
When it comes to databases, data safety and performance are incredibly important. As a business you want to make sure you have disaster recovery in place and you want to make sure your database is not a bottleneck on the rest of your applications and business needs.
When it comes to performance, it makes sense to have users access applications and databases that are nearest to their location. In this scenario, how do you make sure the data exists where it needs to?
Couchbase Server is capable of replicating data between clusters, making a great disaster recovery scenario and aligning better for data locality. This is done through what’s called cross datacenter replication (XDCR) and it is actually quite easy to manage.
For the sake of this example, we’re going to be using Docker. We need to be able to create multiple clusters of Couchbase, whether that be locally or remotely on a service like AWS. Since this is only an example, Docker made the most sense.
Creating Nodes of Couchbase Server as Docker Containers
To be minimalistic, we’re going to work towards creating two Couchbase Server clusters with two nodes in each cluster. This means we’re going to need four total containers.
From the Docker CLI, execute the following commands:
|
1 2 3 4 |
docker run -d -p 7091:8091 --name couchbase1 couchbase/server docker run -d -p 8091:8091 --name couchbase2 couchbase/server docker run -d -p 10091:8091 --name couchbase3 couchbase/server docker run -d -p 11091:8091 --name couchbase4 couchbase/server |
The above commands will use the official Couchbase Docker image found in the Docker Hub.
Notice that each container will have a unique name and a different port mapping. We’re only mapping the admin port to give us something to work with from the host machine. The containers will be able to communicate along the other ports as long as they’re within the same container network, which they are.
For more information on using Couchbase with Docker, check out a previous article that I wrote titled, Using Couchbase with Docker and Deploying a Containerized NoSQL Cluster.
Now we need to create two new clusters and add nodes to them.
Clustering the Nodes to Mimic Multiple Datacenters
Let’s start by creating two new clusters. From the web browser, navigate to http://localhost:7091 and choose to create a new cluster. Follow the wizard until you’re brought to the administrative dashboard.
Now navigate to http://localhost:10091 from the web browser and choose to set up another new cluster. Again, follow the wizard until you’re brought to the administrative dashboard.
At this point in time, you have two clusters both containing a single node.
From the web browser, navigate to http://localhost:8091, but this time choose to join an existing cluster. Because we’re using Docker, you cannot use localhost when providing a host. Instead you need to use the host of your container.
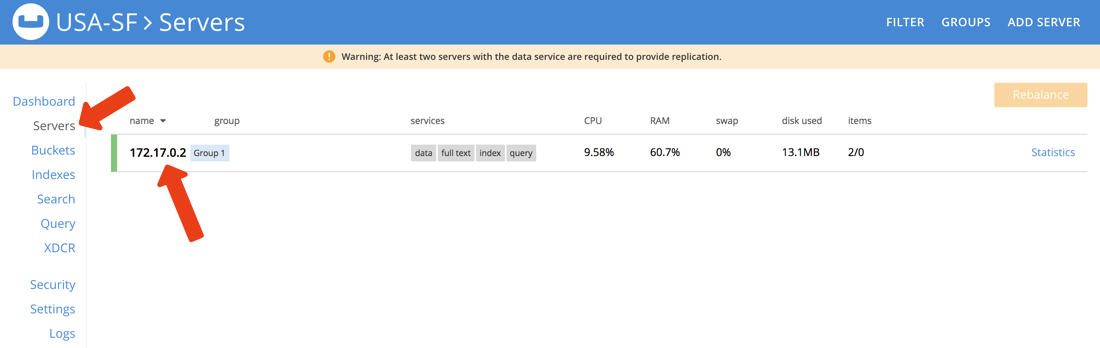
Typically, your IP would be something like 172.17.0.X, but it may vary by platform. Just make sure to join whatever cluster you created at http://localhost:7091.
To add your final node to the last remaining cluster, follow the same steps. Navigate to http://localhost:11091 from your web browser and join the cluster found at http://localhost:10091, remembering to use the container IP, not the host IP.
With two clusters available, we can worry about replicating between them with XDCR.
Configuring XDCR with Bucket Replication
The goal now is to replicate between our two data centers. Remember, we’re replicating between clusters, not nodes. Node replication within the cluster is a similar concept, but we’re interested in replicating outside the cluster.
Pick a cluster and navigate to the XCDR section of the administrative dashboard.
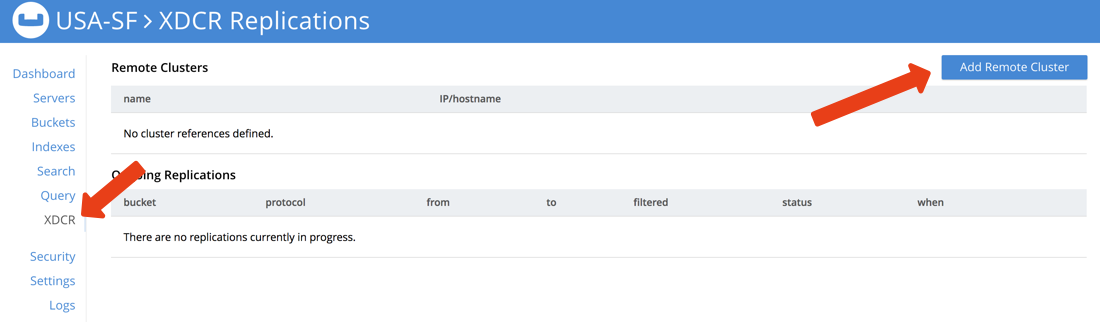
Here you’ll be able to add remote clusters and define Bucket replications. Choose Add Remote Cluster and enter the details of the cluster that you’re not currently exploring. So in my case, I’m working with my USA-SF cluster and I want to add my remote USA-NYC cluster. Remember, use the container IP, not localhost or your host IP.
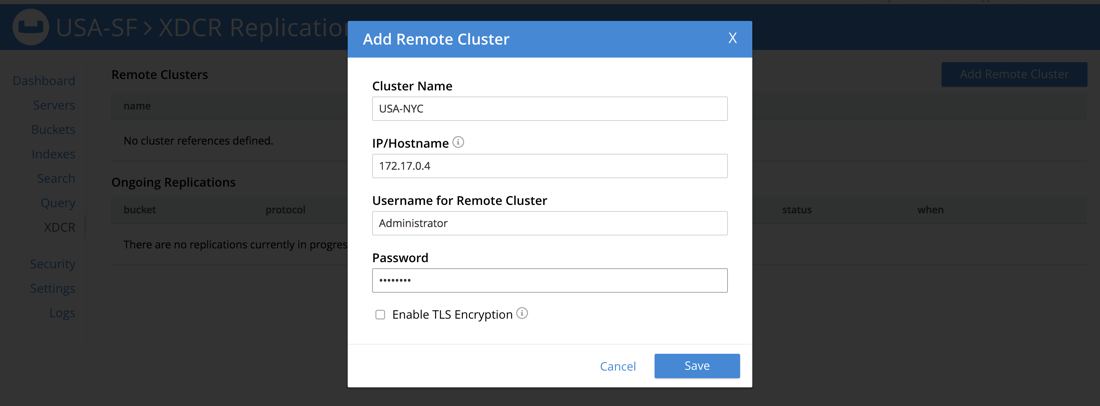
After adding the remote cluster, you’ll still need to define what you want to replicate and to where. This is a one directional replication.
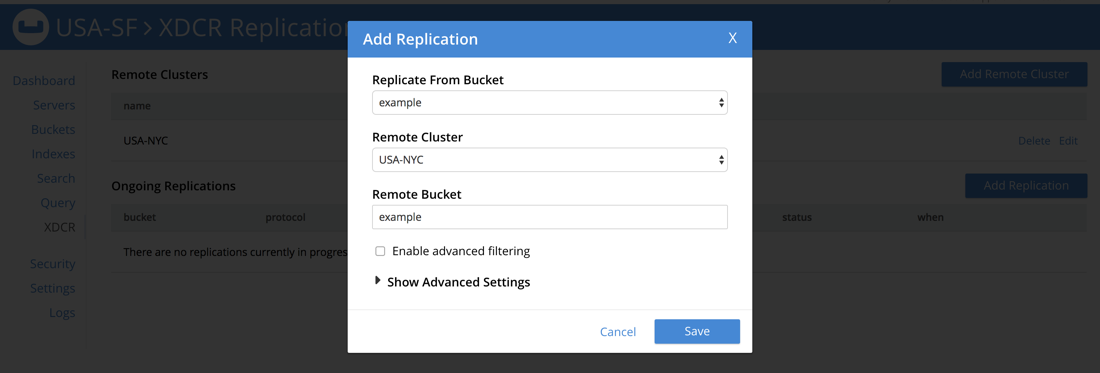
The Bucket that you wish to replicate must exist on both clusters. If the starting Bucket doesn’t exist on your destination cluster, go ahead and create it.
Once the replication is added, any document change you make on the origin cluster, let’s say USA-SF, it will show up on the remote cluster, let’s say USA-NYC. If you wish to have changes go in the other direction, follow the same steps on the other cluster or any other cluster you wish to add into the mix.
Conclusion
You just saw how to create multiple clusters of Couchbase using Docker and enabling cross datacenter replication (XDCR) on them. By having XDCR in place, you now have a better shot at disaster recovery, in addition to data locality based on user region.
For more information on XDCR with Couchbase, check out the Couchbase Developer Portal.