
There is a lot of buzz around enterprise class storage, lately. Pure Storage, a recognized leader in the space, recently gave us the opportunity to deploy Couchbase in one of their lab environments. The 8 node cluster was easily able to sustain a 100% write 1 million ops/second workload. A 1,000,000 writes/second workload was generated using our pillowfight tool run from one of the cluster nodes with the following parameters:
/usr/bin/cbc–pillowfight –U couchbase://10.21.16.121/default -m 64 -M 64 -c -1 -I 300000000 -r 100 -t 18 -B 2500
This sustained write load of 1 million writes per second from the cluster looks as follows:

This workload while impressive, didn't exercise the storage array in the slightest. In fact, it was difficult to even locate much load at all in the Pure Dashboard. The reason for this, is with pillowfight we utilized a 64 byte document exclusively. It's a perfectly reasonable workload when considering an internet of things use case with lots of small key/values written at a high velocity. What about a user profile store use case? How would a high velocity 100% write workload perform in this environment using a real world application and realistically styled user profile data?
Test Harness
For this application a rapidly deployed test harness and load generator is required and node.js is the perfect platform. The source code is available on github . First a data layer object with a create method is needed:
var couchbase = require('couchbase');
var endPoint=“10.21.16.121:8091”;
var cluster = new couchbase.Cluster(endPoint);
var endPoint=“10.21.16.121:8091”;
var cluster = new couchbase.Cluster(endPoint);
var db = cluster.openBucket(“user”,function (err) {
if (err) {
console.log('=>DB CONNECTION ERR:', err);
}
});
function create(key, item){
db.upsert(key, item, function(err, result){
if(err){
}else {
}
});
}
Next, a way to create users is needed. Utilizing the wonderful “faker.js” library to create users simplifies this task. Using faker to create a user is incredibly simple, and there are helper functions that abstract this functionality even further. By creating a simple for loop users are created with faker and passed to the data layer described above:
function loadTextUserProfile(limit){
for(i=0;i<limit;i++){
var u=faker.helpers.userCard();
connection.db.create(u.email,u);
}
}
for(i=0;i<limit;i++){
var u=faker.helpers.userCard();
connection.db.create(u.email,u);
}
}
A control loop is required to perform the ingestion into Couchbase:
setInterval(function () {
checkOps(function(done){
console.log(done);
if (parseInt(done, 10) < threshold) {
loadTextUserProfile(testBatch);
console.log(“INGEST:Added:”,testBatch);
}
else {
console.log(“INGEST:Busy:”, done);
}
});
}, testInterval
);
checkOps(function(done){
console.log(done);
if (parseInt(done, 10) < threshold) {
loadTextUserProfile(testBatch);
console.log(“INGEST:Added:”,testBatch);
}
else {
console.log(“INGEST:Busy:”, done);
}
});
}, testInterval
);
The control loop makes use of throttling logic, which is a nice feature to have for any type of performance testing and stress analysis. This function calls the rest endpoint on a node of the cluster and checks how many operations per second the cluster is currently processing:
function checkOps(opsV) {
http.get(“http://” + endPoint + “/pools/default/buckets/user”, function (res) {
var data=“”;
res.setEncoding('utf8');
res.on('data', function (chunk) {
data += chunk;
});
res.on('end',function(){
var parsed=JSON.parse(data);
opsV(parsed.basicStats.opsPerSec);
});
});
}
http.get(“http://” + endPoint + “/pools/default/buckets/user”, function (res) {
var data=“”;
res.setEncoding('utf8');
res.on('data', function (chunk) {
data += chunk;
});
res.on('end',function(){
var parsed=JSON.parse(data);
opsV(parsed.basicStats.opsPerSec);
});
});
}
Results
Just like the internet of things use case, the user profile store performance results were impressive. In a short period of time we were able to generate close to 500 million users, at a sustained workload of 400,000 writes per second.
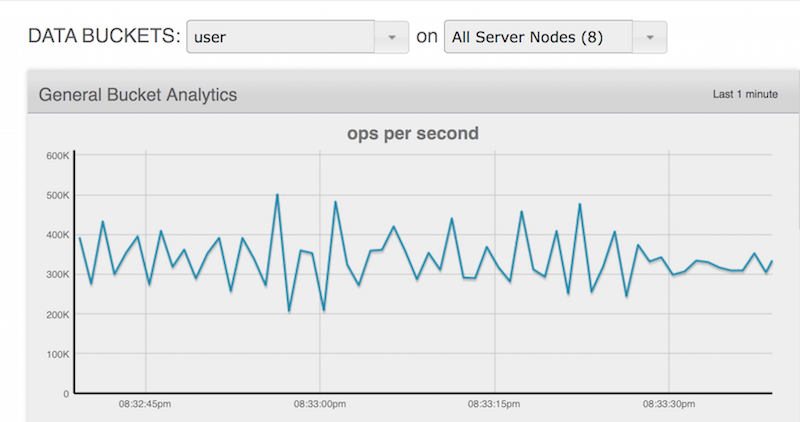
Just to keep things interesting, we used full eviction and tuned the memory to be approximately 10% of the final dataset size.

The Pure system performed perfectly. We hit CPU processing limits long before the storage system ran out of headroom:
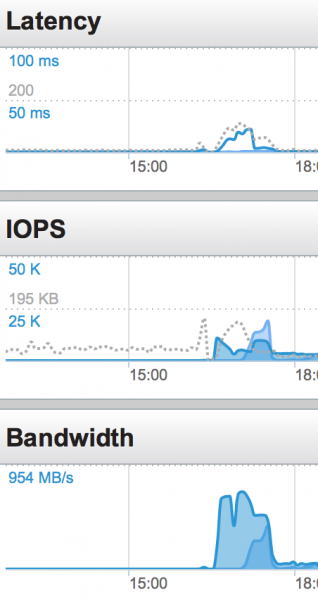
Even more impressive than the workload performance itself, is the storage footprint. This is one of the hardest aspects of storage on a distributed system. Pure's de-duplication technology is exceptional.

By using a 512 byte granularity, 4 times finer precision than competing systems, Pure is able to efficiently de-duplicate a really challenging workload. In our test environment generating users with faker, the data is random and evenly distributed. In a real world workload, the de-duplication could be expected to be even better. With the random user data set we saw a consistent de-duplication of 1.6 to 1, with 1 Couchbase replica enabled. We look forward to further benchmarking with Pure's technology in the future, and are excited about Couchbase's performance using their system.