If you’re looking to migrate your data from a relational database to NoSQL, then now’s a better time than ever.
The recent release of Couchbase 7.0 introduced Scopes and Collections – a new way to organize your JSON data. More than anything else, Scopes and Collections make it simpler and easier to migrate your current relational data model to the Couchbase document data model. As a result, your enterprise benefits from Couchbase’s distributed shared-nothing architecture, high availability and horizontal scalability.
And if you’re a long-time Couchbase customer or user – Scopes and Collections have a lot to offer in terms of data management and organization.
But no matter whether you’re new to NoSQL or you’re a Couchbase veteran, your database queries – using the N1QL query language – benefit from the new Scopes and Collections data model. If you want to simplify your N1QL queries, then you’ll need to migrate your Couchbase data from the old Bucket model over to the new Collections model. Fortunately, the migration is an easy five-step process.
Let’s start with a review of Scopes and Collections. (Or skip straight to the migration guide if you’re ready.)
Wait, What Are Scopes & Collections?
A Scope is equivalent to a schema in a relational database (RDBMS). It is a logical container for Couchbase Collections. Every Couchbase Bucket contains a default Scope. You can use these default containers directly – or define your own.
A Collection is analogous to a table in an RDBMS. Every Scope has a default Collection. While a Collection can be used to store similar types of records (like an RDBMS table), there is no schema restriction on what you can store in a Collection. It’s entirely up to you.
Below is an illustration of how various relational database concepts map to these new features of Couchbase Server 7.0:
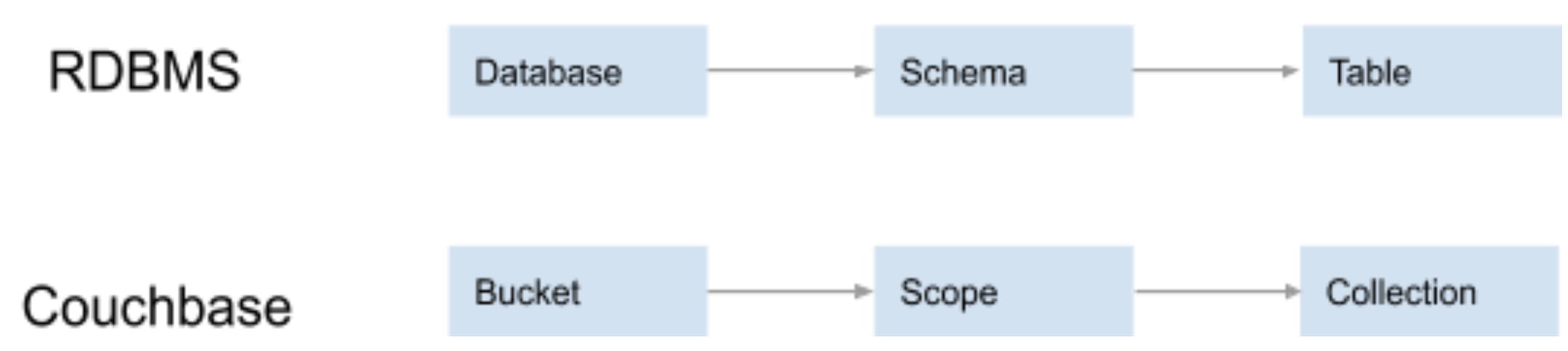
As you can see, there’s now one-to-one mapping between relational and NoSQL data models when using Scopes and Collections in Couchbase.
System Keyspaces under Scopes & Collections
| Keyspace | Description |
system:all_scopes |
A list of all Scopes, including system objects, such as the default Scopes |
system:scopes |
All available Scopes except the system Scopes |
system:all_collections |
A list of all Collections, including system objects, such as the default Collections |
system:collections |
All available Collections except system Collections |
How Scopes & Collections Streamline Your N1QL Queries
One major consequence of Scopes and Collections is that the N1QL query language is now simpler. This is because a type field is no longer required on every document. As a result, both the Data Definition Language (DDL) and Data Manipulation Language (DML) of N1QL statements are easier to write and understand.
N1QL Queries Are Now Simpler & More Intuitive
Couchbase Collections provide you with the equivalent of a relational table. The strength of this similarity – without any of its weaknesses – bridges the gap between the logical and physical data model that many RDBMS are used to.
Take a look at these side-by-side N1QL queries below using the travel-sample dataset.
| Bucket model | Collection model | ||||
|
|
The query on the left jumps illustrates how you had to specify the document type field under the old Bucket model. The query on the right is simpler because the document type is no longer required under the new Collection model introduced in Couchbase 7.0.
N1QL JOIN Conditions Are Simpler Too
JOINs in N1QL also got easier. Take a look at this old-vs-new query comparison below.
| Bucket model | Collection model | ||||
|
|
Under the new Collection model, the JOIN syntax doesn’t require you to use the type field to restrict your query to a specific table of documents within the Bucket.
N1QL Queries Retain Backward Compatibility with the Bucket Model
The introduction of the new Collection model doesn’t mean the end of Buckets. The N1QL Query Service still supports the Bucket model as before.
The only change is that now your Bucket data is stored in the default Scope which in turn contains a default Collection.
| Bucket model | Collection model | ||||||
|
You can either use:
or
|
Please note that the namespace prefix is required and should have the value default: for all references to the default Scope or default Collection.
An Important Change to N1QL Queries with Collections
With the Collection model, the query engine needs to be aware of the full path of the Collection name. This is because a Collection name doesn’t have to be unique within a Bucket, but only within its own Scope.
A fully qualified Collection name has the following format:
Format:
|
1 |
namespace:bucket.scope.collection |
Example:
|
1 |
namespace:`travel-sample`.booking.hotel |
However, you can reference a Collection with its relative path by setting the query_context
The Query Workbench UI allows you to set the query context by selecting the Bucket and Scope from the drop-down box (in the top right of the screenshot below).

The query context is also supported in Couchbase SDKs, the REST API and cbq shell.
Do I Have to Migrate to Collections?
No, you don’t have to migrate to the Collections model if you don’t want to.
Here’s what stays the same if you choose not to migrate:
-
- Data: All existing data remains in the same Bucket. You can reference your documents using the Bucket query syntax or by using the new default Scope and Collection.
- Queries: N1QL query syntax for the DDL and DML continue to support the Bucket model.
- Indexes: Your existing indexes will remain at the Bucket level and will continue to be available to all of your queries as before.
Migrating from Bucket to Collections in Couchbase 7.0
If you’re ready to migrate from the old Bucket model to the new Scopes and Collections model now available in Couchbase 7.0, here are the five main steps you need to complete.
For this migration guide, I’ll use the travel-sample Bucket as an example dataset.
Step 1: Data Migration
If your documents already have a field to identify their groups, then use those groupings to create your Collections.
For the travel-sample dataset, let’s use the respective type fields as the Collection names. In addition, we’ll also create an inventory Scope for all of the Collections in the dataset.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE SCOPE `travel-sample`.inventory; CREATE COLLECTION `travel-sample`.inventory.route; CREATE COLLECTION `travel-sample.inventory.landmark; CREATE COLLECTION `travel-sample`.inventory.airline; CREATE COLLECTION `travel-sample`.inventory.hotel; CREATE COLLECTION `travel-sample`.inventory.airport; |
In the above example, we created an inventory Scope and added new Collections within the same travel-sample Bucket.
Step 2: Ensure Unique Document Keys
Document keys need to be unique.
The document key that you currently have for your existing Bucket(s) should already be unique because your documents all exist within the same Bucket. For that reason, your existing document key should be adequate for use as your new Collection document key.
Step 3: Copy Your Data
In the below code sample, we’ll use INSERT SELECT to copy the data from the Bucket into each individual Collection. We also use the existing META().id Bucket key for the Collection key.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
INSERT INTO `travel-sample`.inventory.landmark (KEY k, VALUE val) SELECT META().id k, t val FROM `travel-sample` t WHERE t.type='landmark' ; INSERT INTO `travel-sample`.inventory.airline (KEY k, VALUE val) SELECT META().id k, t val FROM `travel-sample` t WHERE t.type='airline' ; INSERT INTO `travel-sample`.inventory.hotel (KEY k, VALUE val) ELECT META().id k, t val FROM `travel-sample` t WHERE t.type='hotel' ; INSERT INTO `travel-sample`.inventory.airport (KEY k, VALUE val) SELECT META().id k, t val FROM `travel-sample` t WHERE t.type='airport' ; INSERT INTO `travel-sample`.inventory.route (KEY k, VALUE val) SELECT META().id k, t val FROM `travel-sample` t WHERE t.type='route' ; |
Step 4: Index Conversion
It’s highly likely that you”ll need to modify your existing Bucket indexes for them to be effective with the new Collection model.
The three subsections below list out the most common patterns for Bucket indexes and show you the steps to convert them into a Collection-based index.
Index Conversion: Bucket Index with a type Predicate
For a Bucket index with a specific type field filter (i.e., a partial index), you can simply re-create the new index on the specific Collection for the type.
Compare the two examples below:
| Bucket Model | Collection Model | ||||
|
|
Index Conversion: Bucket Index without a type Predicate
You can create a Global Secondary Index (GSI) index for fields that may or may not exist in the document.
For instance, an index may include the icao field, but not every document may have the icao field. For such an index, the indexer only includes the documents that have the icao field in them. If you’re using this kind of index, you may need to be more specific and create an index for the Collection where that field is being used.
Again, contrast the two code samples below between the old and new models:
| Bucket Model | Collection Model | ||||
|
|
Index Conversion: Bucket Index for a Common Field
You can also create a Bucket index without specifying the specific type – even if the field exists in multiple document types.
Consider the example where the field city exists in multiple document types – e.g., airport, landmark and hotel documents. The Bucket model only has a single def_city index, which can cover all three document types. However, under the new Collection model, you’ll need to create a separate index for each Collection for this type of index.
You can see the differences in the code samples below:
| Bucket Model | Collection Model | ||||
|
|
Step 5: Query Conversion
Because the underlying data model has shifted from a shared Bucket to an individual Collection, you’ll need to modify your existing N1QL queries.
Furthermore, after you’ve modified your queries, you need to double check that those queries use the new Collection-based indexes.
You can see the old and updated queries in the code samples below:
| Bucket Model | Collection Model | ||||||
|
The re-written query without the type filters:
|
Conclusion
That’s it! You’re done migrating from the old Bucket model to the new Scopes and Collections model in Couchbase 7.0.
I hope you find the new Collections data model to be more powerful and intuitive – and that your N1QL queries are simplified and streamlined as a result.
If you want to learn more about the Couchbase Server 7.0 release, check out What’s New and/or the 7.0 release notes.
Ready to run some N1QL queries yourself?<br/ >Give Couchbase a try today