
About a month ago, Simba Technologies announced that it had released developer previews of the ODBC and JDBC drivers. Last year we announced that Simba Technologies was buiding these ODBC and JDBC drivers for use with Couchbase. These drivers make it possible for data analysts using tools like Microsoft Excel and Tableau to quickly access data on Couchbase Server.
How exactly do you use these drivers? We’re going to look specifically at how to query data using the ODBC driver with Microsoft Excel for Mac and Windows.
Prerequisites
- Couchbase Server 4.0+
- Microsoft Excel 2011+
- A bucket with data
Using with Mac OS X
Start by downloading and installing the latest Simba ODBC driver DMG file for Mac OS. In this article, we’ll be using version 1.0.0.0002 for Mac.
If you’re using a recent version of Mac OS, you’ll need to download another piece of software to configure the just-installed driver. ODBC Manager for Mac will detect the installed driver and allow you to configure what server and port to connect to via Microsoft Excel.
Creating Bucket Indices
Before we connect to Couchbase Server via Excel, we must first create bucket indices to allow for running N1QL queries. With Couchbase Server running, from the Mac Terminal, run the following command:
|
1 |
./Applications/Couchbase Server.app/Contents/Resources/couchbase-core/bin/cbq |
The above will launch the Couchbase query client. For the purposes of this example, we’re going to create a single primary index. With CBQ running, enter the following:
|
1 |
CREATE PRIMARY INDEX def_primary ON `travel-sample` USING gsi; |
The bucket is now ready for N1QL!
Connecting with Microsoft Excel
Launch ODBC Manager and choose either the System DNS or User DNS tabs. Basically whatever meets your needs.
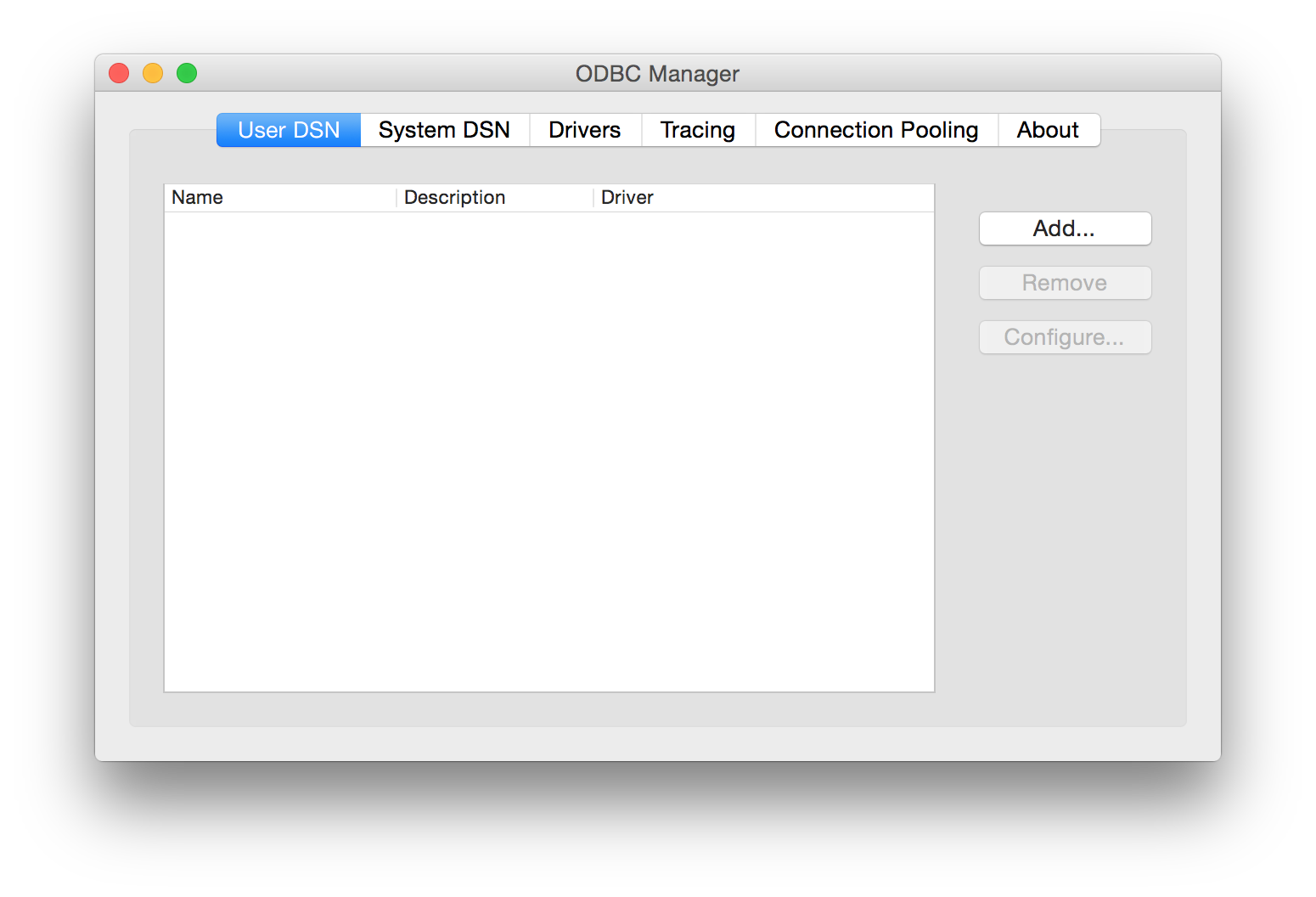
When ready, click the Add button and the Simba Technologies driver should appear in the list to choose from.
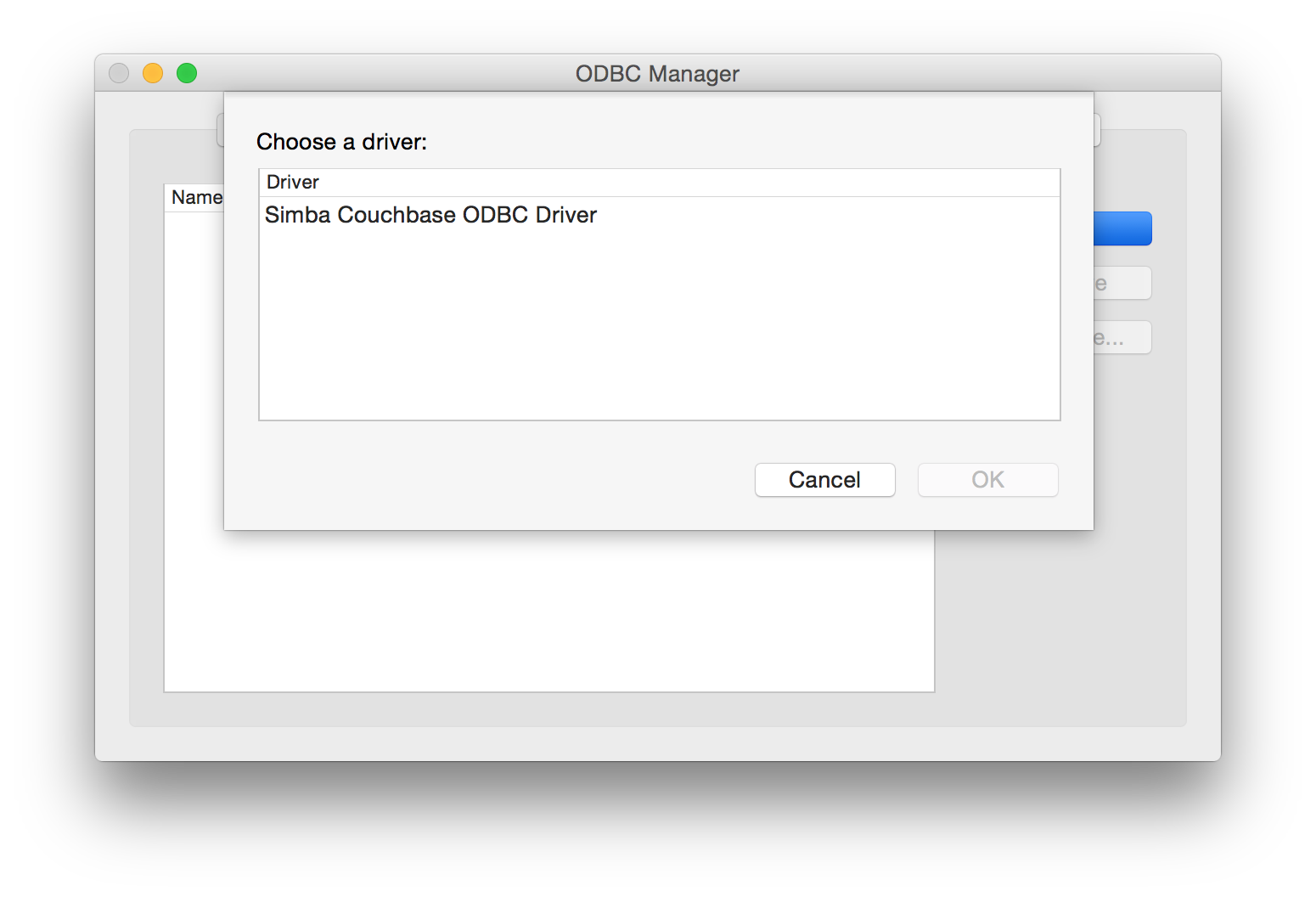
Give the data source a name and add two very important key value pairs:
|
1 2 |
host=127.0.0.1 port=8093 |
Of course, the host should match the actual host that your Couchbase Server resides on. In the above example, Couchbase Server would be running on your local machine.
Create a new Microsoft Excel spreadsheet and click Database from the Data tab. The same can be accomplished by doing Data -> Get External Data -> New Database Query from the toolbar.
When this is done, you’ll get a window that looks similar to what we’ve seen in the ODBC Manager software. If for some reason the previously created driver entry doesn’t show up, go ahead and create it again. Click the Test button and you’ll be prompted to enter a username and password. This is the same username and password used to connect to your Couchbase Server.
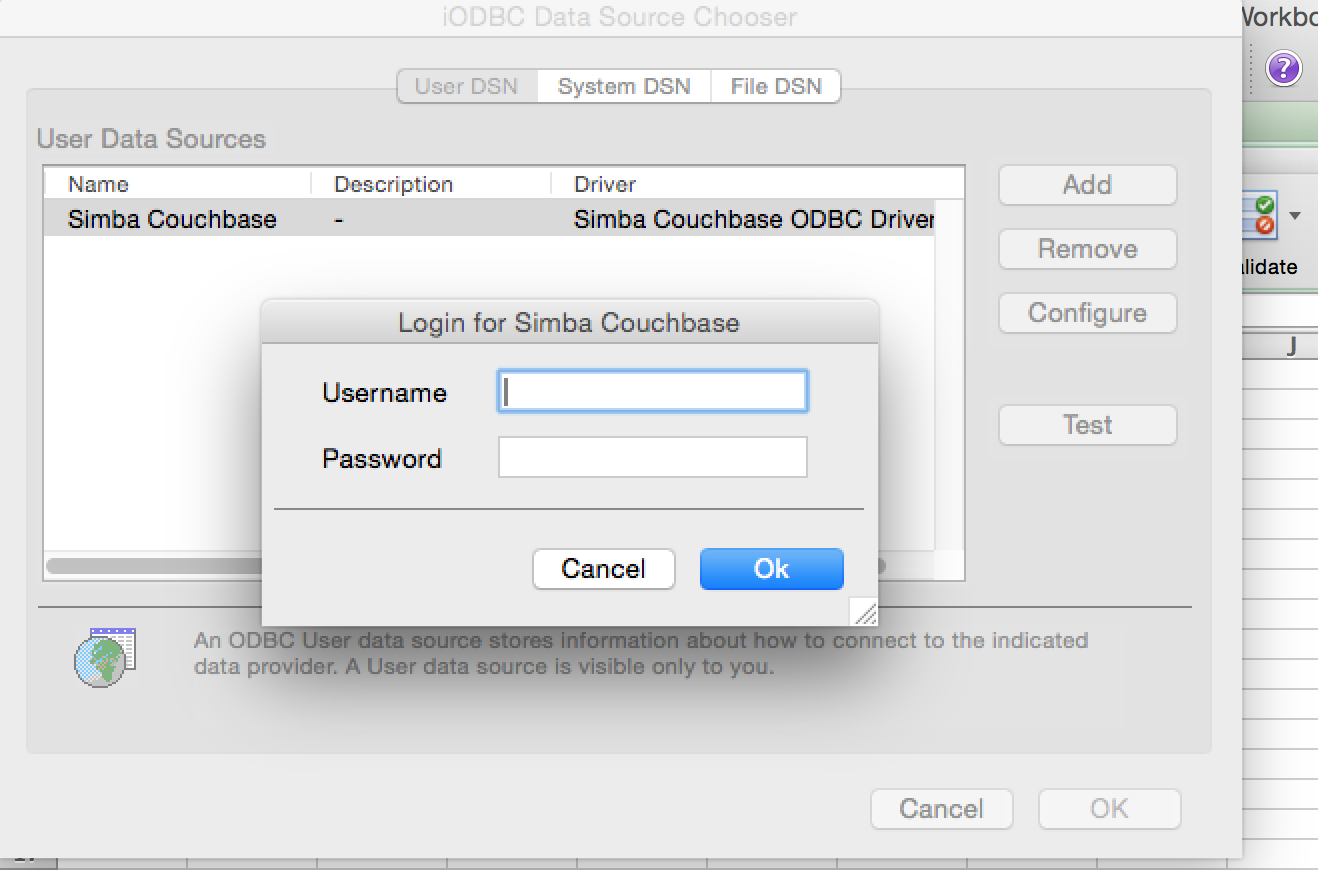
If testing is successful, go ahead and click the Ok button to connect and start analyzing data.
When connected, you should see a list of buckets found on your Couchbase Server. You now have two options for querying data.
Querying Using a N1QL Query
Click the SQL View tab and enter a query of your choosing. Be aware that the more data you plan on returning, the longer it will take to execute. Assuming the travel-sample bucket is installed and has the appropriate indexing configured, enter the following query:
|
1 |
select * from `travel-sample` limit 30; |
If thirty documents exist, they will be returned.
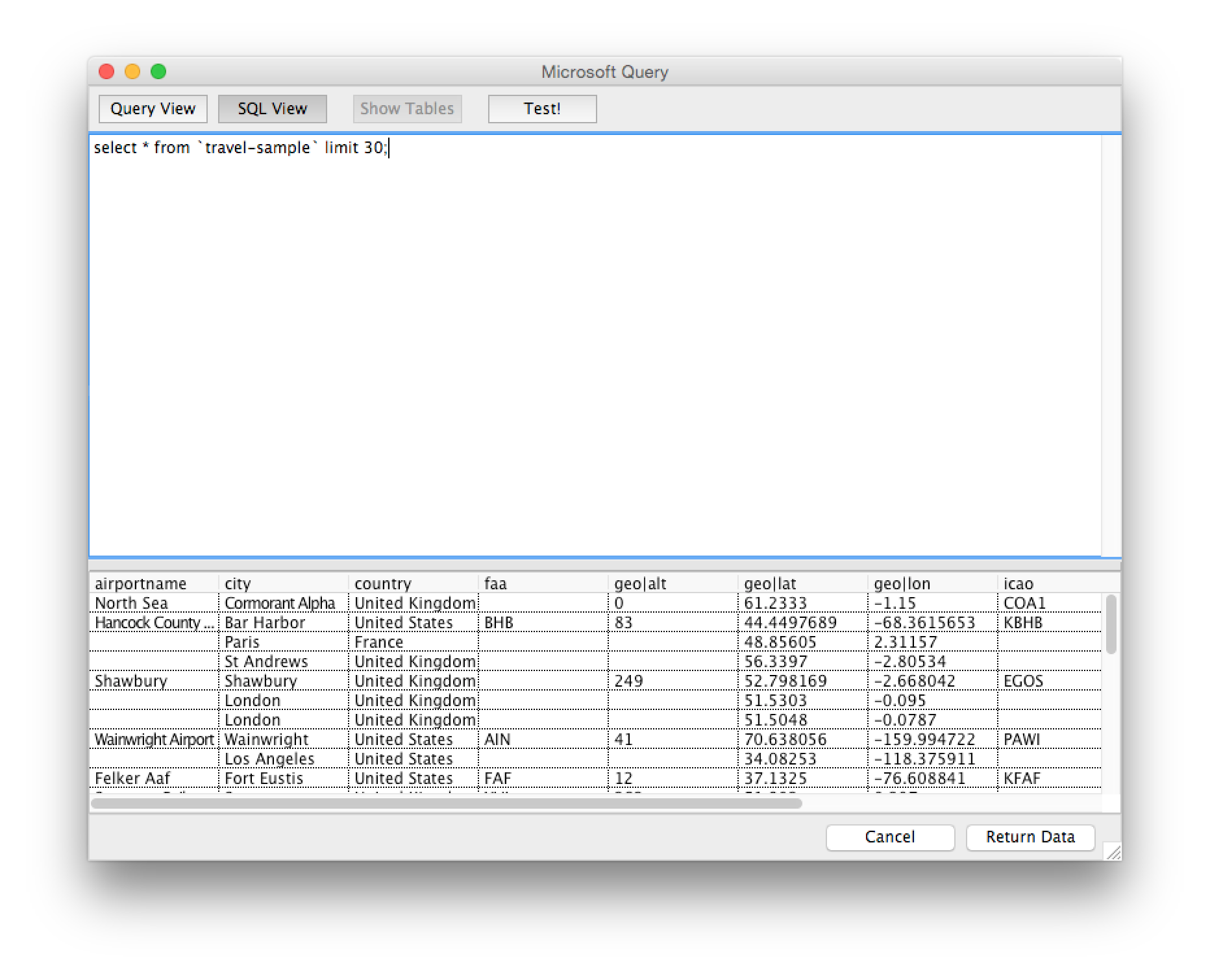
Click the Test button and then click Return Data when the query has finished.
Querying Using the Microsoft Excel Builder
Assuming the travel-sample bucket is installed and has the appropriate indexing configured, select the travel-sample bucket and click Add Table.
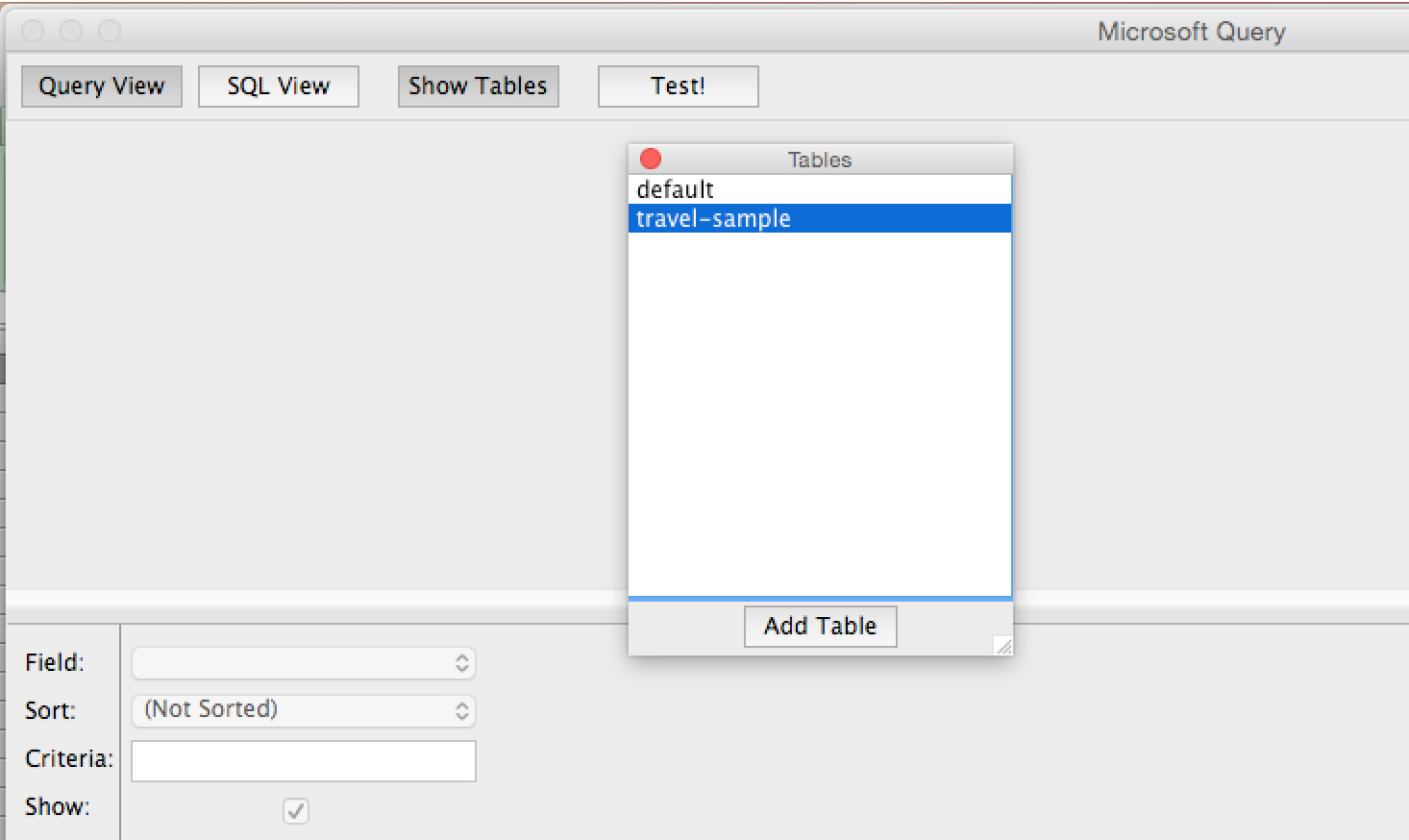
When added, play around with the fields and click Return Data when ready.
Using with Microsoft Windows
Start by downloading and installing the latest Simba ODBC driver MSI file for Microsoft Windows.
Creating Bucket Indices
Before we connect to Couchbase Server via Excel, we must first create bucket indices to allow for running N1QL queries. With Couchbase Server running, from the Windows Command Prompt, run the following command:
|
1 |
C:/Program Files/Couchbase/Server/bin/cbq.exe |
The above will launch the Couchbase query client. For the purposes of this example, we’re going to create a single primary index. With CBQ running, enter the following:
|
1 |
CREATE PRIMARY INDEX def_primary ON `travel-sample` USING gsi; |
The bucket is now ready for N1QL!
Create a new Microsoft Excel spreadsheet and click From Other Sources from the Data tab. If your datasource hasn’t already been added, choose the option and you’ll be required to fill out four items.
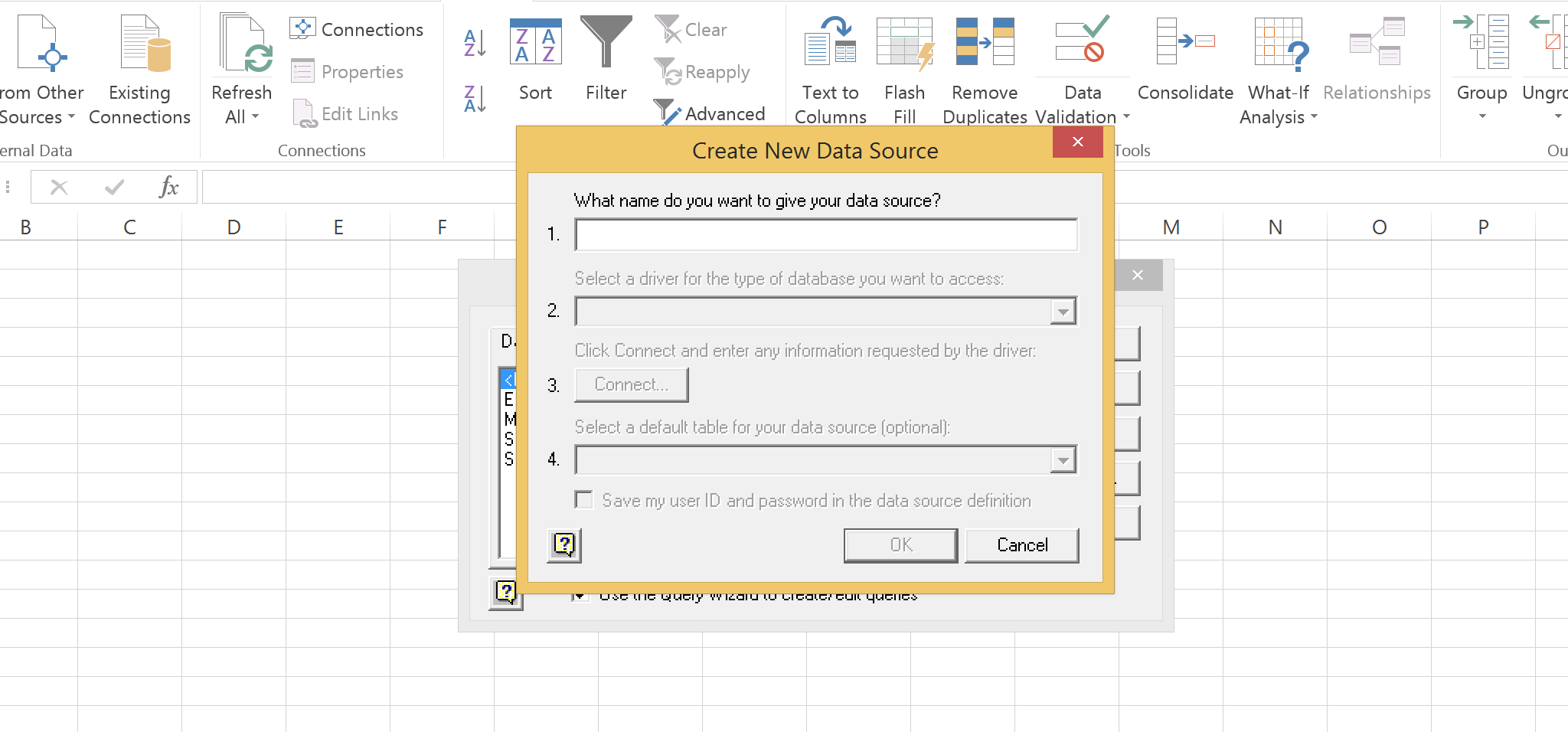
- Name your connection something like
Simba Couchbase - Choose the Simba Couchbase ODBC Driver
- If Couchbase Server is running locally, use
127.0.0.1otherwise enter the IP of your remotely running server. The defaults for everything else is fine - Choose a default table for the datasource if testing the connection is successful
At this point you can proceed to following the query building wizard or click cancel to do things on your own.
Querying with the Wizard
With the wizard started, first add the desired columns to your query, or all of them and click Next.
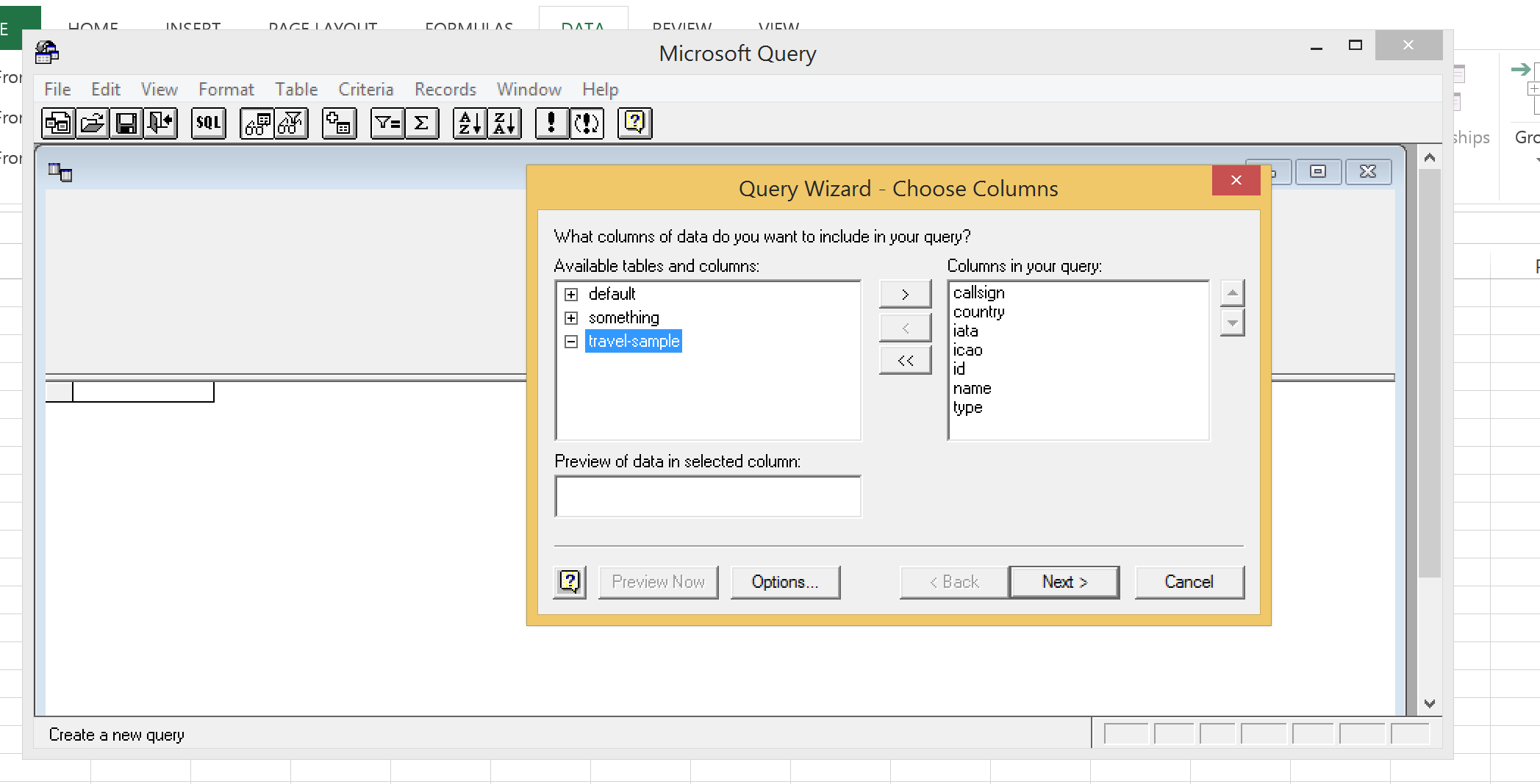
The next screen of the wizard will let you add any query logic. If you want to return all rows, just leave the default and click Next.
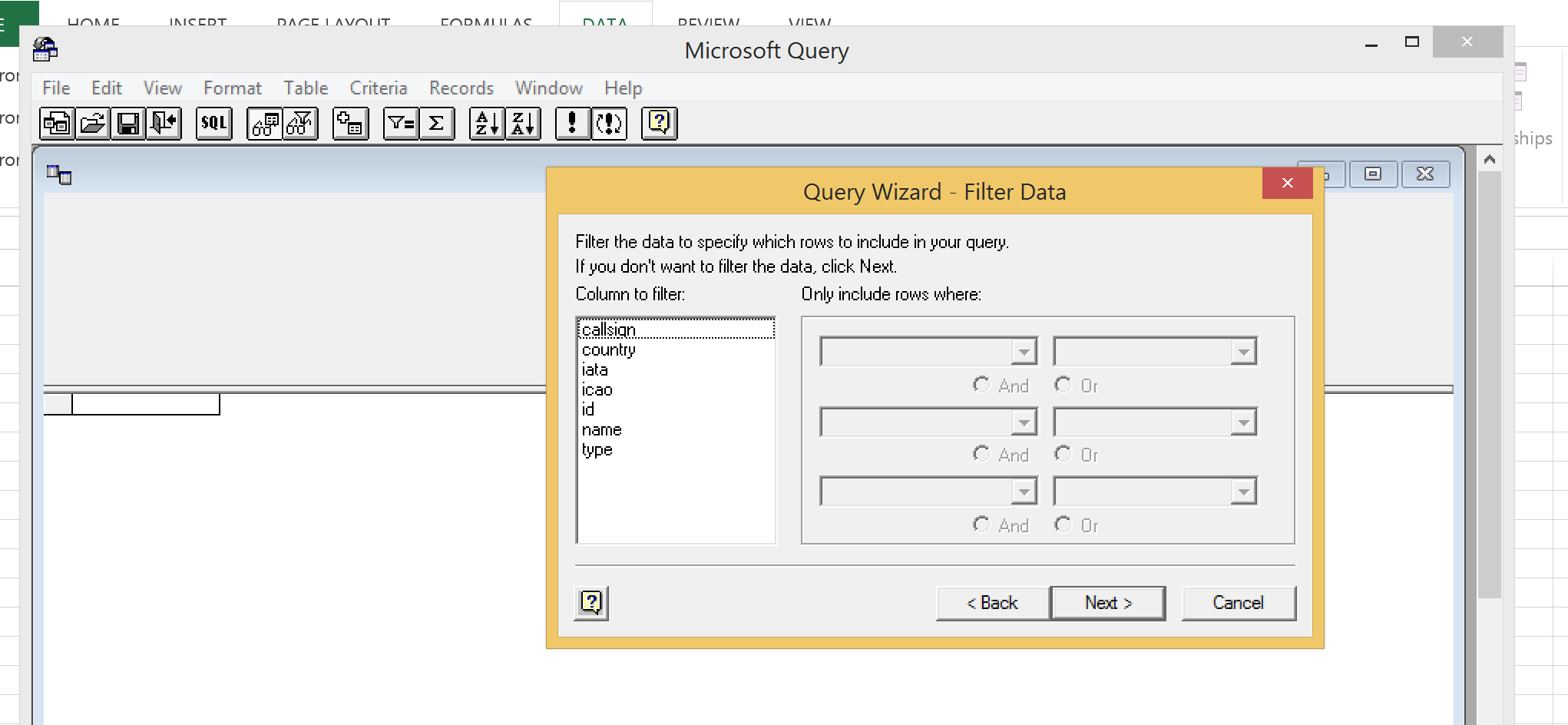
The next screen of the wizard will let you choose how to sort the data by default. You can choose the default and click Next or specify some sorting.
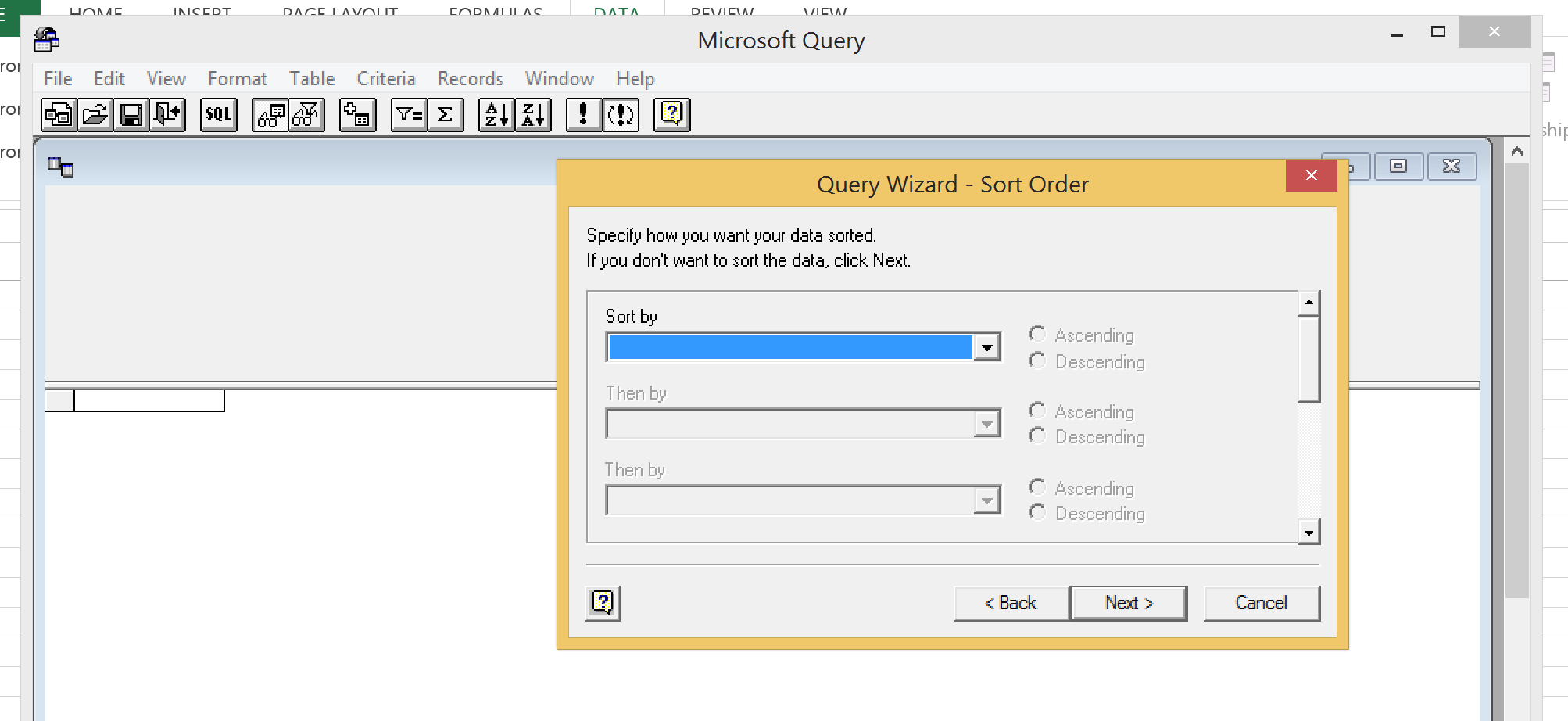
Choose Return Data to Microsoft Excel and click Finished.
All data based on the criteria entered will be pulled into the spreadsheet.
Querying Using a N1QL Query
Click the SQL button and enter a query of your choosing. Be aware that the more data you plan on returning, the longer it will take to execute. Assuming the travel-sample bucket is installed and has the appropriate indexing configured, enter the following query:
|
1 |
select * from `travel-sample` limit 30; |
If thirty documents exist, they will be returned.
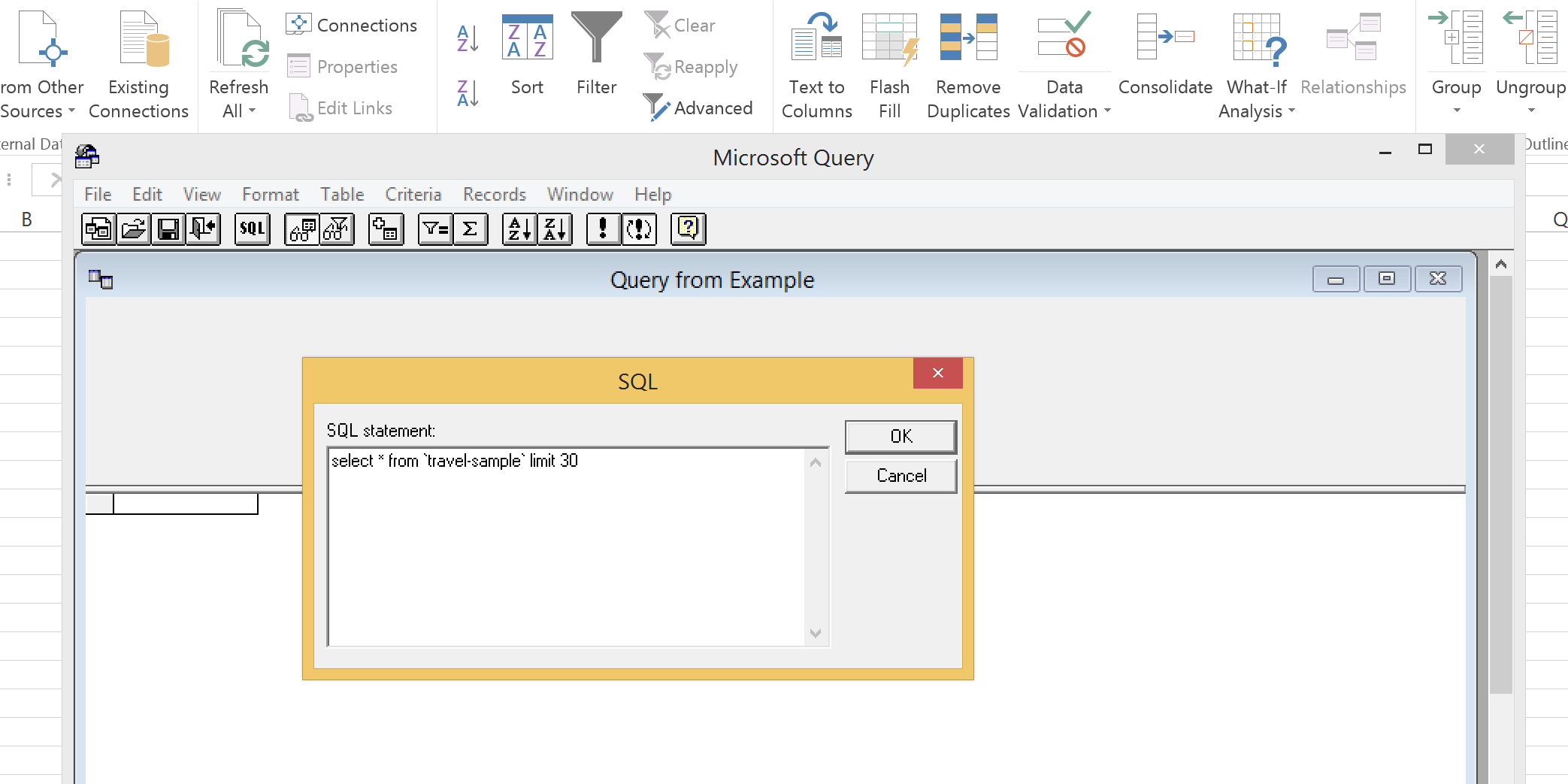
Click File -> Return Data to Microsoft Excel when the query has finished to return the data into your spreadsheet.
Thanks for the great tutorial, Nic! One correction: you should use \’server\’ key instead of the \’host\’ key to specify the hostname on which your Couchbase runs. Other keys and possible values are listed in the Driver Install Guide bundled with the driver. Thanks!
Thanks for the feedback!
Would you mind sharing the driver installation guide that you found? I didn\’t see one for this particular driver, but it may have slipped past me.
Best,
The Guide is installed along with the driver to \’/opt/simba/couchbaseodbc/Simba ODBC Driver for Couchbase Install Guide.pdf\’. You can also download it separately from the download location mentioned on Simba\’s blog:
My assumption is that is a Mac OS path. On my Mac, the path doesn\’t exist. Options for me are as follows:
/opt/simba/couchbaseodbc/ErrorMessages/
/opt/simba/couchbaseodbc/Setup
/opt/simba/couchbaseodbc/Tools
/opt/simba/couchbaseodbc/lib
None seem to take me to any PDF files. What version of the driver did you install? Also, I\’m not sure if your link was cut off in regards to the blog post. I didn\’t see a link on any of the blog posts that I\’ve found that point towards a guide.
Thanks for all your feedback. It is much appreciated as it will definitely help future readers :-)
Best,
Yes, it\’s the full Mac OS X path to the PDF file. The Guide should be in \’/opt/simba/couchbaseodbc/\’ directory (at the top level). I used the current version of the driver referenced in Simba\’s blog (v.1.0.0.0004). The Guide is also available from this link: https://simba.app.box.com/s/fm…
Just wondering if it is possible to query Couchbase Views instead of Table/Bucket from Excel? Could you please show how if possible? Thanks
You can only issue N1QL based queries through the ODBC/JDBC drivers and N1QL does have access to views created through N1QL CREATE INDEX statement. However you cannot query any map-reduce view created through the view API with ODBC/JDBC at this point.
thanks
Thanks for the quick reply. Is there any example on how it is done using N1QL CREATE INDEX?
CREATE INDEX index_name ON bucket_name(…) USING VIEW;
I mean where to actually write this statment? When I create View I go to Couchase such as http://localhsot:8091 – Views – then Create Development Views. Where can I write N1QL in Couchbase? Thanks
A few links that may be helpful;
– You can use a tool called CBQ if you\’d like to do this through the commandline: http://docs.couchbase.com/4.0/…
– CREATE INDEX syntax : http://docs.couchbase.com/4.0/…
we are looking to add more graphical tools in upcoming versions for N1QL queries.
thanks
-cihan
I am still bit loss. When I use Create Index via CBQ, am I creating a View? or am I querying the View I already created?
Once that Index is created in CBQ, how do I then access it in Excel?
Sorry really new to this.
Just to make it clear.
Do I execute following in CBQ:
CREATE INDEX
beer-sample-type-indexONbeer-sample(type) USING GSI;Then, Do I access it from Excel like this?
SELECT * FROM system:indexes WHERE name=\”beer-sample-type-index\”;
Thanks again.
I think I understand now. Index is just like SQL Server indexes – just performance related. I was confused when you said \”views created via N1QL CREATE INDEX\”.
However, it is not really a view as such as I cannot query it this way:
SELECT * FROM \”beer-sample-type-index\”
If so, I don\’t think INDEX would help cause reason I am using views is my json files are very complex and have lots of nodes – I need to flatten it and store it as Views, so I can query them easily in Excel.
Am I correct? Thanks
To recap: cbq is a command line tool for you to pass in any N1QL statements. CREATE INDEX or SELECT all work through cbq command line tool. You can use all these through excel too but you will need to download a separate ODBC driver for that.
Flattening can be done through N1QL statements (see unnest for example). so you can write statements to help flatten the items before you expose them to excel.
Simba owns the ODBC driver. I\’ll ask Simba folks to comment on the ODBC driver flattening capabilities as well on this post.
As Cihan has said, N1QL isn\’t able to query the type of views you\’re talking about (created through the admin console). As such, the ODBC driver does not have access to them either. In the Beta version of the driver, you can issue N1QL queries using the UNNEST operation to get a result set that looks like what you want.
If you don\’t unnest, the driver will attempt to do this for you when it receives the result. For example, if you SELECT * FROM
beer-sampleWHEREtype=\’brewery\’, you will see several columns resulting from flattening in the driver: \”geo|accuracy\”, \”geo|lat\”, \”geo|lon\”, and \”address[0]\”. You may notice that this only has one column for address but a few documents have two entries in their address array. This is because the result structure is based on the first document seen. For this reason, if you\’re going to issue direct N1QL queries, it would be advisable to UNNEST ahead of time.Things are getting better though. The full release of the ODBC driver coming up will have a feature to present a renormalized view of your data as virtual tables representing different parts of your documents. You can then use standard SQL to query your data from a variety of SQL capable tools. Continuing with beer-sample as an example, you will have three tables: beer, brewery, and brewery_address. The three geo columns mentioned above remain part of the brewery table, but the address attribute gets given its own table with a key column that can be joined against the associated key column in the brewery table.
And it isn\’t just limited to simple arrays of strings like the address array of beer-sample. In travel-sample, we get a route_schedule table with columns for the three parts of the schedule objects: day, flight, and utc. And again, this can be joined to the route table by a key column in each table.
This renormalization process is also customizable. If you don\’t want brewery_address to be its own table but prefer to have address[0] and address[1] columns in your brewery table, you can edit the definition of the brewery table to add those columns.
Has anyone had any success with open office on the Mac. I can make the connection ok, using an odbc connection and an open office database, but running a query just hangs then crashes.
What happens if you limit the query to a smaller result set?
Cdata Software has developed The Couchbase Excel Add-In, which is a powerful tool that allows you to connect with live Couchbase NoSQL databases, directly from Microsoft Excel. Use Excel to read, write, and update Couchbase. Perfect for mass imports / exports / updates, data cleansing & de-duplication, Excel based data analysis, and more!
https://www.cdata.com/drivers/couchbase/excel/