
Rebalance is a critical component of Couchbase architecture that allows for online cluster management operations including adding/removing nodes, online upgrades of hardware or software, and recovery after node failure.
Couchbase Server 6.5 makes rebalance more robust, more manageable, and faster. Read on to find out more about all these improvements.
Automatic Restart of Rebalance on Failure
Couchbase, like any distributed system, can experience temporary failures such as network slowness, process crash etc which can self-heal. When these failures occur they can cause an ongoing rebalance to fail. Retrying the failed rebalance is often the first course of action that users resort to, but this requires someone to be actively monitoring the rebalance.
We have now built-in retries for a failed rebalance so that you do not have to monitor and restart it manually. You can configure the number of times you want to retry as well as the retry interval for how long you want to wait before restarting the failed rebalance.
Note: The Retry Rebalance feature is off by default, so you have to turn it on explicitly (see screenshot below).
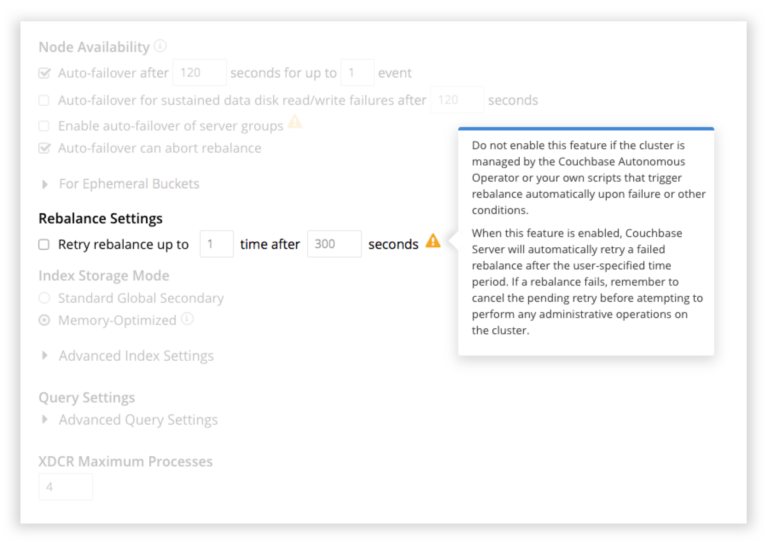
When a rebalance retry is pending, the UI will display a banner saying so. It will provide an option to cancel the retry if you want to do so. Rebalance won’t be automatically retried for some conditions such as if it was aborted by auto-failover or explicitly aborted by the user.
Auto-failover during Rebalance
Rebalance can often take some time and it is possible that a node in the cluster (whether or not involved in the rebalance) has failed. In such a situation, the node needs to be failed over in order to promote its replicas and maintain availability of data access. The Couchbase cluster manager will now abort an ongoing rebalance in order to proceed with this auto-failover. This ensures that availability is restored rapidly in accordance with the stringent uptime SLAs that applications have come to expect from Couchbase.
This behavior is ON by default as you can see in the above screenshot. If for some reason, you wish to turn it off, that can be done.
We also want to automatically restart the rebalance after the auto-failover…but that is an enhancement to look for in a future release.
Rebalance Progress Monitoring
When you initiate rebalance on a Couchbase cluster it rebalances all Services including Data Service, Index Service, Query Service, Search, Eventing, and Analytics. Rebalance of each service itself involves many different steps, with Data Service being the most complex and usually the longest part of rebalance. The Data Service rebalance processes one bucket at a time and for each bucket processes multiple vbuckets concurrently.
When a Rebalance is proceeding smoothly, the administrator should not need to monitor and observe what is going on (unless they really want to). However, if things appear stuck or slow, having visibility into the above stages of rebalance is very helpful to figure out what work was completed, what work is in progress, and what work is remaining.
The new rebalance monitoring UI mimics the above hierarchy of Services, Buckets, and Stages along with displaying how much of each bucket’s rebalance is completed (see the screenshot below).
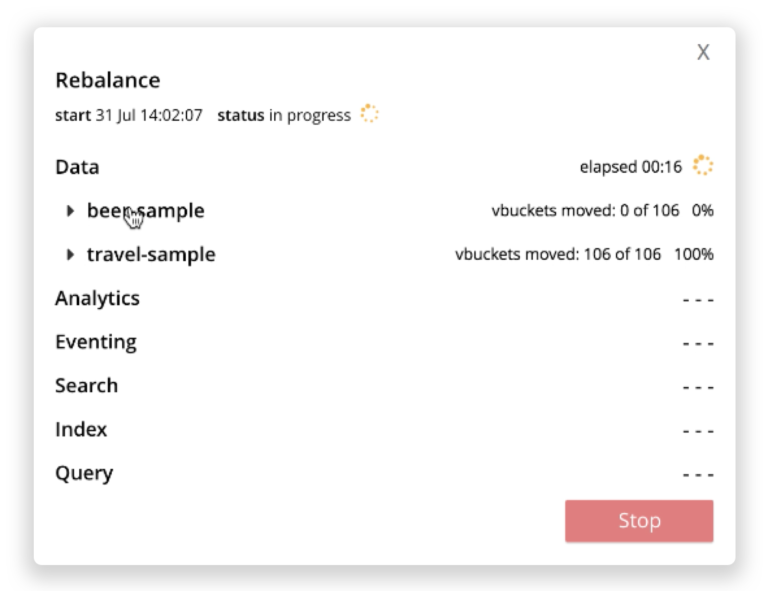
Rebalance Report
You can now get a report of the last rebalance through the REST API, e.g:
curl -X GET -u Administrator:password http://localhost:8091/logs/rebalanceReport
In addition to the information displayed in the UI, the report shows the start and end time of each of the 4 stages (backfill, move, persistence, and takeover) for each vbucket.

Faster Rebalance
Rebalance processes multiple vbuckets concurrently and each vbucket has many internal phases during rebalance — one of the main phases is backfill where most of the data copying occurs. Backfill is often the longest phase in a rebalance. The backfill phase of rebalance now has a better flow control mechanism in place. The cluster manager controls how many backfills are in progress on a node and ensures previous backfills finish persistence to disk before new ones are started.
In our internal tests we have seen very promising performance improvement with this new flow control mechanism, especially for larger data sets. It also results in lower impact to the front end application as a result of smaller disk write queues and lower memory pressure.
Next Steps
We would like to hear your feedback on these Rebalance improvements. Here are some resources for you to get started:
Download
Documentation
Couchbase Server 6.5 Release Notes
Couchbase Server 6.5 What’s New
Blogs
Announcing Couchbase Server 6.5 GA – What’s New and Improved