
The Basics
Before you read any further, please take a few minutes and read the excellent post on geospatial search in Couchbase, as published by my friend and colleague Brian Kane: https://www.couchbase.com/blog/geospatial-search-how-do-i-use-thee-let-me-count-the-ways/
Go ahead; I’ll wait.
Now that you’re back, you will know that one great way to leverage Couchbase’s full text search engine is to pass to it a series of vertices which identify a polygon (usually irregular) describing a geographic region. Brian’s example uses ten pairs of lat/long points:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"polygon_points": [ "35.987374, -83.658937", "35.971769, -83.654212", "35.887168, -83.793874", "35.686403, -83.678068", "35.704374, -83.505435", "35.769145, -83.275637", "35.868423, -83.290819", "35.919168, -83.350486", "35.948053, -83.510420", "35.990925, -83.568382" ] |
These points roughly bound a region in Tennessee, south of the highway, north of the National Park Boundary, and within a single county…good enough for the required analysis, and easy to paste into your request. Given these, the Couchbase full text search (FTS) index engine can easily return all of the required data elements associated with points inside (or outside) the perimeter. (Brian gives a great example of this in his post.)
The Wrench (or Maybe, the Wrench-shaped District)
But what if your polygonal region is extremely detailed and complex, maybe requiring thousands of pairs of lat/long points to describe? Do we have ready examples of these? Yes! Thanks to the hard work of the fifty State Legislatures and/or their surrogates, we have plenty of examples of regions like this in the form of U.S. Congressional districts. And thanks to Couchbase N1QL and FTS geospatial search, we have the means to manage the data with ease.
The average U.S. Congressional district requires 8,694 vertices to define it. Reasons for this are both practical (all of them are expected to comprise approximately the same number of citizens), political (the parties in power may contort district boundaries in such a way that the voters there will keep them that way–this is called gerrymandering) and geographical (a lot of them are based in part on rivers, lakes, ocean shores, mountains, and other natural boundaries). The most geographically complex district (i.e. the one requiring the largest number of vertices to describe) is the 5th Congressional District of Virginia, which takes a whopping 40,145 lat/long pairs to describe (and looks like a reverse T. Rex rampant). The simplest, requiring only 422, is the 36th Congressional District of New York, which looks like a submarine sneaking away from Lake Erie.
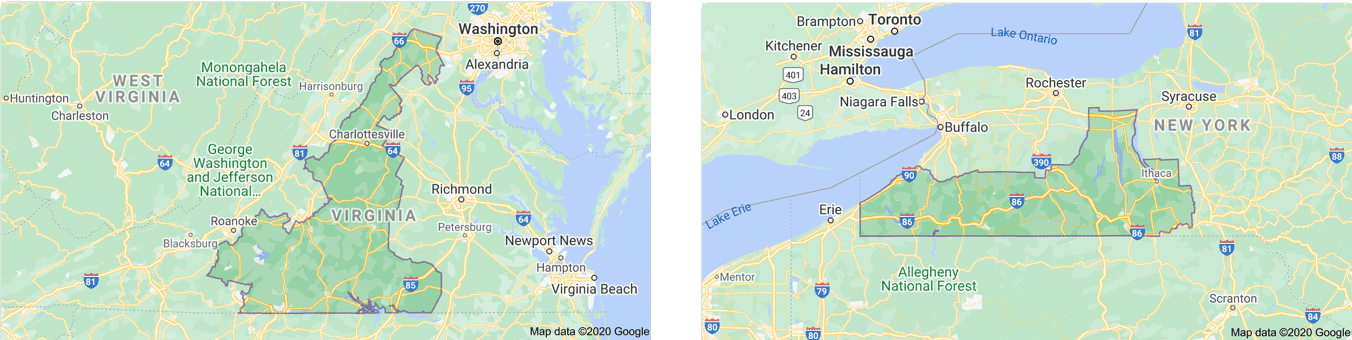
The Data
Clearly, then, we’re going to want to store and retrieve our geo points from a database if we want to implement queries against them on a large scale. And because the points are likely to be found in the form of an embedded array, a JSON document in Couchbase is just the ticket. Below is an example of such a document:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
{ "geometry": { "type": "Polygon", "coordinates": [ { "geometry": { "type": "Polygon", "coordinates": [ [ [-93.911307,44.546513999999995], [-93.91024,44.548004999999996], [-93.909904,44.548300999999995], [-93.90922599999999,44.548843999999995], [etc., etc., for hundreds or thousands of pairs] [-93.911307,44.546513999999995] ] ] }, "type": "Feature", "properties": { "INTPTLAT": "+44.4789680", "FUNCSTAT": "N", "INTPTLON": "-092.8530418", "LSAD": "C2", "GEOID": "2702", "AWATER": 243358361, "CD116FP": "02", "CDSESSN": "116", "MTFCC": "G5200", "NAMELSAD": "Congressional District 2", "STATEFP": "27", "ALAND": 6314464923 } } |
Why is the data shaped like this, you may wonder, with the polygon points embedded in a nameless single-element array, embedded in another “coordinates” one, embedded in a “geometry” object? The simple answer is that sometimes you just work with the data you have. (It is based on the public source I was able to find, one which was remarkably easy to import into Couchbase. Maybe I’ll write a separate post describing that process.) And even though the data is bit cumbersome, the N1QL language, as we will see below, makes it easy to retrieve what we need.
The other dataset which concerns us comprises the main portion of our example. It is a list of millions of registered voters (don’t worry; I faked the names and addresses), along with the party affiliation and voting history for each. A sample document looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "City": "Adelanto", "doctype": "Voter", "Name": "Ryan Johnson", "County": "San Bernardino", "Party": "Democrat", "Reg": [{"Year": 2018}, {"Voted": "In person","Year": 2016}, {"Year": 2014}, {"Voted": "In person","Year": 2012}, {"Year": 2010}, {"Voted": "In person","Year": 2008}, {"Year": 2006}, {"Voted": "In person","Year": 2004}, {"Year": 2002}, {"Voted": "In person","Year": 2000}, {"Year": 1998}, {"Voted": "In person","Year": 1996}], "Addr": "221 Cindy Inlet Suite 064", "Zip": "92301", "Geo": {"lat": 34.6149071942612,"lon": -117.51442556265236} } |
The Use Case and the Set-up
Finally, then, our use case: Given an individual constituent on the phone, how does a member of Congress quickly determine whether or not the person is a member of his or her voting district? We will solve the problem with FTS and N1QL.
First we must prepare the FTS index. In our case, we will index all documents based on the type field _type. We will index the Name field as a keyword, and the Geo field as a geopoint. Here is what it looks like on my console:
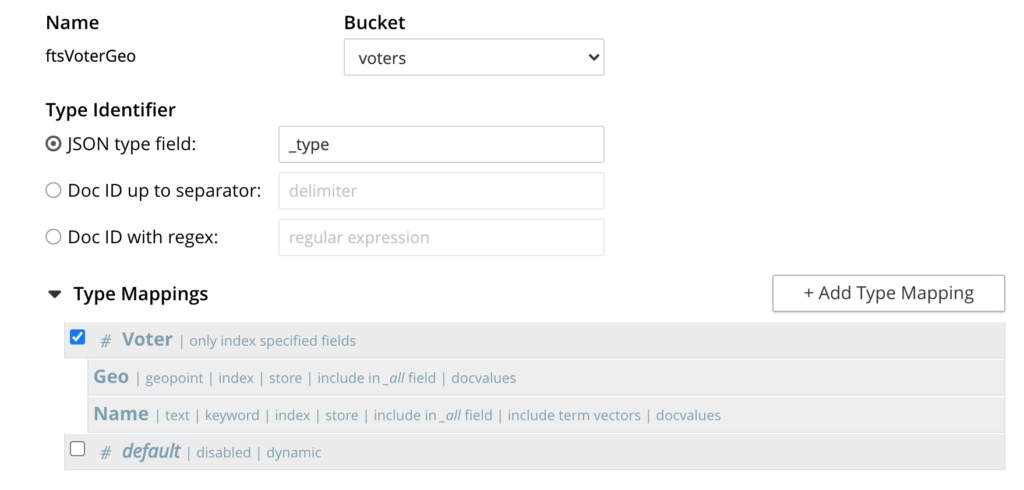
(Brian’s post goes into more detail on the steps you will follow to build an index.)
Once this index is built, we will be able to pass it a series of polygon points and receive a series of hits. Following Brian’s lead, I tested this using a curl:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
curl -s -XPOST -H "Content-Type: application/json" -u Administrator:password http://localhost:8094/api/index/ftsVoterGeo/query -d ' { "fields": ["Name"], "size": 50, "query": { "field": "Geo", "polygon_points": [ "33.4328, -114.7322", "33.5253, -114.6561", "33.6178, -114.5883", "34.6173, -117.4220" ] } }' | jq '("result_count: "+ (.total_hits | tostring)), (.hits[]| (.id + " " + .fields.Name))' |
This shows me that a search against a simple polygonal region can and will return a list of names. Theoretically, we could stop there and let the app (or even the user) search through the hits to see if it finds the individual voter name in question. But we can do better. Let’s let the search engine narrow it down. We do this via a “conjunct” search. (Think of a conjunct as a logical AND and a disjunct as a logical OR.) Below is the example curl:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
curl -s -XPOST -H "Content-Type: application/json" -u Administrator:password http://localhost:8094/api/index/ftsVoterGeo/query -d ' { "fields": ["Name"], "size": 50, "query": { "conjuncts": [ { "field": "Geo", "polygon_points": [ "33.4328, -114.7322", "33.5253, -114.6561", "33.6178, -114.5883", "34.6173, -117.4220" ] }, { "field": "Name", "match": "Anne Murray" } ] } }' | jq '("result_count: "+ (.total_hits | tostring)), (.hits[]| (.id + " " + .fields.Name))' |
You can read this as “If the geopoint is within the polygon boundaries and the name matches the voter name, return the hit.” Works like a charm, so we know our FTS index is properly defined.
The Extraction
Now, then, we need to test the retrieval of an individual district’s boundaries from the database. Our first pass at this entails just a simple inspection of the data we are likely to use, maybe just for a single district:
|
1 2 |
select properties.NAMELSAD, districts.geometry.coordinates from districts use keys 'district::87'; |
This returns a result like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[ { "NAMELSAD": "Congressional District 8", "coordinates": [ [ [ -119.651375, 38.286637999999996 ], [ -119.650185, 38.287234 ], |
…and on and on and on for another 1.3MB of a result set. No wonder we don’t want to cut and paste this.
Our goal, remember, is to end up with something which looks like this:
|
1 2 3 4 5 6 |
[ "33.4328, -114.7322", "33.5253, -114.6561", "33.6178, -114.5883", "34.6173, -117.4220" ] |
Here’s how we end up with just that:
|
1 2 3 4 5 |
select value concat(tostring(c[1]),", ",tostring(c[0])) points from ( select value districts.geometry.coordinates[0] from districts use keys 'district::87' )[0] c; |
This is quite a mouthful, so let’s unpack it. Remember that we’re working with the data that we have, rather than what we might ideally want, and the polygon points we’re after are embedded in a nameless single-element array, embedded in another “coordinates” one, embedded in a “geometry” object. We need to unwind them one-by-one. First, let’s eliminate the nameless array wrapper. We do this by simply requesting that only the single (first, or “zeroth”) member of the array be returned:
|
1 2 |
select districts.geometry.coordinates[0] from districts use keys 'district::87' |
The returned JSON object from this query looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[ { "$1": [ [ -119.651375, 38.286637999999996 ], [ -119.650185, 38.287234 ], [ -119.650139, 38.287678 ], |
We can convert this to an array (as opposed to a JSON object) by using select value:
|
1 2 |
select value districts.geometry.coordinates[0] from districts use keys 'district::87' |
Now we have the very large array we’re after, still wrapped in the single element of another array:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[ [ [ -119.651375, 38.286637999999996 ], [ -119.650185, 38.287234 ], [ -119.650139, 38.287678 ], [ -119.650154, 38.288041 |
Let’s select from that return set:
|
1 2 3 |
select * from ( select value districts.geometry.coordinates[0] from districts use keys 'district::87')[0] c |
This yields a bunch of little objects we can bend to our will:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[ { "c": [ -119.651375, 38.286637999999996 ] }, { "c": [ -119.650185, 38.287234 ] }, |
Now that we can address them let’s convert the types and perform our concatenation:
|
1 2 3 |
select concat(tostring(c[1]),", ",tostring(c[0])) points from ( select value districts.geometry.coordinates[0] from districts use keys 'district::87')[0] c |
The resulting objects look like this:
|
1 2 3 4 5 6 7 8 9 10 |
[ { "points": "38.286637999999996, -119.651375" }, { "points": "38.287234, -119.650185" }, { "points": "38.287678, -119.650139" }, |
Now use select value to receive them as an array:
|
1 2 3 |
select value concat(tostring(c[1]),", ",tostring(c[0])) points from ( select value districts.geometry.coordinates[0] from districts use keys 'district::87')[0] c |
And we have the results we’re looking for:
|
1 2 3 4 5 6 |
[ "38.286637999999996, -119.651375", "38.287234, -119.650185", "38.287678, -119.650139", "38.288041, -119.650154", "38.288593999999996, -119.649699", |
The Ease of CTEs
The last trick up our sleeve to pull this all together is a good one. We need a way to reference the array containing the geopoints as a component of a larger SQL statement. Fortunately, N1QL provides us with the means to do so in the form of Common Table Expressions (CTE). CTE, which are added to a query via the with clause, are evaluated once per query block and can be introduced before a select. This is exactly what we’re looking for:
|
1 2 3 4 5 |
with geopoints as ( select value concat(tostring(c[1]),", ",tostring(c[0])) points from ((select value d.geometry.coordinates[0] from districts d use keys 'district::87')[0]) c ) |
We now have access to an evaluated return set “geopoints” which can be referenced in subsequent (or multiple subsequent) SQL statements. Perfect. Here it is used in the final query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
with geopoints as ( select value concat(tostring(c[1]),", ",tostring(c[0])) points from ((select value d.geometry.coordinates[0] from districts d use keys 'district::87')[0]) c ) select Name from voters AS v where v._type = "Voter" AND search(v.Geo, { "query": { "conjuncts": [ { "field": "Geo", "polygon_points": geopoints }, { "field": "Name", "match": "Anne Murray" } ] } } ); |
There it is, then: A simple single-screen code block which retrieves the complex boundaries of a district and leverages them as part of a N1QL-driven geospatial search. Give the technique a try and conquer your own geographical challenges.
Thanks very much to Brian Kane for his original post and to Dmitry Lychagin for help in unraveling the nested arrays.