Indexes are the underlying infrastructure that make full-text search possible.
The new Scopes and Collections feature in Couchbase Server 7.0 makes full-text search in your applications more powerful than ever before. Powering those searches requires full-text indexes.
This article provides an overview of Scopes and Collections in Couchbase and walks you through creating a full-text index via the new Couchbase Quick Editor. We’ll also look at changes to the Standard Editor to accommodate Scopes and Collections.
What Is Full-Text Search?
Full-Text Search (FTS) refers to techniques for searching text within a document or a collection of documents. Couchbase supports indexing and searching text from various languages and provides customizable text analyzers to interpret text in various ways via tokenizers, filters, etc.
The Collections paradigm within a Couchbase bucket lets users define indexes that can subscribe to multiple Scopes and Collections. But what, exactly, are Scopes and Collections?
What Are Scopes & Collections?
A Couchbase bucket – the document-based, partitioned, distributed database – is the core of Couchbase Server. With the 7.0 release, you can categorize documents by configuring buckets to form an organizational hierarchy. Each category is held within a sub-bucket (that is also partitioned); that sub-bucket is a Collection. Each bucket is now managed via a three-layer hierarchy, as you can see in the image below.
Here’s a sample bucket and it’s categorization with Scopes and Collections for a restaurant menu. (For more context of the relationship between Scopes and Collections, read this primer on understanding Scopes and Collections.)
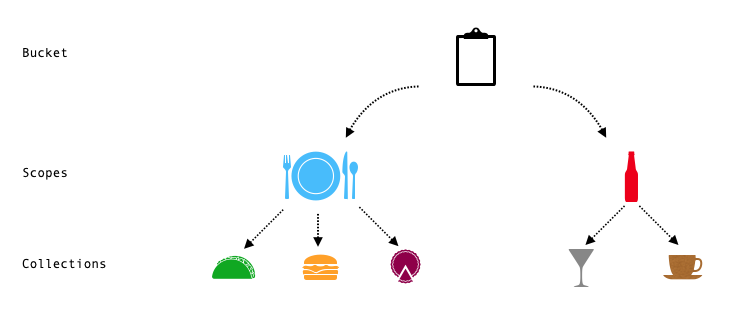
For this bucket hierarchy, you can define a full-text search index to subscribe to and index data such as:
-
- The contents of all the vegetarian tacos within the food Scope of the menu
- The meats used in all the burgers within the food Scope of the menu
- The types of cocktails and coffee drinks within the drink Scope of the menu
You get the idea.
Note: You can define a full-text index to subscribe to several Collections, but all those Collections must belong to a single Scope. An index definition cannot transcend a Scope.
Let’s Talk Index Definitions
The screenshot below shows how to add an index in the standard Couchbase editor (as it looked in Couchbase Server 6.6).
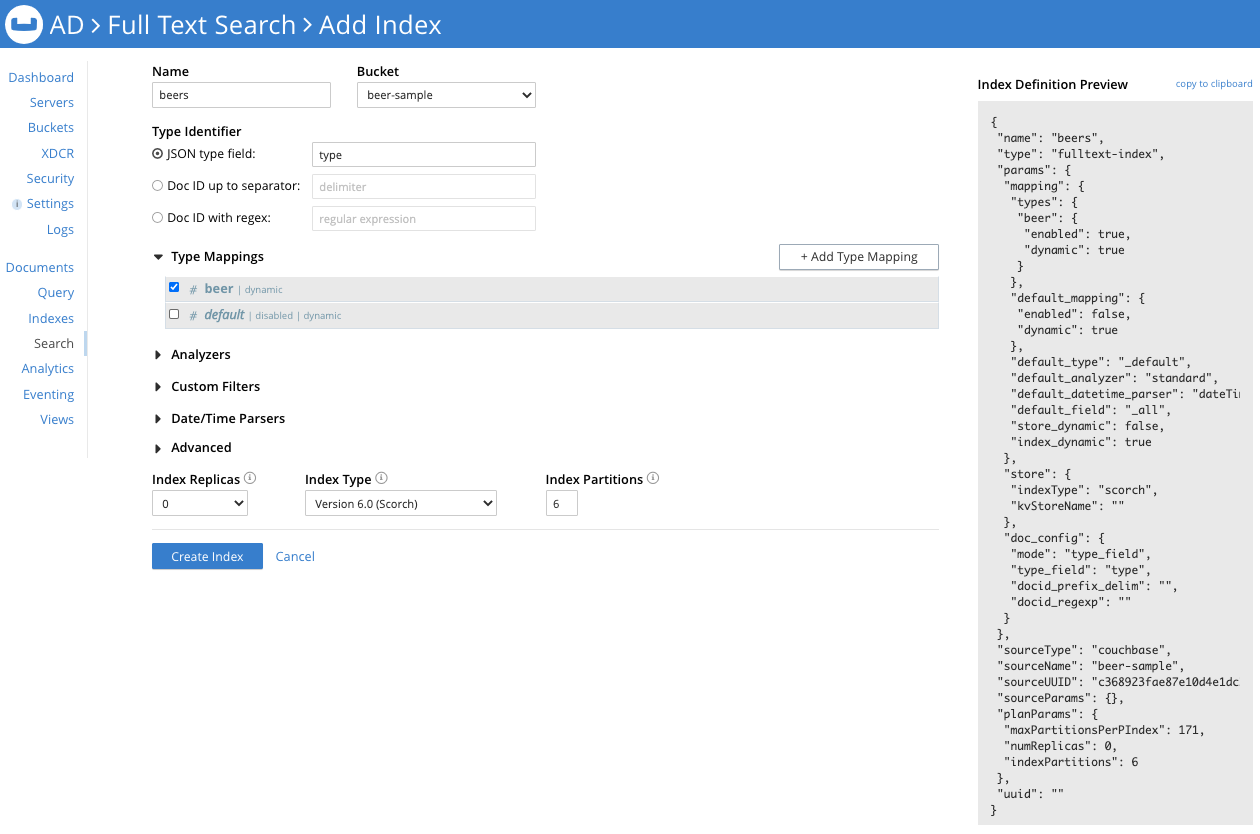
In the screenshot above, I intend to index all the content in the JSON documents from the bucket beer-sample that has a field type whose value is beer. Note the Index Definition Preview on the right side of the screen, which carries all the settings for the index beers. This preview adapts immediately to any changes we make to the settings.
As you can see, there are a lot of settings in the index definition. And Couchbase Server 7.0 includes even more variations to support Collections, which may make it daunting – particularly for new users.
That’s why we’ve introduced the Quick Editor for defining indexes. With it, new users (or anyone who doesn’t want to delve into advanced settings for their full-text search indexes) can get started with Couchbase’s Search Service. Before we dive into the Quick Editor in detail, let’s look at how 7.0 has updated the definition of a full-text index to accommodate Collections. Feel free to jump directly to the discussion of the Quick Editor if you’d prefer.
How Couchbase Server 7.0 Updates Full-Text Index Definitions
Let’s quickly go over updates to the definition of a full-text index in Couchbase 7.0 to accommodate Scopes and Collections. Note that Couchbase will continue to support older index definitions from legacy versions of Couchbase Server.
Let’s continue with the example I used earlier: the beers index on the Couchbase bucket beer-sample. Stripping off the default settings and holding on to only the relevant settings, here’s a minimal index definition for it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "type": "fulltext-index", "name": "beers", "sourceType": "couchbase", "sourceName": "beer-sample", "params": { "doc_config": { "mode": "type_field", "type_field": "type" }, "mapping": { "types": { "beer": { "dynamic": true, "enabled": true } } }, "store": { "indexType": "scorch" } } } |
In 7.0 terms, all that content in the bucket beers-sample resides within the _default Collection of the _default Scope – meaning that when you upgrade Couchbase to 7.0, the data in your bucket moves into the _default Collection within the _default Scope.
The above index definition works with 7.0. Here’s an alternative, though: a 7.0 index definition that does the exact same thing as the one above.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "type": "fulltext-index", "name": "beers", "sourceType": "gocbcore", "sourceName": "beer-sample", "params": { "doc_config": { "mode": "scope.collection.type_field", "type_field": "type" }, "mapping": { "types": { "_default._default.beer": { "dynamic": true, "enabled": true } } }, "store": { "indexType": "scorch" } } } |
Note the three differences between the two definitions above:
-
sourceTypehas changed from couchbase to gocbcore. We’ve changed the underlying SDK that the full-text index uses to communicate with a Couchbase bucket to a newer, better-supported one.params.doc_config.modehas changed fromtype_fieldtoscope.collection.type_field, indicating that the type mapping names now follow that format.- The type mapping name has now become
_default._default.beer, indicating that it indexes documents oftype:beerfrom within the_defaultCollection in the_defaultScope of the bucketbeer-sample.
Collections Help You Model Your Data Better
Modeling your data into a single Collection (mimicking pre-7.0 behavior) means that all the data within the bucket is shipped and the index must filter out documents based on the definition.
With Scopes and Collections, you can model your data into categories – each of which resides in a separate Collection. I’ll highlight one obvious advantage with this approach in the following example.
The beer-sample bucket holds documents of type beer and brewery all residing within the _default Collection of the _default Scope. Let’s change this model:
- Set up a Scope
contentwithinbeer-sample. - Within the Scope, set up two Collections:
beersandbreweries. - Load data of
type:beerintobeersand data oftype:breweryintobreweries.
Here’s an index definition to hold the same data as the earlier ones: ..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "type": "fulltext-index", "name": "beers", "sourceType": "gocbcore", "sourceName": "beer-sample", "params": { "doc_config": { "mode": "scope.collection.type_field", "type_field": "type" }, "mapping": { "types": { "content.beers": { "dynamic": true, "enabled": true } } }, "store": { "indexType": "scorch" } } } |
This time around the bucket ships documents of only type:beer. So with the latest index definition, your search nodes would:
-
- Consume less network bandwidth
- Benefit from faster index build times
Check out this companion blog post for more detail on the nuances of full-text index definitions with Couchbase bucket Collections.
Introducing the Quick Editor
Here’s a peek at the new Quick Editor:
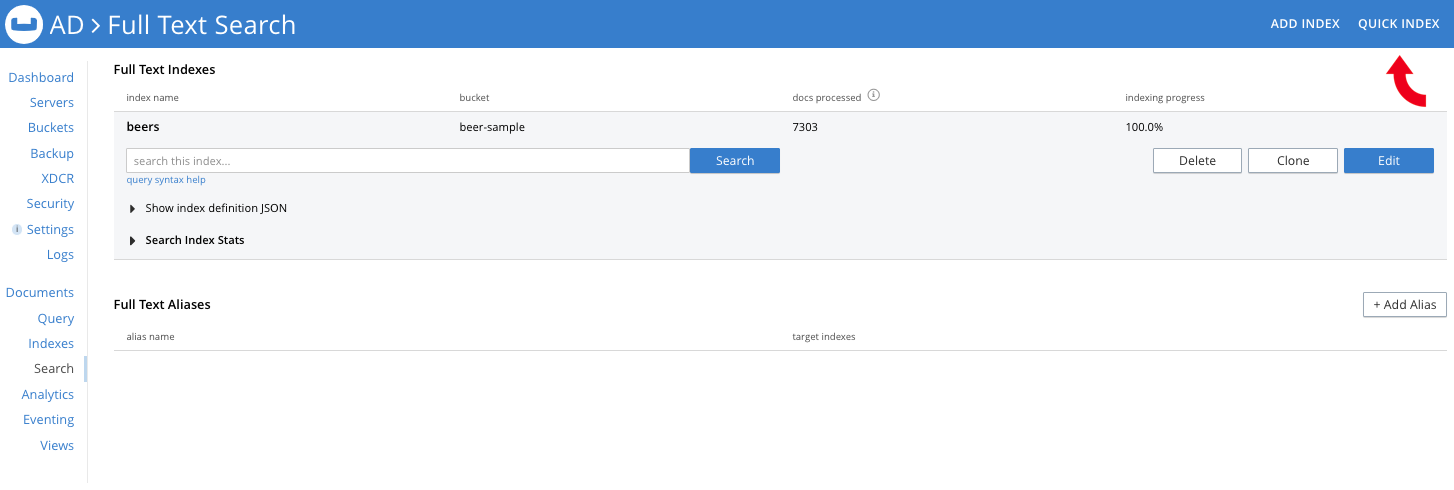
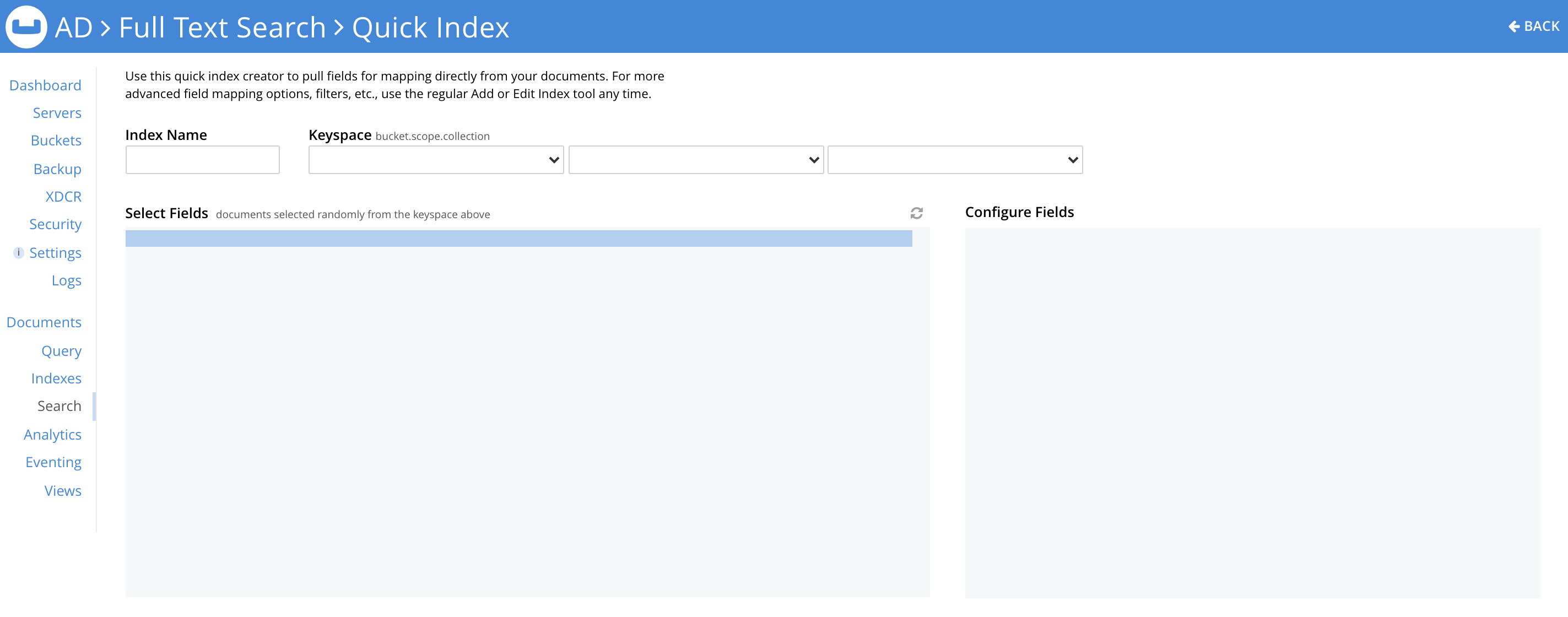
When you select a bucket, Scope and Collection in the Keyspace fields shown in the screenshot, a sample document appears in the Select Fields section; it belongs to the bucket.scope.collection selected. A refresh button in the top-right corner of the Select Fields section lets you iterate through documents (at random) within the Collection.
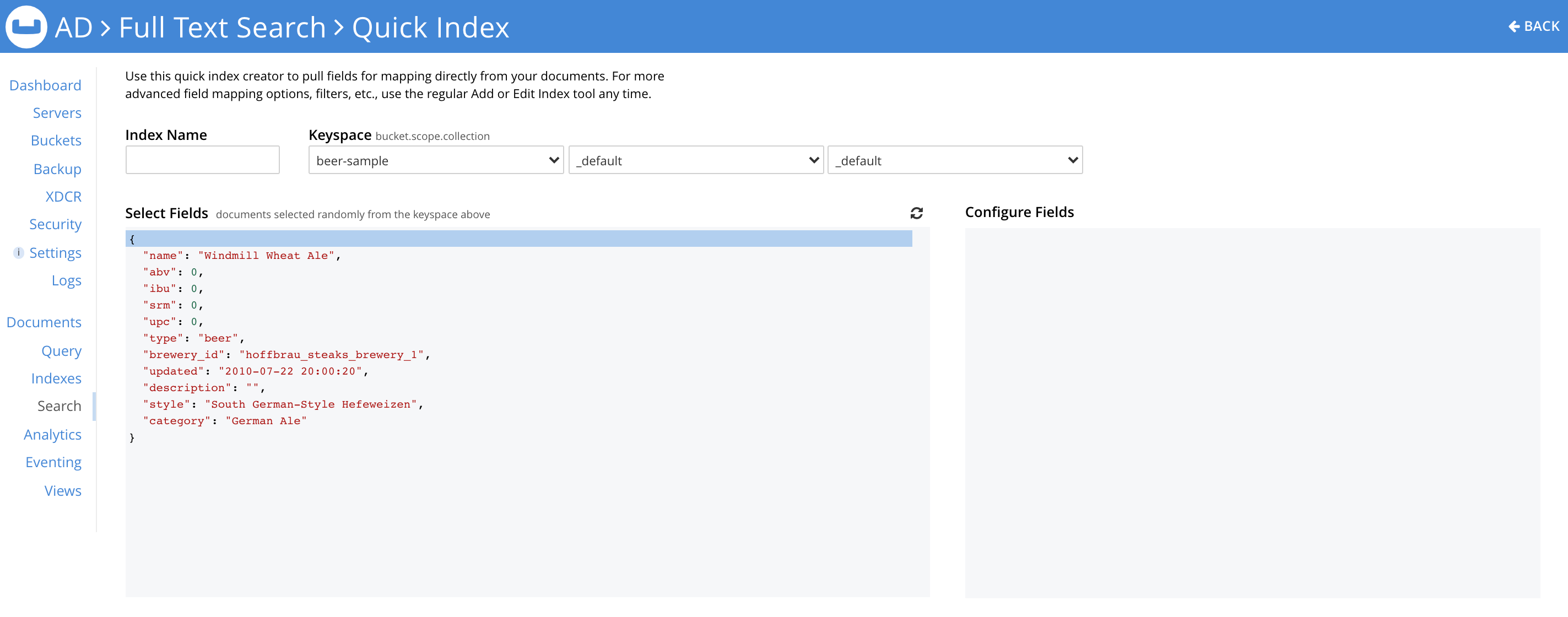
Now you can select a field from the document (by clicking on the field name/value). The selected field shows up for configuration within the Configure Fields section. The type of the field is detected automatically (currently only text, number and Boolean are recognized). If the field were datetime (string in ISO-8601 format) or a geopoint (an object, an array or a geohash), you’d need to explicitly select the type from the Type drop-down.
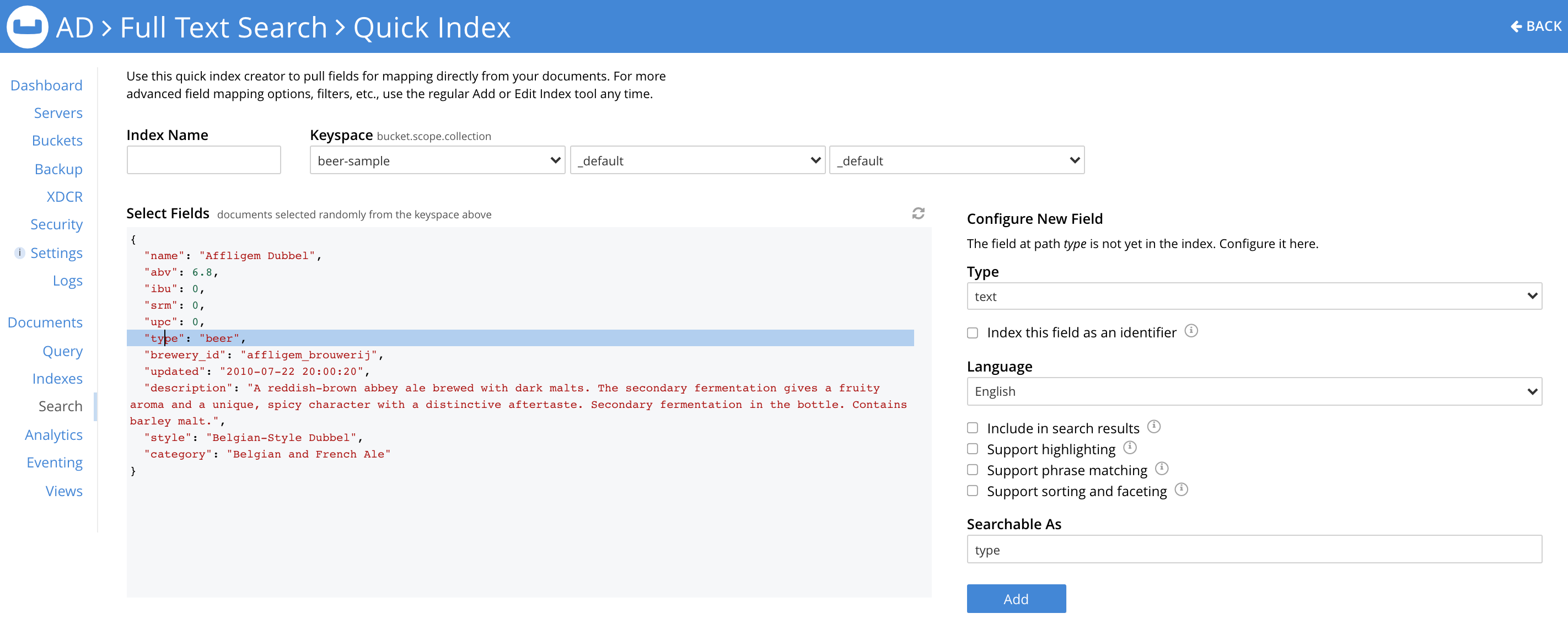
When the configured field is Add-ed, it shows up in the Mapped Fields section, as you can see below. You can edit a mapped field anytime by selecting it again from the Select Fields section or in the Mapped Fields section.
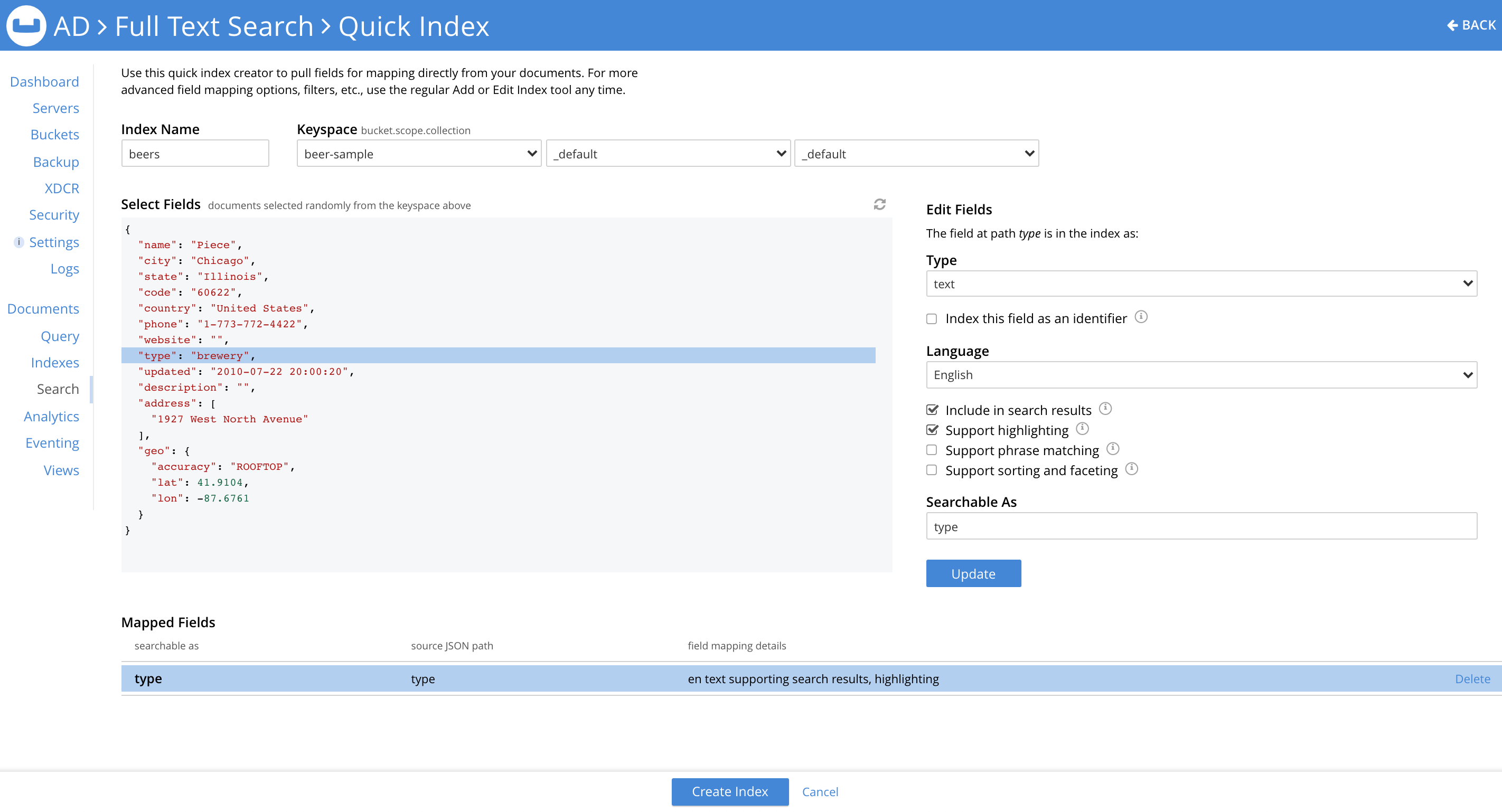
The Create Index button at the bottom of the page lets you create the index.
Here are the available settings for configuring a field:
-
- Type is the type of the field value. Supported types are text, number, Boolean, geopoint and datetime, as detailed above.
- Index this field as an identifier appears only if the chosen field type is text. If selected, this will enforce the keyword analyzer for the text.
- The Language drop-down is available if the field type is text and the field isn’t indexed as an identifier. In the Language drop-down you can choose the analyzer for the text field.
- The next four check boxes essentially translate to a single option or a combination of options (as in the Standard Editor) supported for a field:
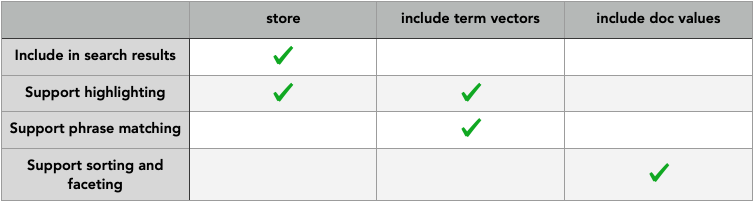
You can find more documentation on these options here.
-
- The last section is for setting Searchable As, which takes a text input that serves as the alias for the field. This setting is optional and defaults to the name of the selected field. During search, the entry in this section is the field to look in.
You can edit an index set up from within the Quick Editor anytime using either the Quick Editor or the Standard Editor.
Limited Options in the Quick Editor
-
- As noted earlier, for simplicity the Quick Editor provides limited options to configure index definitions.
- You can’t index a field that isn’t available in the sample document loaded in the Select Fields section.
- Custom analyzers are not supported.
- Geopoint and Datetime fields are not recognized automatically. You can, however, explicitly set field type upon selection.
- You can’t use the Quick Editor to edit an index created using the Standard Editor. However, you can use the Standard Editor to edit an index created with the Quick Editor.
- While you can set up fields from within multiple Collections, you cannot index the same field multiple times within a single Collection.
- The Quick Editor does not support filtering of documents within a
scope.collection(to just index documents of a certain type). - You cannot set index replicas, index type or index partitions within the Quick Editor. They will assume default values when you create an index. However, you can change these settings using the Standard Editor and subsequently edit the index definition using the Quick Editor as long as the
params.mappingandparams.doc_configsections of the index definition aren’t altered within the Standard Editor*.
*This behavior may change as we extend support within the Quick Editor.
Changes to the Standard Editor
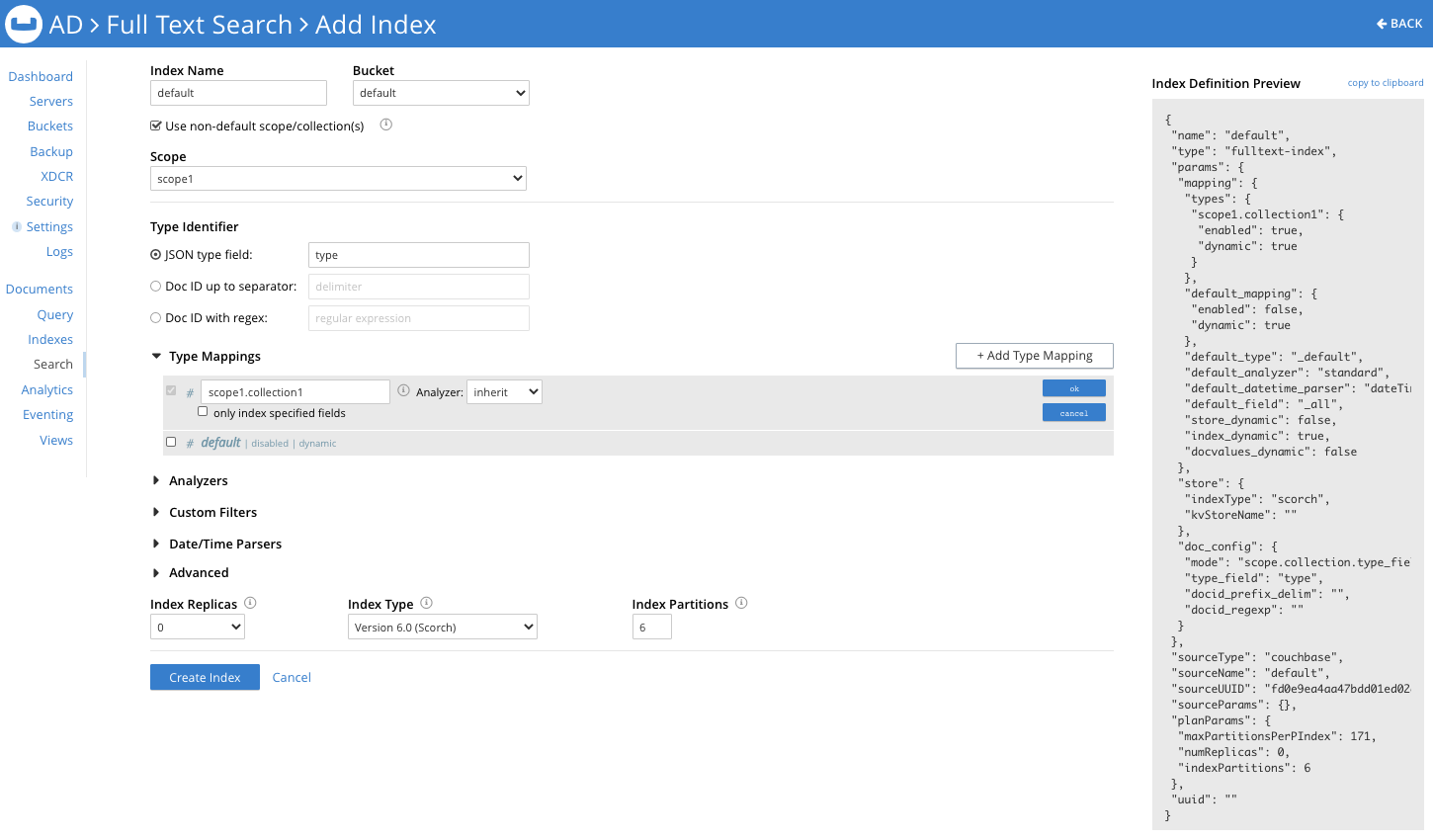
The first thing you may notice that’s different is a new check box under the Index Name and Bucket entries, asking if you’d like to set up the index to subscribe to a non-default Scope or non-default Collection(s):
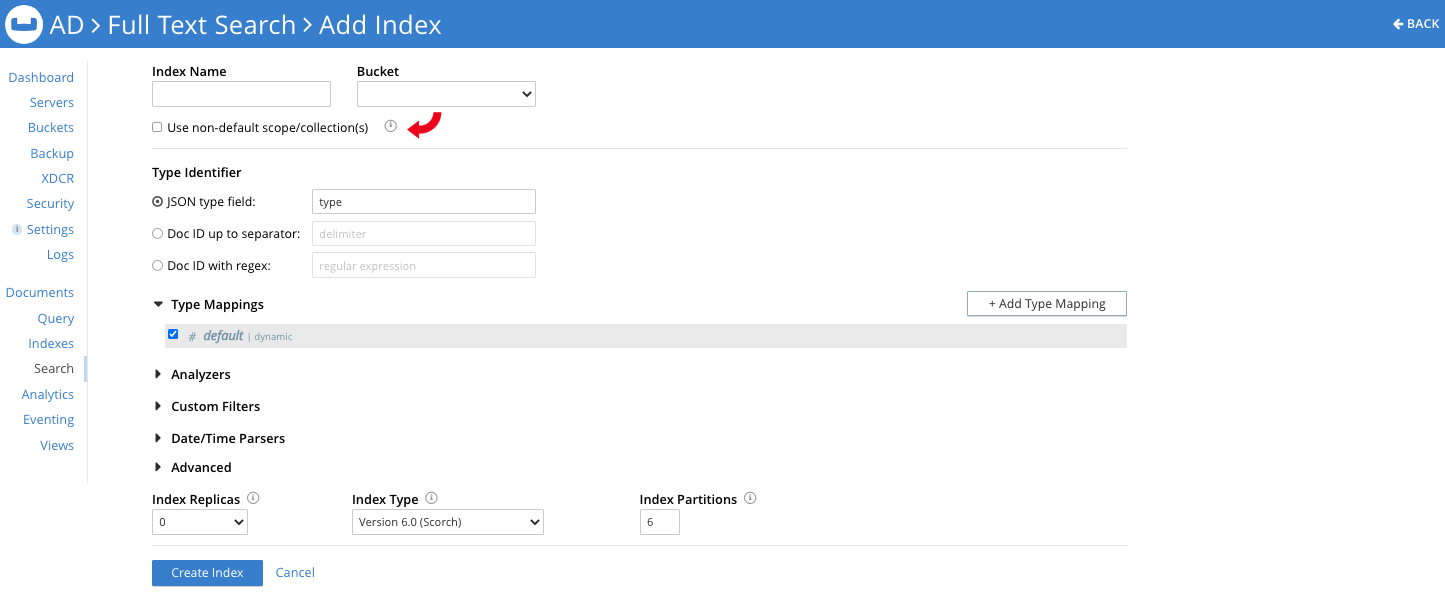
Enabling the check box prefixes scope.collection to the params.doc_config.mode within the index definition, implying that the index can subscribe to one or more Collections from within a Scope. This scope.collection prefix works in combination with the existing settings type_field, docid_prefix and docid_regexp for filtering documents to index.
If you check the Use non-default scope/collection(s) box, a drop-down appears. There you can select a Scope from the available Scopes for the bucket you’ve chosen:
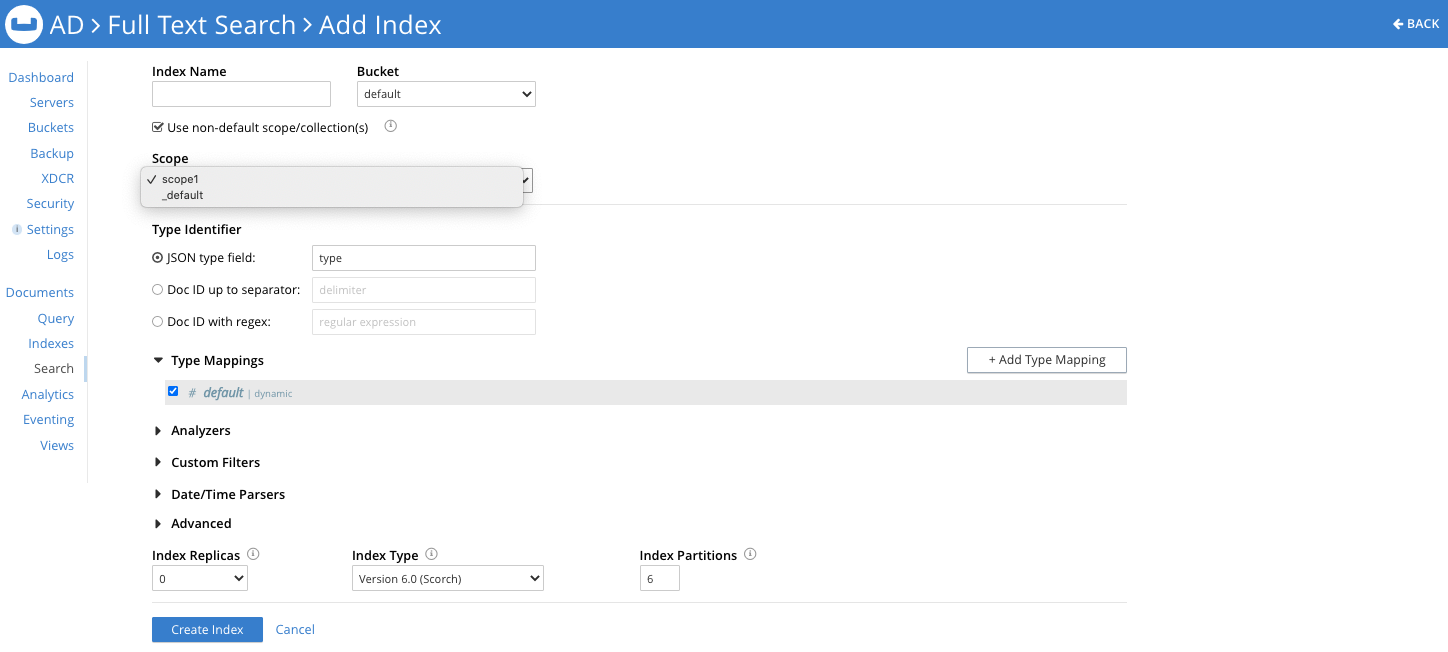
Now within the type mappings, you’ll be asked to select a Collection from a drop-down. (Note that the default type mapping must be un-checked if you choose a non-default Scope selection, because an index definition cannot transcend a Scope.)
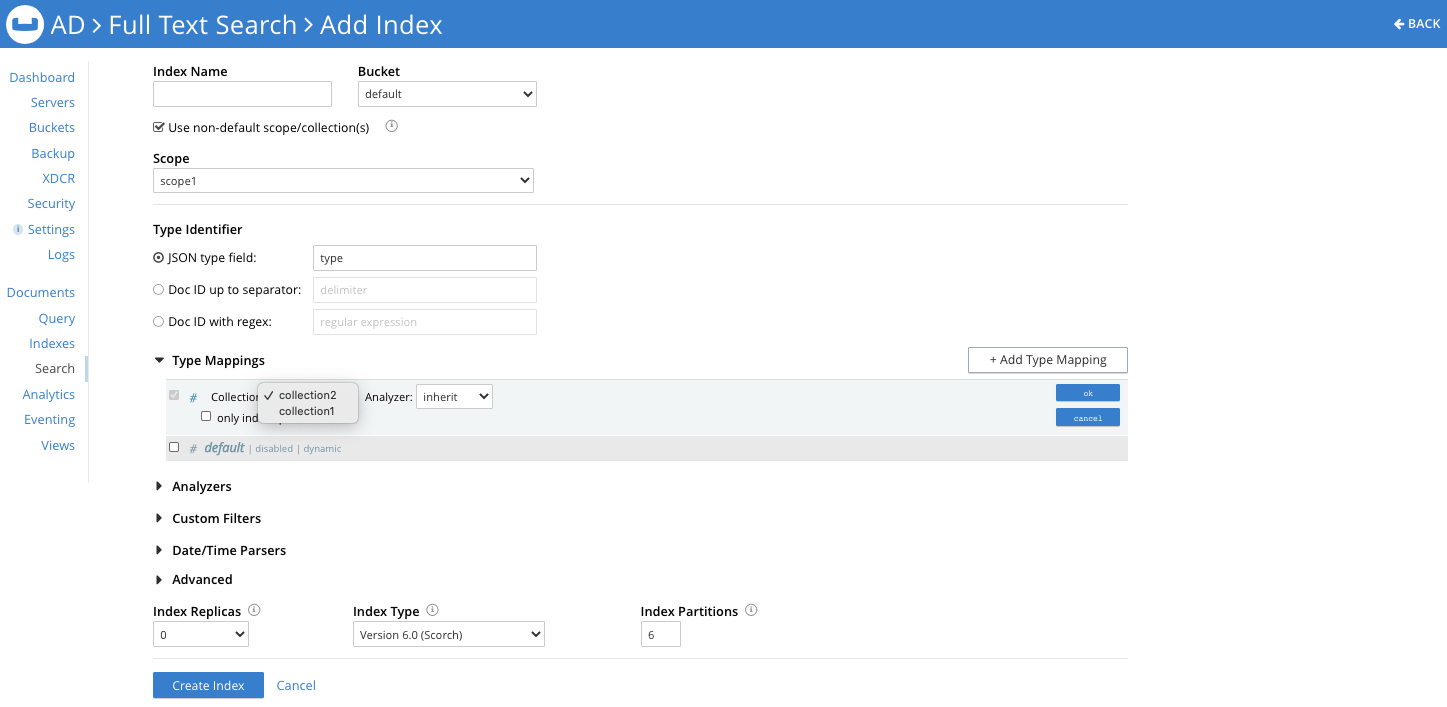
Once you select a Collection, you have the option of appending a type name to the <scope>.<collection> based on the Type Identifier you’ve selected for filtering out documents to index from within the Collection. You can edit this type mapping anytime. And just as before, you can add sub-mappings and child fields within the type mapping.
The rest of the functionality within the Standard Editor remains unchanged.
Searching a Collection-Aware Full-Text Index
The UI for searching within a full-text search index has not changed. The text box supports only a query string. See this documentation page on other types of queries the full-text index supports.
Search requests going directly to the endpoint now take a new argument (optional) to only fetch results from a Collection or a set of Collections that the full-text index subscribes to.
Here’s a sample search request:
|
1 2 3 4 5 6 7 |
curl -XPOST -H "Content-type:application/json" -u username:password http://IP:8094/api/index/index_name/query -d '{ "query": {..}, "limit": 10, "offset": 0, "ctl": {..}, "collections": ["collection1", "collection2"] }' |
On the Couchbase Web Console, however, you can’t set the collections argument for a search request; the request will span across the indexed content of all Collections the index subscribes to.
Let’s consider a sample index definition set up using the Quick Editor. This index subscribes to Collections beer and brewery within the Scope content of the bucket default. Within these two Collections, the name fields are indexed with the following options set:
-
- Include in search result(s)
- Support highlighting
Here’s the relevant content from the index definition:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
{ … "name": "default", "sourceName": "default", "params": { "mapping": { "types": { "content.beer": { "dynamic": false, "enabled": true, "properties": { "name": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "include_in_all": true, "include_term_vectors": true, "store": true, "index": true, "name": "name", "type": "text" } ] } } }, "content.brewery": { "dynamic": false, "enabled": true, "properties": { "name": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "include_in_all": true, "include_term_vectors": true, "store": true, "index": true, "name": "name", "type": "text" } ] } } } } } } } |
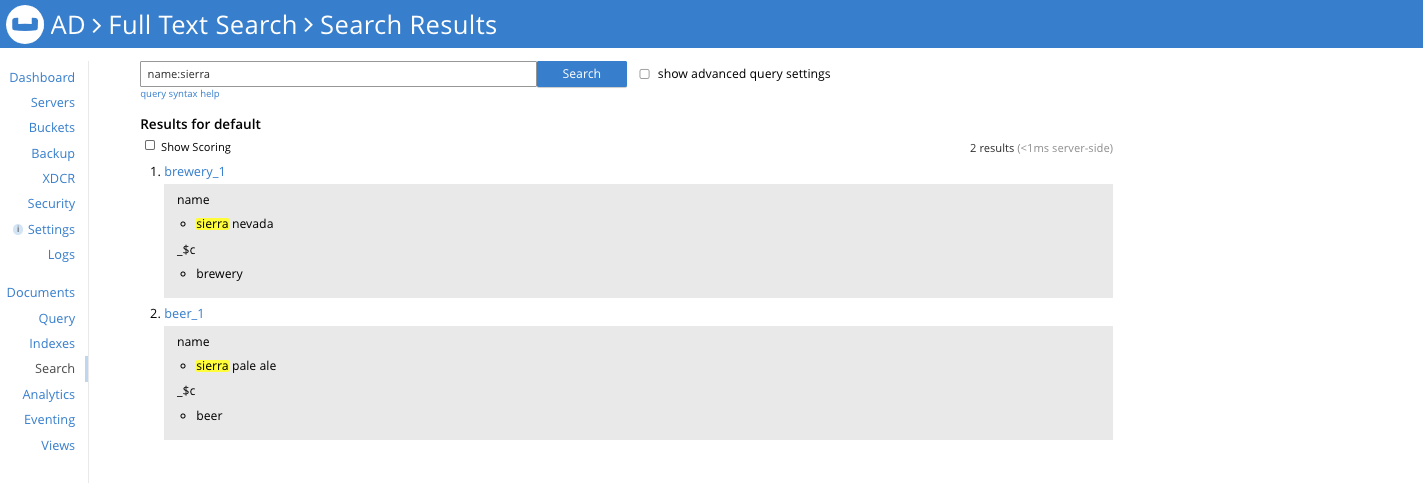
In cases where the index definition subscribes to more than one Collection (like in the example above) for a search, the Collection that the document belongs to appears as a stored field with the key _$c.
Here’s a sample search-results snippet for the above full-text search index definition:
Learn More about Couchbase 7.0
Ready to delve deeper into Couchbase 7.0 and all its features? Check out these resources:
Ready to try out Scopes and Collections for yourself?<br/ >Download Couchbase Server 7.0 today