
If you have any familiarity with Couchbase, you definitely know XDCR. If you use Couchbase for any of your applications, you are very likely using XDCR. I wouldn’t be wrong if I said, XDCR is indeed one of our customers’ most loved products. If you are now interested in learning what makes XDCR so awesome, you are in the right place, please continue reading. In contrary, if you have no idea about what am saying, well this is your opportunity to learn about it.
Replication is the key to the effectiveness of distributed systems to provide enhanced performance, high availability and fault tolerance. XDCR is a highly performant replication technology used to replicate data between two Couchbase clusters. This is complementary to the intra-cluster replication. XDCR provides asynchronous replication and maintains data consistency across sites via eventual consistency.This implies, as soon as a single copy of mutation is executed, acknowledgements are sent to the applications and eventually data becomes consistent across different clusters in the topology.
Core principles behind this technology
- Highly performant : XDCR is highly performant replication system operating at the speed of network and memory with very low latency. Replication is memory to memory.
- Independently scalable system : XDCR has a peer to peer architecture where clusters can be added or removed and every cluster in the topology can be scaled up or down without impacting other clusters.
- Infrastructure agnostic : XDCR can be used to replicate data between any two couchbase clusters irrespective of their deployment platform as bare metal, VMs, private cloud, public cloud, hybrid or containers.
- Topology aware : XDCR is topology aware, as nodes are added to / removed from clusters, system adjusts and manages replication accordingly, without any manual intervention.
- Simplified setup and administration: XDCR can be set up in <15 secs, between any two Couchbase clusters. Once set up, the documents are continuously synchronized between source and target. It operates without any manual intervention even during topology changes like failover or rebalance.
- Flexible topology : Unidirectional, bidirectional, hub & spoke, ring, mesh etc., any complex topology can be set up.
- Resilient : Incase of any network failures, XDCR can resume replication from where it was interrupted. XDCR also continuously retries until the replication is successful.
XDCR under the hood
To familiarize yourself with Couchbase server architecture, please listen to this talk.
In this blog, we shall focus on XDCR architecture.
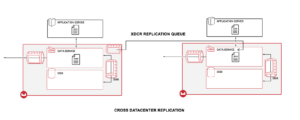 To describe the flow at a high level, the application data from the app server is written to our built in memory (cache) through the client SDKs. Once this data is in memory, it is channelized into different queues for replication and persistence. The inter-cluster replication happens between memory to memory as indicated in the fig above.This is one of the major factors which enable XDCR to provide very low-latency.
To describe the flow at a high level, the application data from the app server is written to our built in memory (cache) through the client SDKs. Once this data is in memory, it is channelized into different queues for replication and persistence. The inter-cluster replication happens between memory to memory as indicated in the fig above.This is one of the major factors which enable XDCR to provide very low-latency.
Also, the replication is highly parallel between nodes in the source and target. The replication queues can be tuned between 2-100 depending on the availability of bandwidth and desired performance.
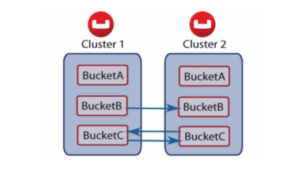
Buckets in Couchbase are logical containers for documents. XDCR can be set up at the bucket level. Each bucket is divided into 1024 virtual buckets called as vbuckets. These vbuckets are split equally among the nodes in each cluster. Each of these nodes end up with some active and some replica data. XDCR decentralizes replication among these nodes in the cluster.
Couchbase maintains a streaming protocol called as “Database Change Protocol (DCP)” to communicate the state of data using an ordered changelog. XDCR is a consumer of this protocol and relies on DCP to propagate changes.
An XDCR replication queue maintains the XDCR specific changes. XDCR worker threads pick up the changes for the given active vbucket on the node and communicate the changes to the remote node that maintains the active vbucket at the destination cluster. The architecture does not require any centralized coordination for replication of each vbucket which factors in the low latency and high throughput characteristics. The number of worker threads can be configured to maximize the throughput depending on available bandwidth.
XDCR maintains checkpoints. Whenever the replication is interrupted due to network failures or source cluster failover etc., XDCR resumes replication from the last checkpoint. If for some reason its unsuccessful, XDCR keeps retrying until it’s successful. Replication also happens in two modes pessimistic replication where only the keys are replicated and optimistic replication where both keys and values can be replicated.
XDCR is also highly optimized for bandwidth conservation via features such as compression, network throttling and optimistic replication where you can compress the documents for replication, restrict the bandwidth utilization and choose to replicate the documents with optimistic replication upto a certain threshold for reduced latency.
Hope this first part of Understanding XDCR series has given you a good overview of what is XDCR, how it works and what makes it such an efficient replication system.
Stayed tuned for the following parts where we will learn more about its features, benefits, applications, performance tuning and much more!
If there is a specific topic you are interested to learn more about, please add it in the comments.
Hi Chaitra,
In a hub & spoke model, if we have 2 hubs (with bi-directional replication between both) then should both hubs send changes to the spokes?
If yes, then there is duplicate replication from hub to spoke. This is sub-optimal.
If no, i.e. only one hub replicates to the spokes, then the challenge is that when that hub is down, it will need manual intervention to configure replication from the other hub to the spokes.
Can you suggest if there is a way to inform/configure XDCR such that if a hub receives changes from other hub then those should not replicate to the spokes but if it receives changes from the application then those should be replicated to the spokes. If yes, then we can configure uni-directional replication from both hubs to the spokes and the hub that receives changes from the application will replicate those changes to the spokes but the other hub will not. If the hub receiving changes from application goes down, other hub starts receiving changes from the application and it starts replicating those to the spokes.
Thanks
> then should both hubs send changes to the spokes?
> If yes, then there is duplicate replication from hub to spoke. This is sub-optimal.
One hub cannot assume that since another hub has sent a replication to a spoke, that the spoke has received it. Duplicate replication is avoided by DCP.