’s an easy way to get you started