
Couchbase Server 7.0 solves the requirements of modern application development.
In doing so, it settles the debate over using relational or NoSQL databases. There’s no more need to compromise. (Try it out for yourself here or skip straight to the release notes for devs.)
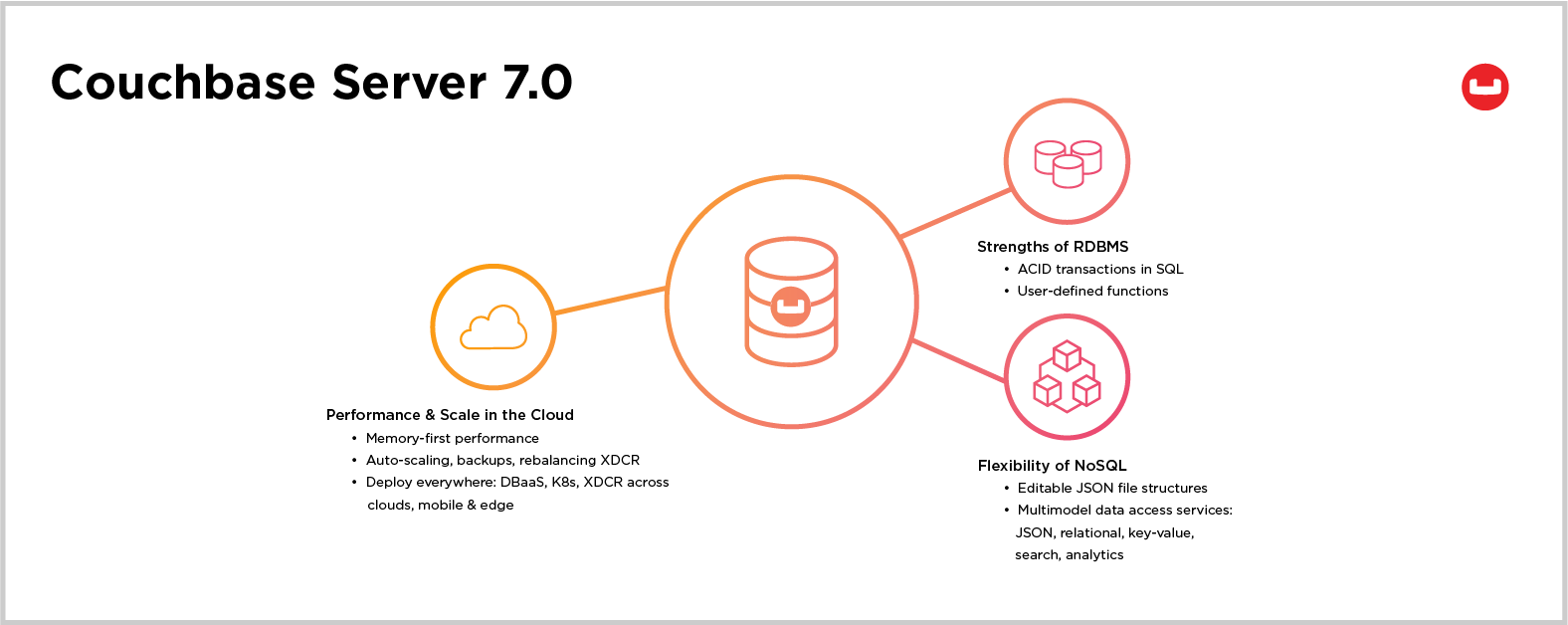
The 7.0 release fuses the trusted strengths of relational databases (RDBMS) with the flexibility, performance and scale of Couchbase in the cloud. This is our most comprehensive release ever, with over thirty major features that enable new and existing customers to easily escape the confines of slow-performing, rigid applications that are powered by aging relational databases.
Couchbase Server 7 fortifies relational data model support by adding:
-
- SQL transactions within N1QL
- A Dynamic Data Containment Model that adds multiple logical organization layers called Scopes and Collections
- Impressive performance and operational improvements that simplify your enterprise architecture while driving down total cost of ownership (TCO)
Let’s take a closer look.
Modern Applications Call for a Modern Database
Couchbase Server 7.0 supports the requirements of a new generation of modern applications.
These emerging applications are born from both the need to deliver personalized human experiences while also meeting the information processing demands of the modern enterprise. This means that modern applications must support traditional, trusted transactionality carried over from relational database platforms.
Modern applications must also simplify the mapping, migration and refactoring of relational database structures into flexible, NoSQL structures.
This highlights an interesting balance between the needs for structural consistency and for building or modifying structures on the fly. Developers need to communicate effectively about their database designs without giving up the JSON-based flexibility of NoSQL technology. Even more, DBAs shouldn’t have to be involved in every step.
This flexibility is mandatory in order for modern applications to support hyper-personalization that matches people to the perfect products or offers they seek – as they seek them. Of course, these activities happen in real time and require zero latency. Speed at scale is a key reason why enterprise customers choose Couchbase.
But modern applications don’t just exist on desktops: They’re mobile and IoT-enabled, too. Such mobility creates a new, valuable opportunity: location awareness and local search. This already happens with Google Maps, but tomorrow’s applications will support built-in and geo-location search functionality directly.
The challenge for development teams is that mobile devices and applications exist at the mercy of wireless networks and their carriers. Unfortunately, wires will always fail, and connectivity issues need to be both flexible and reliable.
These 5G-powered, edge-based applications need to process data both on the spot and on the server, blending data-backbone resources that glean new information from using large scale analytic processing and create new event-based actions as a result.
At Couchbase, we believe this next generation of modern applications will be intelligent in their own right and support a variety of machine learning capabilities fed by the same distributed-data backbone.
Couchbase Server 7.0 was designed for these robust application requirements.
Developers Need a Modern Database
With modern application development, developers are changing their behaviors too.
While they have experience with relational databases, modern developers are evolving and adopting new approaches to cloud-based application construction and delivery. They are moving to serverless development for both speedier times-to-market and cost-effective operations post deployment. They are adopting cloud-native best practices like continuous integration and continuous delivery (CI/CD) as a result.
But these approaches come with their own challenges: Developers must blend the stateless execution of application microservices with the need to maintain stateful data. With a modern database management platform like Couchbase, developers meet these challenges using data processing infrastructure designed for today’s – and tomorrow’s – development realities.
Ending the Relational vs. NoSQL Dichotomy
Modern Applications Can – and Should – Have It All
Modern applications are transactional.
Historically, transactional workloads have been the strong suit of relational databases and less-so for NoSQL systems. This difference has primarily been because NoSQL systems offered scale at the expense of data consistency.
No longer.
Couchbase Server 7 ends the debate between RDBMS and NoSQL databases for transactional workloads. Developers can now confidently support transactional use cases in their applications when they use Couchbase Server 7, including:
-
- Shopping cart assembly and purchases
- Inventory control systems
- Shipment confirmations
- Billing and payment processing
- Media streaming, including episode progress and bookmarking
The unlocked possibilities are endless.
Distributed SQL Transactions Added to N1QL Query Language
To support modern transactional applications, we have added SQL transactions to the N1QL query language.
These additions are multi-document, distributed ACID transactions that are read and written in familiar SQL syntax. Commands include:
-
- START
- UPDATE
- DELETE
- UPSERT
- MERGE
- SAVEPOINT
- ROLLBACK
- COMMIT
- And others
These queries are framed as multi-statement transactions to ensure data integrity for operations when multiple concurrent activities occur. For example, an ecommerce purchase touches inventory and order processing at the same time.
These SQL transactions work alongside the application-level transactionality supported by Couchbase SDKs, which give developers a high degree of control over application behavior and performance management.
Read more about ACID Transactions in the Couchbase Server 7.0 Documentation.
New Dynamic Data Containment Model: Scopes and Collections
Scopes and Collections are new data organization layers between Couchbase Buckets and JSON documents.
Together, Scopes and Collections change the game by making Couchbase one of the few flexible NoSQL systems to support multi-layered structures that map to RDBMS schema. At the same time, they maintain the flexibility of NoSQL to add new data structures on demand.
No other NoSQL system offers this structure-and-flexibility package. With Scopes and Collections, you simplify the process for migrating, shifting and refactoring from relational to JSON.
Every data access and processing service in Couchbase takes advantage of Scopes and Collections, from N1QL additions to a re-design of our role-based access control (RBAC) features. Even clustering, sharding, backups and cross data center replication (XDCR) take advantage of these new data structures. The design is elegant.
In order to implement Scopes and Collections, all bucket-level operations were pushed down into the more granular level of Collections. As a result, indexes – including global secondary indexes (GSIs) – are smaller, faster and easier to build and manage. GSIs are attached to their associated documents at the Collection level which makes them portable when you shard or rebalance data across cluster nodes. The end result is dramatic performance improvements from faster fail-over and rebalancing to building indexes in parallel.
Read more about Scopes and Collections in the Couchbase Server 7.0 Documentation.
Lift, Shift and Refactor Old Applications into Modern Ones
The benefits of Scopes and Collections are significant.
First, they simplify the greatest challenges in application modernization. With Scopes and Collections, architects have a roadmap for how to migrate from relational to non-relational database systems. This three-step process called “lift, shift and refactor” helps teams move seamlessly from RDBMS into Couchbase. (Check out our ten minute demo.)
The new Dynamic Data Containment Model in Couchbase allows enterprise customers to develop rich customer 360 data models that drive personalization at the edge. In the immediate term, you can now bolster distressed legacy RDBMS systems with high-performance caching, and in the long term, you can refactor and migrate your data structures as JSON documents.
Scopes and Collections help organizations expedite long-standing plans to modernize and migrate RDBMS-based applications into the cloud, where they enjoy not only better flexibility but also lower total cost of ownership.
If you’re ready to get started but don’t know where to start, connect with one of our systems integrators partners or reach out to Couchbase Professional Services. We’re happy to help.
Every Couchbase Data Access & Processing Service Is Improved
Query Service
The N1QL Query Service adds user-defined functions (UDFs) within N1QL, as does the Analytics Service (see below).
A cost-based query optimizer replaces the old rules-based optimization, which both simplifies development and saves time. Developers save even more time with the Index Advisor function in N1QL that tells you the best index to use or build for any SQL query you supply. Finally, you can also set memory quota assignments for queries so that they don’t hog resources at execution time.
Read more about the Query Service and the N1QL Cost-Based Optimizer in the Couchbase Server 7.0 Documentation.
Index Service
The introduction of Scopes and Collections has dramatically impacted indexing in Couchbase.
Now, indexes are built in parallel which means that index construction for 100 or 1000 indexes takes only as much time as the largest index takes to complete. The number of Global Secondary Indexes (GSIs) has also been expanded to 10,000 per cluster. That’s a lot! And GSIs are attached to their associated documents’ Collections, so they’re both small and portable. In fact, GSIs automatically move along with their Collections when data is repartitioned or rebalanced.
Read more about the Index Service in the Couchbase Server 7.0 Documentation.
Analytics Service
The Analytics Service takes advantage of Scopes and Collections, and also adds user-defined functions.
We’ve also added new data processing functions for ROLLUP and CUBE creation operations, and we are introducing Python-based machine learning operations for developers’ preview. For cloud deployments, the Analytics Service also adds the ability to access a new external dataset, Microsoft Azure Blobs.
Full-Text Search
Full-Text Search (FTS) operations now search within Scopes, within Collections and across multiple Collections of documents.
We have also added a new Quick Index function for the Full-Text Search Service.
Eventing Service
The Eventing Service automatically creates its own Collection for events and includes a number of performance and security improvements.
NEW! Backup Service
We have added a new data processing service to Couchbase: the Backup Service.
This service takes both full and incremental Collection-level backups at whatever interval your administrator specifies, and it creates backups in AWS S3 or NFS Samba storage. The Backup Service is configured with a graphical user interface and also supports command-line access as well.
Because it is a data processing service, the Backup Service supports multidimensional scaling and resource assignment to cluster nodes, which makes it flexible as well as isolates workloads that may contend for resources with other services. When restorations are necessary, administrators can re-map backups to specific Collections and filter backup results as they are being restored.
Read more about the new Backup Service in the Couchbase Server 7.0 Documentation.
Operational Performance Improvements to Lower TCO
With all these changes and the introduction of a new data consistency management library called Chronicle, you’ll notice incredible improvements to both performance and node-for-node data density.
Administrators and CFOs will love that Couchbase does even more with less resource consumption, driving down operational TCO and simplifying deployments. For example, data-density stored per node has increased because of Collection-level data access, partitioning and index granularity. When we’ve tested Couchbase Server 7.0, it impressively supports linear scaling of indexes, transactions, rebalancing and failover as cluster sizes grow.
As mentioned above, Chronicle is a Raft-based data consistency management library that supports strong consistency across cluster nodes for cluster metadata. Chronicle also contributes to an impressive impact on performance, helping failovers run up to 4x faster and reducing data rebalancing times from hours to minutes. Overall the software consumes less memory and uses CPU more efficiently.
We’ve also added Prometheus-based statistics for Collections, and when you run Couchbase Server 7 with Autonomous Operator 2.8, it supports auto-scaling of clusters both up and down based on predetermined thresholds stored in your Kubernetes YAML file.
Customer Benefits of Couchbase Server 7
Couchbase Server 7 is an impressive release, and we expect it to be adopted readily.
This release simplifies the creation and execution of business transactions within modern personal experience applications. It enables simplified application architectures and faster operational performance while expanding into highly transactional applications that drive the enterprise.
Couchbase Server 7 sets the new benchmark as a modern transactional database for multimodel data access modes, in-memory performance, relational portability, JSON flexibility, and distributed scale.
Enjoy the release.
Ready to learn more?
Attend this webinar Couchbase Server 7 Fuses the Strength of Relational with the Flexibility & Scale of NoSQL to discover why enterprises choose Couchbase when other databases don’t deliver. Register for a time zone near you:
North America | Europe/Middle East | Asia Pacific
Attend this webinar Couchbase Server 7 Fuses the Strength of Relational with the Flexibility & Scale of NoSQL to discover why enterprises choose Couchbase when other databases don’t deliver. Register for a time zone near you:
North America | Europe/Middle East | Asia Pacific
[…] Couchbase Server 7’deki yenilikleri öğrenmek için bu blog yazısını okuyun […]
[…] over a particular query and let you instruct the query language on how certain tasks are done. The Couchbase Server 7.0 release includes user-defined functions for the N1QL query […]