
With the launch of Couchbase Server 5.5, we have introduced end-to-end compression which allows data to remain compressed through: client to cache, to disk storage, to replication of data across data centers. Since most of our customer data is in JSON text which is readily compressible, this we believe would lead to invaluable storage and bandwidth conservation.
Let me provide you a quick overview of the data flow within Couchbase to set the stage for deep diving into data compression.
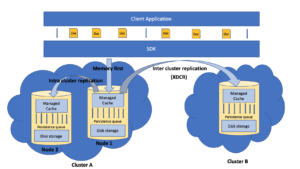
Fig 1. Data flow within Couchbase data platform
The data from the client application first flows into managed cached via SDKs, since Couchbase supports and advocates a memory first architecture. This data in the cache is then persisted onto the disk via persistence queue. All the key-value operations are performed on the data in the cache unless there is a cache miss, where data is retrieved from the disk and maintained in cache for future access. This data from the cache is also replicated onto other replica nodes via intra cluster replication queue for high availability. This is followed by intercluster replication (if applicable) where the data from memory is replicated to other Couchbase clusters which are mostly distributed across datacenters in diverse geographies using Couchbase’s very own Cross Datacenter Replication (XDCR) technology.
All forms of replication in Couchbase be it local persistence, intra cluster replication or inter cluster replication relies on a single protocol called the Database Change Protocol (DCP) which characterizes in no loss recovery on interruption, RAM to RAM streaming and multithreaded parallel processing.
The figure below indicates the various stages within this data flow from client application to storage where data is compressed within couchbase data platform.
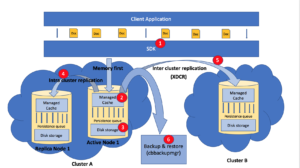
Fig 2. Data Compression in Couchbase Data Platform
- The SDK can elect to receive the data in the compressed or decompressed mode depending on the application user’s choice. The SDK indicates this status via flags to Managed cache.
- The Managed Cache which is also a key value store now supports compression where it can receive both compressed and decompressed data.It operates in three modes :
Off: No compression
Passive : (Default) If cache receives compressed documents, it is stored in compressed form but no effort is made to compress the uncompressed documents.
Active: Even uncompressed documents are compressed and stored.
- On the Disk, the data is always stored in the compressed form.
- The Cross Datacenter Replication (XDCR) supports compression. But the user has to make a choice if they would like to enable compression during replication of their data across data centers.
- Cbbackupmgr is the Couchbase’s native backup & restore technology. Since, 5.0 cbbackupmgr supports compression where the data can be stored compressed when they are backed up.
All replications are handled by database change protocol and it supports compression of documents. But the clients of DCP like XDCR, backup & restore etc receive compressed or uncompressed data from DCP depending on the inputs provided by specific client.
We believe compression is a significant value add to Couchbase data platform’s customers since it minimizes cost of storage, network and memory even for the existing deployments. For enterprises deploying Couchbase on public clouds like AWS, Azure or GCP, the bandwidth conservation during replication of huge amounts of data (TBs) across data centers would directly attribute to cost savings as the cloud providers charge based on bandwidth utilization.
Please note: There is no rule of thumb which dictates if data is always compressed or uncompressed in the flow as ultimate efficiency is subject to various factors like type of data, bandwidth available, impact on throughput , CPU utilization etc., system is designed to opt the route with the maximum efficiency depending on all the factors.
Do share your feedback and experience here or reach out to us on our forum. See Couchbase compression-related documentation here.
Thanks Chaitra for this post.
Is there a way to measure the compression achieved (on disk)? Let’s say a bucket is populated with 100m documents. Once done, we see that there are 3-4 different flavours. So we can’t really multiply the number of documents by the size of each document because we don’t know the size of each document. And even if we identify one (sample) document of each flavour, it is not necessary that all documents of that flavour are of same size. And there seems to be no way to find avg size of all 100m documents (or is there a way?)
Then, If we look at the size of data on disk, it is the size after compression.
Had we known the size before compression and if that would be compared with size on disk (compressed data), then compression ratio could have been determined.
Thanks