
I have been wanting to showcase most of the new Couchbase’s search features available in 4.5 in one simple project. And there have been some interest recently about storing files or binaries in Couchbase. From a general, generic perspective, databases are not made to store files or binaries. Usually what you would do is store files in a binary store and their associated metadata in the DB. The associated metadata will be the location of the file in the binary store and as much informations as possible extracted from the file.
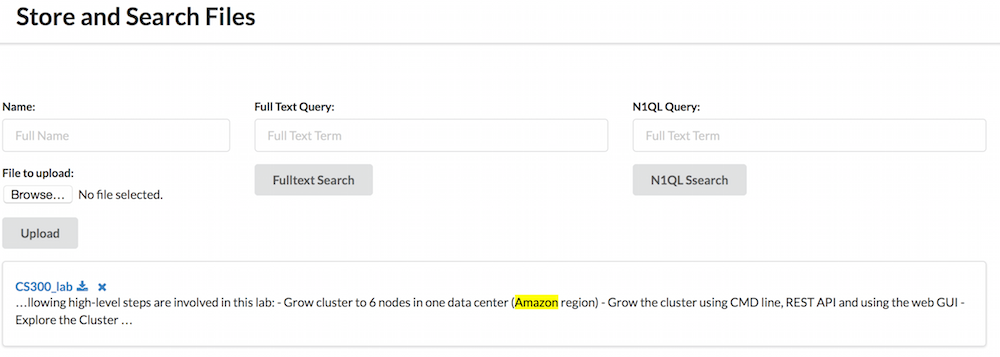
So this is the project I will show you today. It’s a very simple Spring Boot app that let the user upload files, store them in a binary store, where associated text and metadata will be extracted from the file, and let you search files based on those metadata and text. At the end you’ll be able to search files by mimetype, image size, text content, basically any metadata you can extract from the file.
The Binary Store
This is a question we get often. You can certainly store binary data in a DB but files should be in an appropriate binary store. I decided to create a very simple implementation for this example. There is basically a folder on filesystem declared at runtime that will contained all the uploaded files. A SHA1 digest will be computed from the file’s content and used as filename in that folder. You could obviously use other, more advanced binary stores like Joyent’s Manta or Amazon S3 for instance. But let’s keep things simple for this post :) Here’s a description of the services used.
SHA1Service
This is the simplest one, with one method that bascially sends back a SHA-1 digest based on the content of the file. To simplify the code even more I am using Apache commons-codec:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@Service public class SHA1Service { public String getSha1Digest(InputStream is) { try { return DigestUtils.sha1Hex(is); } catch (IOException e) { throw new RuntimeException(e); } } } |
DataExtractionService
This service is here to to extract metadata and text from the uploaded files. There are a lot of different ways to do so. I have choosen to rely on ExifTool and Poppler.
ExifTool is a great command line tool that to read, write and edit file metadata. It can also output metadata directly in JSON. And it’s of course not limited to the Exif standard. It supports a wide variety of formats. Poppler is a PDF utility library that will allow me to extract the text content of a PDF. As these are command line tools, I will use plexus-utils to ease the CLI calls.
There are two methods. The first one is extractMetadata and is responsible for ExifTool metadata extraction. It’s the equivalent of running the following command:
|
1 2 |
exiftool -n -json somePDFFile |
The -n option is here to make sure all numerics value will be given as numbers and not Strings and -json to make sure the output is in JSON format. This can give you an output like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[{ "SourceFile": "Desktop/someFile.pdf", "ExifToolVersion": 10.11, "FileName": "someFile.pdf", "Directory": "Desktop", "FileSize": 20468, "FileModifyDate": "2016:03:29 13:50:29+02:00", "FileAccessDate": "2016:03:29 13:50:33+02:00", "FileInodeChangeDate": "2016:03:29 13:50:33+02:00", "FilePermissions": 644, "FileType": "PDF", "FileTypeExtension": "PDF", "MIMEType": "application/pdf", "PDFVersion": 1.4, "Linearized": false, "ModifyDate": "2016:03:29 02:42:32-07:00", "CreateDate": "2016:03:29 02:42:32-07:00", "Producer": "iText 2.1.6 by 1T3XT", "PageCount": 1 }] |
There are some interesting informations like the mime-type, the size, the creation date and more. If the mime-type of the file is application/pdf then we can try to extract text from it with poppler, which is what the second method of the service is doing. It’s equivalent to the following CLI call:
|
1 2 |
pdftotext -raw somePDFFile - |
This command sends the extracted text to the standard output. Which we can retrieve and put in a fulltext field in a JSON object. Full code of the service below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
package org.couchbase.devex.service; import java.io.File; import org.codehaus.plexus.util.cli.CommandLineException; import org.codehaus.plexus.util.cli.CommandLineUtils; import org.codehaus.plexus.util.cli.Commandline; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Service; import com.couchbase.client.java.document.json.JsonArray; import com.couchbase.client.java.document.json.JsonObject; @Service public class DataExtractionService { private final Logger log = LoggerFactory.getLogger(DataExtractionService.class); public JsonObject extractMetadata(File file) { String command = "/usr/local/bin/exiftool"; String[] arguments = { "-json", "-n", file.getAbsolutePath() }; Commandline commandline = new Commandline(); commandline.setExecutable(command); commandline.addArguments(arguments); CommandLineUtils.StringStreamConsumer err = new CommandLineUtils.StringStreamConsumer(); CommandLineUtils.StringStreamConsumer out = new CommandLineUtils.StringStreamConsumer(); try { CommandLineUtils.executeCommandLine(commandline, out, err); } catch (CommandLineException e) { throw new RuntimeException(e); } String output = out.getOutput(); if (!output.isEmpty()) { JsonArray arr = JsonArray.fromJson(output); return arr.getObject(0); } String error = err.getOutput(); if (!error.isEmpty()) { log.error(error); } return null; } public String extractText(File file) { String command = "/usr/local/bin/pdftotext"; String[] arguments = { "-raw", file.getAbsolutePath(), "-" }; Commandline commandline = new Commandline(); commandline.setExecutable(command); commandline.addArguments(arguments); CommandLineUtils.StringStreamConsumer err = new CommandLineUtils.StringStreamConsumer(); CommandLineUtils.StringStreamConsumer out = new CommandLineUtils.StringStreamConsumer(); try { CommandLineUtils.executeCommandLine(commandline, out, err); } catch (CommandLineException e) { throw new RuntimeException(e); } String output = out.getOutput(); if (!output.isEmpty()) { return output; } String error = err.getOutput(); if (!error.isEmpty()) { log.error(error); } return null; } } |
Fairly Simple stuff as you can see once you use plexus-utils.
BinaryStoreService
This service is reponsible for running the data extraction and storing files, deleting files or retrieving files. Let’s start with the storing part. Everything happens in the storeFile method. First thing to do is retrieve the digest of the file, than write it in the binary store folder declared in the configuration. Once the file is written the data extraction service is called to retrieve Metadata as a JsonObject. Then binary store location, document type, digest and filename are added to that JSON object. If the uploaded file is a PDF, the data extraction service is called again to retrieve the text content and store it in a fulltext field. Then a JsonDocument is created with the digest as key and the JsonObject as content.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public void storeFile(String name, MultipartFile uploadedFile) { if (!uploadedFile.isEmpty()) { try { String digest = sha1Service.getSha1Digest(uploadedFile.getInputStream()); File file2 = new File(configuration.getBinaryStoreRoot() + File.separator + digest); BufferedOutputStream stream = new BufferedOutputStream(new FileOutputStream(file2)); FileCopyUtils.copy(uploadedFile.getInputStream(), stream); stream.close(); JsonObject metadata = dataExtractionService.extractMetadata(file2); metadata.put(StoredFileDocument.BINARY_STORE_DIGEST_PROPERTY, digest); metadata.put("type", StoredFileDocument.COUCHBASE_STORED_FILE_DOCUMENT_TYPE); metadata.put(StoredFileDocument.BINARY_STORE_LOCATION_PROPERTY, name); metadata.put(StoredFileDocument.BINARY_STORE_FILENAME_PROPERTY, uploadedFile.getOriginalFilename()); String mimeType = metadata.getString(StoredFileDocument.BINARY_STORE_METADATA_MIMETYPE_PROPERTY); if (MIME_TYPE_PDF.equals(mimeType)) { String fulltextContent = dataExtractionService.extractText(file2); metadata.put(StoredFileDocument.BINARY_STORE_METADATA_FULLTEXT_PROPERTY, fulltextContent); } JsonDocument doc = JsonDocument.create(digest, metadata); bucket.upsert(doc); } catch (Exception e) { throw new RuntimeException(e); } } else { throw new IllegalArgumentException("File empty"); } } |
Reading or deleting should be pretty straight forward to understand now:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public StoredFile findFile(String digest) { File f = new File(configuration.getBinaryStoreRoot() + File.separator + digest); if (!f.exists()) { return null; } JsonDocument doc = bucket.get(digest); if (doc == null) return null; StoredFileDocument fileDoc = new StoredFileDocument(doc); return new StoredFile(f, fileDoc); } public void deleteFile(String digest) { File f = new File(configuration.getBinaryStoreRoot() + File.separator + digest); if (!f.exists()) { throw new IllegalArgumentException("Can't delete file that does not exist"); } f.delete(); bucket.remove(digest); } |
Please keep in mind that this is a very naïve inplementation!
Indexing and Searching Files
Once you have uploaded files, you want to retrieve them. The first very basic way of doing so would be to display the full list of files. Then you could use N1QL to search them based on their metadatas or FTS to search them based on their content.
The Search Service
getFiles method simply runs the following query: SELECT binaryStoreLocation, binaryStoreDigest FROMdefaultWHERE type= 'file'. This sends the full list of uploaded files with their digest and binary store location. Notice the consistency option set to statement_plus. It’s a document application so I prefer strong consistency.
Next you have searchN1QLFiles that runs a basic N1QL query with an additional WHERE clause. So the default is the same query as above with an additional WHERE part. There is no tighter integration so far. We could have a fancy search form allowing the user to search for files based on their mime-types, size or any other fields given by ExifTool.
And finally you have searchFulltextFiles that takes a String as input and use it in a Match query. Then the result is sent back with fragments of text where the term was found. This fragment allow highlighting of the term in context. I also ask for the binaryStoreDigest and binaryStoreLocation fields. They are the one used to display the results to the user.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
public List<Map<String, Object>> getFiles() { N1qlQuery query = N1qlQuery .simple("SELECT binaryStoreLocation, binaryStoreDigest FROM `default` WHERE type= 'file'"); query.params().consistency(ScanConsistency.STATEMENT_PLUS); N1qlQueryResult res = bucket.query(query); List<Map<String, Object>> filenames = res.allRows().stream().map(row -> row.value().toMap()) .collect(Collectors.toList()); return filenames; } public List<Map<String, Object>> searchN1QLFiles(String whereClause) { N1qlQuery query = N1qlQuery.simple( "SELECT binaryStoreLocation, binaryStoreDigest FROM `default` WHERE type= 'file' " + whereClause); query.params().consistency(ScanConsistency.STATEMENT_PLUS); N1qlQueryResult res = bucket.query(query); List<Map<String, Object>> filenames = res.allRows().stream().map(row -> row.value().toMap()) .collect(Collectors.toList()); return filenames; } public List<Map<String, Object>> searchFulltextFiles(String term) { SearchQuery ftq = MatchQuery.on("file_fulltext").match(term) .fields("binaryStoreDigest", "binaryStoreLocation").build(); SearchQueryResult result = bucket.query(ftq); List<Map<String, Object>> filenames = result.hits().stream().map(row -> { Map<String, Object> m = new HashMap<String, Object>(); m.put("binaryStoreDigest", row.fields().get("binaryStoreDigest")); m.put("binaryStoreLocation", row.fields().get("binaryStoreLocation")); m.put("fragment", row.fragments().get("fulltext")); return m; }).collect(Collectors.toList()); return filenames; } |
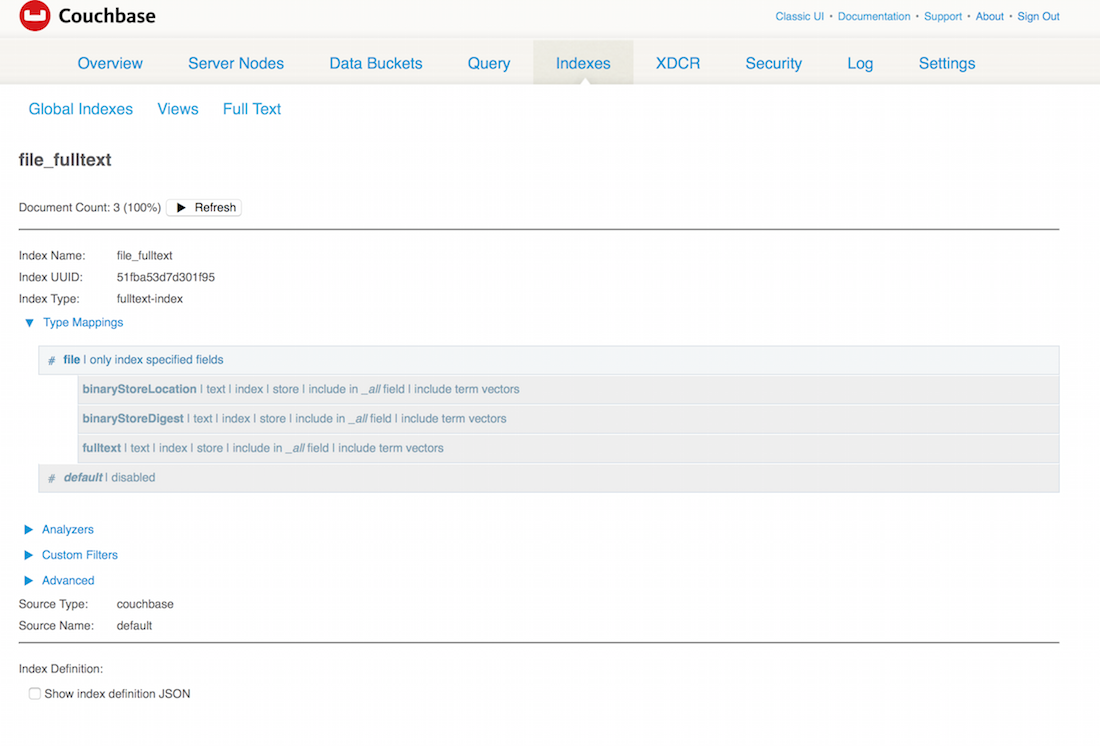
The TermQuery.on method defines which index I am querying. Here it’s set to ‘file_fulltext’. It means I have created a full text index with that name:
Putting Everything Together
Configuration
A quick word about configuration first. The only thing configurable so far is the binary store path. Since I am using Spring Boot, I just need the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
package org.couchbase.devex; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Configuration; @Configuration public class BinaryStoreConfiguration { @Value("${binaryStore.root:upload-dir}") private String binaryStoreRoot; public String getBinaryStoreRoot() { return binaryStoreRoot; } } |
With that I can simply add binaryStore.root=/Users/ldoguin/binaryStore to my application.properties file. I also want to allow upload of 512MB file max. Also, to leverage Spring Boot Couchbase autoconfig, I need to add the address of my Couchbase Server. In the end my application.properties looks like this:
|
1 2 3 4 5 |
binaryStore.root=/Users/ldoguin/binaryStore multipart.maxFileSize: 512MB multipart.maxRequestSize: 512MB spring.couchbase.bootstrap-hosts=localhost |
Using Spring Boot autoconfig simply requires to have spring-boot-starter-parent as parent and Couchbase in the classpath. So it’s just a matter of adding a Couchbase java-client dependency. I am specifying the 2.2.4 version here because it defaults to 2.2.3 and FTS is only in 2.2.4. You can take a look at the full pom file on Github. Kudos to Stéphane Nicoll from Pivotal and Simon Baslé from Couchbase for this wonderful Spring integration.
Controller
Since this application is very simple, I have put everything under the same controller. The most basic endpoint is /files. It display the list of files already uploaded. Just one call to the searchService, put the result in the page Model and then render the page.
|
1 2 3 4 5 6 7 |
@RequestMapping(method = RequestMethod.GET, value = "/files") public String provideUploadInfo(Model model) { List<Map<String, Object>> files = searchService.getFiles(); model.addAttribute("files", files); return "uploadForm"; } |
I use Thymeleaf for rendering and Semantic UI as CSS framework. You can take a look at the template used here. It’s the only template used in the application.
Once you have a list of files, you can download or delete them. Both method are calling the binary store service method, the rest of the code is classic Spring MVC:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
@RequestMapping(method = RequestMethod.GET, value = "/download/{digest}") public String download(@PathVariable String digest, RedirectAttributes redirectAttributes, HttpServletResponse response) throws IOException { StoredFile sf = binaryStoreService.findFile(digest); if (sf == null) { redirectAttributes.addFlashAttribute("message", "This file does not exist."); return "redirect:/files"; } response.setContentType(sf.getStoredFileDocument().getMimeType()); response.setHeader("Content-Disposition", String.format("inline; filename="" + sf.getStoredFileDocument().getBinaryStoreFilename() + """)); response.setContentLength(sf.getStoredFileDocument().getSize()); InputStream inputStream = new BufferedInputStream(new FileInputStream(sf.getFile())); FileCopyUtils.copy(inputStream, response.getOutputStream()); return null; } @RequestMapping(method = RequestMethod.GET, value = "/delete/{digest}") public String delete(@PathVariable String digest, RedirectAttributes redirectAttributes, HttpServletResponse response) { binaryStoreService.deleteFile(digest); redirectAttributes.addFlashAttribute("message", "File deleted successfuly."); return "redirect:/files"; } |
Obviously you’ll want to upload some files too. It’s a simple Multipart POST. The binary store service is called, persist the file and extract the appropriate data, then redirect to the /files endpoint.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@RequestMapping(method = RequestMethod.POST, value = "/upload") public String handleFileUpload(@RequestParam("name") String name, @RequestParam("file") MultipartFile file, RedirectAttributes redirectAttributes) { if (name.isEmpty()) { redirectAttributes.addFlashAttribute("message", "Name can't be empty!"); return "redirect:/files"; } binaryStoreService.storeFile(name, file); redirectAttributes.addFlashAttribute("message", "You successfully uploaded " + name + "!"); return "redirect:/files"; } |
The last two methods are used for the search. They simply call the search service and add the result to the page Model and render it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@RequestMapping(method = RequestMethod.POST, value = "/fulltext") public String fulltextQuery(@ModelAttribute(value = "name") String query, Model model) throws IOException { List<Map<String, Object>> files = searchService.searchFulltextFiles(query); model.addAttribute("files", files); return "uploadForm"; } @RequestMapping(method = RequestMethod.POST, value = "/n1ql") public String n1qlQuery(@ModelAttribute(value = "name") String query, Model model) throws IOException { List<Map<String, Object>> files = searchService.searchN1QLFiles(query); model.addAttribute("files", files); return "uploadForm"; } |
And this is roughly all you need to store, index and search files with Couchbase and Spring Boot. It is a simple app and there are many, many other things you could do to improve it, starting by a proper search form exposing ExifTool extracted fields. Multiple file uploads and drag and drop would be a nice plus. What else would you like to see? Let us know in the comments bellow!