“Apps without search is like Google homepage without the search bar.”

It’s hard to design an app without a good search. These days, it’s also hard to find a database without a built-in search. MySQL to NoSQL, Sybase to Couchbase, every database has text search support — built-in like Couchbase or via integration to Elastic — as is the case in Cassandra. Unlike SQL, text search functionality isn’t standardized. Every application needs best of the breed search, but not every database provides the same text search functionality. It’s important to understand the available feature, performance of each text search implementation and choose what fits your application need. After motivating text search, you’ll learn about the text search features you’d need for an effective, compare and contrast those features in MongoDB and Couchbase with examples.
Let’s look at the application level search requirements.
-
Exact Search: (WHERE item_id = “ABC482”)
-
Range Search: (WHERE item_type = “shoes” and size = 6 and price between 49.99 and 99.99)
-
String search:
-
(WHERE lower(name) LIKE “%joe%”)
-
(WHERE lower(name) LIKE “%joe%” AND state = “CA”)
-
-
Document search:
-
Find joe in any field within the JSON document
-
Find documents matching phone number (408-956-2444) in any format (+1 (408) 956-2444, +1 510.956.2444, (408) 956 2444)
-
-
Complex search: (WHERE lower(title) LIKE “%dictator%” and lower(actor) LIKE “%chaplin” and year < 1950)
Range searches in cases (1) and (2) can be handled with typical B-Tree indexes efficiently. The data is well organized by the full data you’re searching for. When you start to look for the word fragment “joe” or match phone numbers with various patterns in a larger document, B-Tree based indexes suffer. Simple tokenizations and using B-Tree based indexes can help in simple cases. You need new approaches to your real-world search cases.
The appendix section of this blog has more details on how the inverted tree indexes are organized and why they’re used for the enterprise search in Lucene and Bleve. Bleve powers the Couchbse full-text search. MongoDB uses B-Tree based indexes even for text search.
Let’s now focus on the text search support in MongoDB and Couchbase.
Dataset I’ve used is from https://github.com/jdorfman/awesome-json-datasets#movies
MongoDB: https://docs.mongodb.com/manual/text-search/
Couchbase: https://docs.couchbase.com/server/6.0/fts/full-text-intro.html
MongoDB Text Search Overview: Create and query text search index on strings of MongoDB documents. The index seems to be simple B-tree indexes with additional layers for the built-in analyzer. This comes with a lot of sizing and performance issues we’ll discuss further. The text search index is tightly integrated into the MongoDB database infrastructure and its query API.
MongoDB provides text indexes to support text search queries only on strings. Its text indexes can include only fields whose value is a string or an array of string elements. A collection can only have one text search index, but that index can cover multiple fields.
Couchbase FTS (Full-Text Search) Overview: Full-Text Search provides extensive capabilities for natural-language querying. Bleve, implemented as an inverted index, powers the Couchbase full-text index. The index is deployed as one of the services and can be deployed on any of the nodes in the cluster.
MongoDB |
Couchbase |
|||
Name |
Text search – 4.x |
Full-Text Search (FTS) – 6.x. |
||
Functionality |
Simple text search to index string fields and search for a string in one or more string fields only. Uses its B-Tree indexes for the text search index.Search on the whole composite string and cannot separate the specific fields. |
Full-text search to find anything in your data. Supports all JSON data types (string, numeric, boolean, date/time); query supports complex boolean expressions, fuzzy expressions on any type of fields. Uses the inverted index for the text search index. |
||
Installation |
Text search: Available with MongoDB installation. No separate installation option. |
Available with Couchbase installation. Can be installed with other services (data, query, index, etc) or installed separately on distinct search nodes. |
||
Index creation on a single field |
db.films.createIndex({ title: “text” }); |
curl -u Administrator:password -XPUT http://localhost:8094/api/index/films_title -H ‘cache-control: no-cache’ -H ‘content-type: application/json’ -d ‘{ “name”: “films_title”, “type”: “fulltext-index”, “params”: { “mapping”: { “default_field”: “title” } }, “sourceType”: “couchbase”, “sourceName”: “films” }’ |
||
Index creation on multiple fields |
db.films.createIndex({ title: “text”, genres: “text”});Before you can create this index, you’ve to drop the previous index. There can be only one text index on a collection. You need its name, which you get by: db.films.getIndexes() or specify the name while creating the index.db.films.dropIndex(“title_text”); |
You can create as multiple indexes on a bucket (or keyspace) without restriction.curl -u Administrator:password -XPUT http://localhost:8094/api/index/films_title_genres -H ‘cache-control: no-cache’ -H ‘content-type: application/json’ -d ‘{ “name”: “films_title_genres”, “type”: “fulltext-index”, “params”: { “mapping”: { “types”: { “genres”: { “enabled”: true, “dynamic”: false }, “title”: { “enabled”: true, “dynamic”: false }}}}, “sourceType”: “couchbase”, “sourceName”: “films” }’ |
||
Using weights |
db.films.createIndex({ title: “text”, genres: “text”}, {weights:{title: 25}, name : “txt_title_genres”}); |
Done dynamically via boosting using the ^ mofidier.curl -XPOST -H “Content-Type: application/json” \ http://172.23.120.38:8094/api/index/films_title_genres/query \ -d ‘{ “explain”: true, “fields”: [ “*” ], “highlight”: {}, “query”: { “query”: “title:charlie^40 genres:comedy^5” } }’ |
||
Language option |
Default language is English. Pass in a parameter to change that.db.films.createIndex({ title: “text”}, { default_language: “french” }); |
Analyzers are available in 24 languages. You can change is while creating the index by changing the following parameter.“default_analyzer”: “fr”, |
||
Case insensitive text index |
Case insensitive by default. Extended to new languages. |
Case insensitive by default. |
||
diacritic insensitive |
With version 3, the text index is diacritic insensitive. |
Yes. Automatically enabled in the appropriate analyzer (e.g. French) |
||
Delimiters |
Dash, Hyphen, Pattern_Syntax, Quotation_Mark, Terminal_Punctuation, and White_Space |
Each work is analyzed based on the language and analyzer specification. |
||
Languages |
15 languages:danish, dutch, english, finnish, french, german, hungarian, italian, norwegian, portuguese, romanian, russian, spanish, swedish, turkish |
Token filters are supported for the following languages.
Arabic, Catalan, Chinese , Japanese , Korean, Kurdish, Danish, German, Greek, English, Spanish (Castilian), Basque, Persian, Finnish, French, Gaelic, Spanish (Galician), Hindi, Hungarian, Armenian, Indonesian, Italian, Dutch, Norwegian, Portuguese, Romanian, Russian, Swedish, Turkish |
||
Type of Index |
Simple B-Tree index containing on entry for each stemmed word in each document.text indexes can be large. They contain one index entry for each unique post-stemmed word in each indexed field for each document inserted. |
Inverted index. One entry per stemmed word in the WHOLE index (per index partition). So, the index sizes are significantly smaller index. The more humongous the data set is, Couchbase FTS index is that much more efficient compared to MongoDB text index. |
||
Index creation effect on INSERTS. |
Will negatively affect the INSERT rate. |
INSERT/UPSERT rates will remain unaffected |
||
Index Maintenance |
Synchronously Maintained. |
Asynchronously maintained. Queries can specify the staleness using the consistency parameter. |
||
phrase queries |
Supported, but slow.Phrase searches slow since the text index does not include the required metadata about the proximity of words in the documents. As a result, phrase queries will run much more effectively when the entire collection fits in RAM. |
Supported and fast.
Include the term vectors during index creation. |
||
Text search |
db.films.find({$text: {$search: “charlie chaplin”}})This find all the documents that contain charlie OR chaplin. Having both charlie and chaplin will get higher score. Since there can be only ONE text index per collection, this query uses that index irrespective of the field it indexes. So, it’s important to decide which of the fields should be in the index. |
|
||
Exact phrase search |
db.films.find({$text: {$search: “\”charlie chaplin\””}}) |
|
||
| Exact Exclusion | db.films.find({$text: {$search: “charlie -chaplin”}});
All the movie with “charlie”, but without “chaplin”. |
|
||
| Results order. |
Unordered by default.Project and sort by score when you need it.db.films.find({$text: {$search: “charlie chaplin”}}, {score: {$meta: “searchscore”}}).sort({$meta: “searchscore”}) |
Ordered by score (descending) by default. Can order by any field or meta data. This sorts by title and score (descending)
|
||
| Specific language search |
db.articles.find({ $text: { $search: “leche”, $language: “es” } }) |
The language analyzer will have determined the characteristics of the index and query. | ||
| Case insensitive search |
db.film.find( { $text: { $search: “Lawrence”, $caseSensitive: true } } )
|
Determined by the analyer. Use the to_lower token filter so all the searches are case inensitive. See more at: https://docs.couchbase.com/server/6.0/fts/fts-using-analyzers.html | ||
| Limiting the return resultset. |
db.films.find({$text: {$search: “charlie chaplin”}},{score: {$meta: “searchscore”}}).sort({$meta: “searchscore”}).limit(10) |
Supports the equivalant of LIMIT and SKIP in SQL using “size” and “from” parameters respectively.
|
||
| Complex sorting |
db.films.find({$text: {$search: “charlie chaplin”}},{score: {$meta: “searchscore”}}).sort({year : 1, $meta: “searchscore”}).limit(10) |
Ordered by score (descending) by default. Can order by any field or meta data. This sorts by title (ascending), year (descending) and score (descending)
|
||
| Complex query |
Use the aggregation framework. $text search can be used in an aggregation framework with some restrictions.db.articles.aggregate(
|
As you’ve seen so far, FTS query itself is pretty sophisticated. In addition, FTS supports facets for simple grouping and counting. https://docs.couchbase.com/server/6.0/fts/fts-response-object-schema.html
In the upcoming release, N1QL (SQL for JSON) will use the FTS index for search predicates.
|
||
| Full document index | Does not support full document indexing. All the string fields will have to be specified in the createIndex call.
db.films.createIndex({ title: “text”, generes: “text”, cast: “text”, year: “text”});
|
By default, it supports indexing the full document, automatically recognizes the type of the field and indexes them accordingly. | ||
| Query Types |
Basic search, must have, must not have. |
Match, Match Phrase, Doc ID, and Prefix queriesConjunction, Disjunction, and Boolean field queriesNumeric Range and Date Range queriesGeospatial queriesQuery String queries, which employ a special syntax to express the details of each query (see Query String Query for information) |
||
| Available analyzers | Built-in analyzers only. | Built-in and customizable analyzers. See more at: https://docs.couchbase.com/server/6.0/fts/fts-using-analyzers.html#character-filters/token-filters |
||
Create and search via UI |
Not in the base product. |
Built into Console |
||
| REST API |
Unavailable. |
Available.
https://docs.couchbase.com/server/6.0/fts/fts-searching-with-the-rest-api.html https://docs.couchbase.com/server/6.0/rest-api/rest-fts.html |
||
SDK |
Text search is built-into with most Mongo SDKs. E.g. https://mongodb.github.io/mongo-java-driver/ |
https://docs.couchbase.com/java-sdk/2.7/full-text-searching-with-sdk.html |
||
| Datatypes supported | String only. No other datatype is supported. | All JSON data types and date-times.
String, numeric, boolean, datetime, object and arrays. GEOPOINT for nearest-neighbor queries. See : https://docs.couchbase.com/server/6.0/fts/fts-geospatial-queries.html |
||
| Term Vectors. | Unsupported. | Available. Term vectors are very useful in phrase search. | ||
| Faceting | Unsupported |
Term FacetNumeric Range FacetDate Range Facethttps://docs.couchbase.com/server/6.0/fts/fts-response-object-schema.html |
||
| Advanced AND queries (conjuncts) | Unsupported. |
curl -u Administrator:password -XPOST -H “Content-Type: application/json” http://172.23.120.38:8094/api/index/filmsearch/query -d ‘{“explain”: true,“fields”: [“*”],“highlight”: {},“query”: {“conjuncts”:[ { “field”:”title”, “match”:”kid”}, {“field”:”cast”, “match”:”chaplin”}]}}’ |
||
| Advanced OR queries (disjuncts) | Unsupported. |
curl -u Administrator:password -XPOST -H “Content-Type: application/json” http://172.23.120.38:8094/api/index/filmsearch/query -d ‘{“explain”: true,“fields”: [“*”],“highlight”: {},“query”: {“disjuncts”:[ { “field”:”title”, “match”:”kid”}, {“field”:”cast”, “match”:”chaplin”}]}}’ |
||
| Date range queries | Unsupported.
Needs post processing, which could affect the performance. |
Supported with FTS.
{
|
||
| Numerical range queries | Unsupported. | curl -u Administrator:password -XPOST -H “Content-Type: application/json” http://172.23.120.38:8094/api/index/filmsearch/query -d ‘{ “explain”: true, “fields”: [ “*” ], “highlight”: {}, “query”: { “field”:”year”, “min”:1999, “max”:1999, “inclusive_min”: true, “inclusive_max”:true } }’ |
Performance:
While an elaborate performance comparison is still pending, we did a quick comparison with 1 million documents from wikipedia. Here’s what we saw:
Index Sizes.
| Couchbase (6.0) | MongoDB (4.x) | |
| Indexing Size | 1 GB (scorch) | 1.6 GB |
| Indexing Time | 46 sec | 7.5 min |
Search Query Throughput (queries per second):
Couchbase Mongodb
High fequency terms 395 79
Med fequency terms 6396 201
Low fequency terms 24600 643
High or High terms 145 82
High or Med terms 258 78
Phrase search 107 50
Summary:
MongoDB provides simple string-search index and APIs to do string search. The B-tree index it creates for string search also be quite huge. Text search, it is not.
Couchbase text index is based on inverted index and is a full text index with a significantly more of features and better performance.
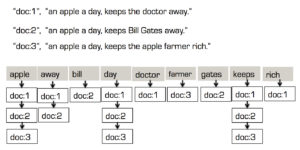
Why Inverted Index for search index?
Simple exact and range searches can be powered by B-Tree like indexes for an efficient scan. Text searches, however, have wider requirement of stemming, stopwords, analyzers, etc. This requires not only a different indexing approach but also pre-index filtering, custom analysis tools, language specific stemming and case insensitivities.
Search index can be created using traditional B-TREE. But, unlike a B-tree indexes on scalar values, text index will have multiple index entries for each document. A text index on this document alone could have up to 12 entries: 8 for cast names, one for genres, two for the title after removing the stop word (in) and the year. Larger documents and document counts will increase the size of the text index exponentially.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "cast": [ "Whoopi Goldberg", "Ted Danson", "Will Smith", "Nia Long" ], "genres": [ "Comedy" ], "title": "Made in America", "year": 1993 } } |
Solution: Here comes the inverted tree. The inverted tree has the data (search term) at the top (root) and has various document keys in which the term exists at the bottom, making the structure look like an inverted tree. Popular text indexes in Lucene, Bleve are all implemented as inverted indexes.