
The reality is that databases are converging, and in the last few years, it is becoming even more difficult to point what are the best scenarios for each datastore without a deep understanding of how things work under the hood.
Postgres has been my favorite RDBMS for years, and I’m thrilled with the increasing popularity of its JSONB support. In my personal opinion, it will help developers to be more familiar with all the advantages of storing data as JSON instead of plain old tables.
However, I have seen many people inadvertently featuring Postgres 11 as “The New NoSQL” or that they don’t need any NoSQL database as they are already using Postgres. In this article, I would like to address the key differences and use cases.
If you don’t have time to read the whole article, I will summarize the most important findings in the conclusion.
Modeling Data: RDBMS and Document Databases
We are all familiar with the cost of a JOIN operation in an RDBMS at scale: If you have 1 Million users with 10 preferences each, then in order to bring this user back to the memory, assuming that you are using an ORM framework (Object-Relational Mapping) you will need to make a join with a table of USER_PREFERENCES with 10 million rows.
In a real-world scenario, users are often also associated with many other entities, which will make this scenario even worse and force developers to decide which relationships should be lazy or eager. All RDBMS nowadays already have many optimizations for the scenario above, but modeling the data the way we have been doing for the last 30 years is definitely suboptimal.
One of the reasons why RDBMS became so good at handling transactions is exactly because of the limitation of its data model: Does make sense to store an order if there are no items in it? Still, I’m forced to create a transaction to save this “single unity” spread between at least two tables: ORDER and ORDER_ITEM.
Let’s see an even more common scenario: how a user might be stored in a document database vs an RDBMS:
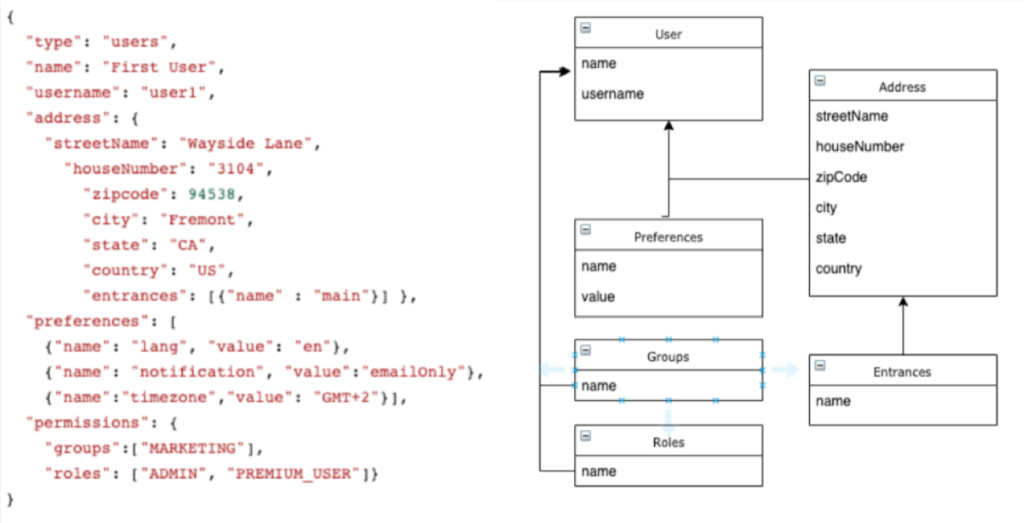
In a document database, entities with strong relationships are usually stored in a single structure. In this approach, there is almost no extra cost to load things like preferences and permissions, while in a relational model it would require at least 2 joins.
Now, let’s expand this example to a simple e-commerce use case:

In the example above, a document database wouldn’t need any JOINs to list users and products. For orders, however, it might need one or two, which is totally acceptable. The same model in an RDBMS would require at least ~12 tables:
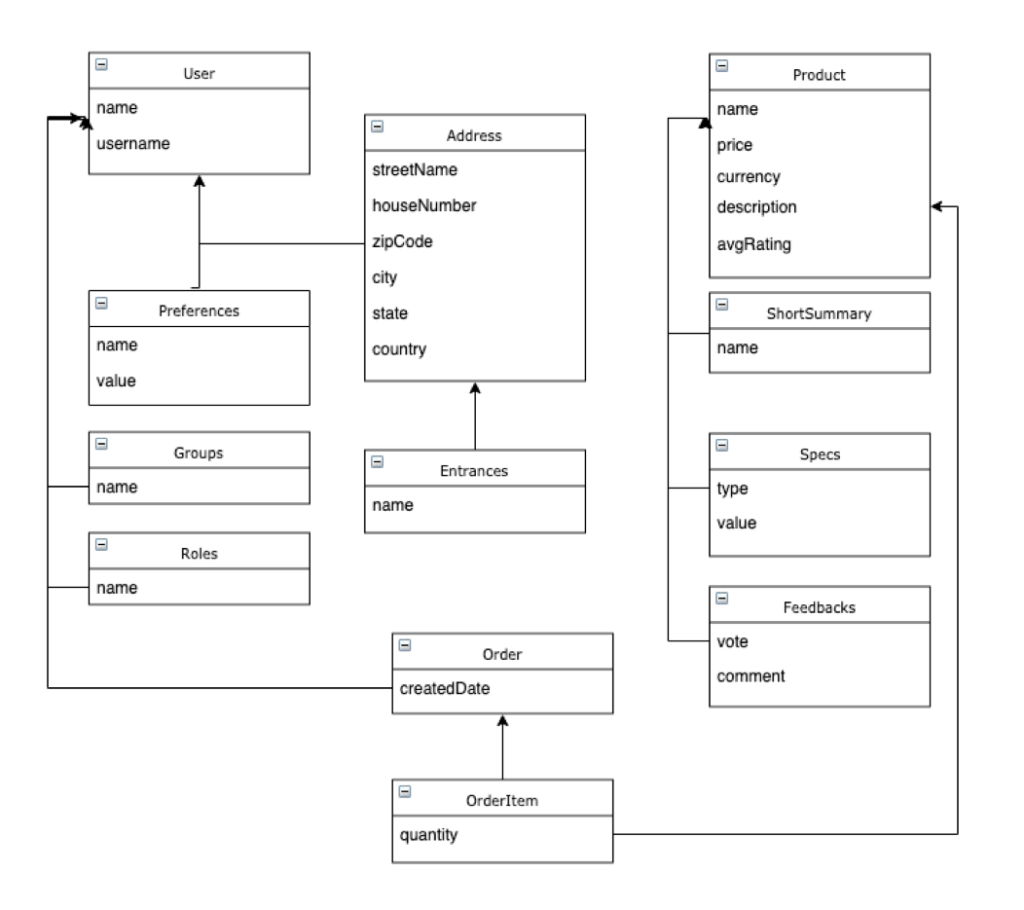
Using our example above you can notice that JOINs are essential for an RDBMS while in document database they are used less often. The same applies to transactions or cascade operations, as most of the related entities are stored in a single document.
Some of the most famous NoSQL Databases out there still don’t support JOINs properly. Fortunately, this is not the case here. Couchbase even supports ANSI JOINs:
|
1 2 3 4 5 6 |
SELECT DISTINCT route.destinationairportFROM `travel-sample` airport JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Francisco" AND airport.country = "United States"; |
I know you might have seen this explanation about data modeling for RDBMS vs data modeling for NoSQL before, but I have to stress that out as each database is optimized for a specific data model, and it will play a major role during performance tests.
The Silo Myth
As the user and the product name will rarely change, you could simply store them both in the Orders entity to avoid a few JOINS, this is a common strategy in NoSQL databases, but it is not strictly enforced:

Caching data in other entities can improve significantly your query performance at scale, but there are some trade-offs: If you have to cache this data in multiple parts of your system, whenever this data change you have to run a few updates to “keep the data in sync”.
I have seen many experienced developers using this as a drawback of Document databases, and I always have to remind them that you could have the exact same problem in an RDBMS.
Postgres JSONB Column type
In Postgres, JSONB is a special kind of column that can store JSON in a format optimized for reads:
|
1 |
CREATE TABLE my_table ( id integer NOT NULL, data jsonb); |
As stated in this video, there are some performance penalties while storing data in a JSONB column, the database has to parse the JSON to store it in a format optimized for reads, which seems to be a fair trade-off.
NOTE: Let’s ignore the Postgres’s JSON Column for now, as even the Postgres doc state that you should, in general, choose JSONB over the JSON column type.
In theory, you can even emulate a document database in Postgres by using a JSONB column for all nested entities:
|
1 2 3 4 5 6 7 |
CREATE TABLE users ( id integer NOT NULL, name varchar, username varchar, address jsonb, preferences jsonb, permissions jsonb ); |
Manipulating Data
Here is where things start getting really interesting: First of all, Postgres is not exactly following the SQL:2016 standards (ISO/IEC 9075:2016). This is not necessarily a bad thing, as the queries in this spec can easily get quite large, but it is still something to keep in mind.
I always like to highlight the standards because the NoSQL Databases have been down this road before, and today we have dozens of different languages and a significant investment in refactoring if you want to migrate from one NoSQL to another.
Hopefully, SQL++ came to the rescue, the father of SQL itself, Don Chamberlin, wrote a book about it last year. In this session, I will compare Postgress JSON functions and Operators with an implementation of SQL++ called N1QL, which is the query language we use in Couchbase.
Inserts
Inserts are what you would expect, the main difference between Postgres’s syntax and N1QL is that in the first, just a few columns of a row will contain a JSON encoded strings, while in the second one, the whole document is a JSON:
Postgres:
|
1 2 3 4 |
INSERT INTO users VALUES (1, 'First User', 'user1', '{"streetName": "Wayside Lane", "houseNumber": 3104, "zipcode": "94538", "city": "Fremont", "state": "CA", "country": "US", "entrances": [{"name" : "main"}] }', '[{"name": "lang", "value": "en"},{"name": "notification", "value":"emailOnly"}, {{"name":"timezone","value": "GMT+2"}]', '{"groups":["MARKETING"], "roles": ["ADMIN", "PREMIUM_USER"]}'); |
Couchbase:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
INSERT INTO `test` ( KEY, VALUE ) VALUES ( "1", { "type": "users", "name": "First User", "username": "user1", "address": { "streetName": "Wayside Lane", "houseNumber": 3104, "zipcode": 94538, "city": "Fremont", "state": "CA", "country": "US", "entrances": [{"name" : "main"}] }, "preferences": [ {"name": "lang", "value": "en"}, {"name": "notification", "value":"emailOnly"}, {"name":"timezone","value": "GMT+2"}], "permissions": { "groups":["MARKETING"], "roles": ["ADMIN", "PREMIUM_USER"]} }); |
Updates
Let’s start with a very simple update
Postgres:
|
1 |
update users set address = jsonb_set(address, '{state}', '"California"') WHERE address->'state' = '"CA"'; |
In the Postgres’s syntax, strings should be specified inside double and single quotes (‘“CA”’) while literals should be inside single quotes (‘false’ or ‘123’).
Couchbase:
|
1 |
update `test` set address.state = 'California' where address.state = 'CA' and type = 'users' |
In Couchbase there is no concept similar to a table, so we differentiate documents according to a “type” attribute, which in this case must be equal to “users”. All the rest of the query similar to the standard SQL, or if you came from the Java world, it is nearly the same syntax as JPA JPQL.
Let’s try a more complex example where we add a new entrance to the house, update the zip code and remove the ADMIN role from the target user:
Postgres:
|
1 2 3 4 5 6 7 |
UPDATE users SET address = jsonb_set( jsonb_set( address::jsonb, array['entrances'], (address->'entrances')::jsonb || '{"name": "backyard"}'::jsonb), '{zipcode}', '94537'), permissions = jsonb_set(permissions, '{roles}', (permissions->'roles') - 'ADMIN') |
Postgres queries can easily become overly complex if you need to manipulate the JSON. In some cases, you even have to create functions just to execute some basic updates. For me, this is a sign that we still need some improvements in the query language.
Couchbase:
|
1 2 3 |
update `test` set address.zipcode = 94537, address.entrances = ARRAY_APPEND(address.entrances, {"name": "backyard"}), permissions.roles = ARRAY_REMOVE(permissions.roles, "ADMIN") |
Even if you are not familiar with N1QL you can clearly understand what is going on in the query above, N1QL has dozens of functions just to deal with arrays.
SELECTs
As selecting data is an extensive topic, let’s break it in smaller sessions:
Querying simple data
Postgres:
|
1 2 |
select address->'city' from users where address @> '{"zipcode": "94537"}' select * from users where address @> '{"entrances":[{"name": "backyard"}]}' |
The magical @> operator allows you to easily match a key-value pair or an object inside your JSON. It indeed makes easier to match things in JSON, although there are some things you should keep in mind:
- The operator @> only supports equality comparisons
- In the second query, we match backyard in the array of entrances, but the real array is actually the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ ... "entrances": [ { "name": "main" }, { "name": "backyard" } ], ... } |
So when we search for an attribute ( zipcode, in this first case), the @> operator behaved as equals, but if we use the same operator to search in an array, it behaves as “contains”.
Couchbase:
|
1 2 3 |
Select address.city from `test` where address.zipcode = ‘94537’; select * from `test` where ANY entrance IN address.entrances SATISFIES entrance.name = "main" END; select * from `test` as t where "main" within t; //search for the occurence of “main” inside the JSON |
There is no direct correlation between the Postgres’s @> operator and a keyword in N1QL. In the queries above we use different strategies to accomplish the same things. Postgres’s syntax is shorter for very simple queries, but if you filter by two or three attributes the queries in N1QL will have roughly the same size. In this case you can also use any kind of comparison operators.
One thing that I think is a plus is that the queries using the SQL++ syntax “look more like SQL” than the SQL in Postgres itself.
Navigating through objects
Postgres:
|
1 |
select * from users where (address->>'houseNumber')::int > 5 |
Postgres uses the ->> operator to navigate through entities and the -> to convert an attribute to text. But if your attribute is an integer you have to convert id back to int.
Couchbase:
|
1 |
Select * from `test` where address.houseNumber > 5 |
In the case above you can simply navigate through entities using the “.” and the proper type is automatically inferred.
Handling missing/existing attributes
Postgres:
|
1 |
select * from users where (preferences->'randomAttributeName’') is null |
Postgres consider missing values as NULL, which is semantically wrong:
- JSON with null “randomAttributeName’’ :
|
1 2 3 4 5 6 7 8 9 |
[ { "name": "lang", "value": "en", "timezone": "GMT+2", "notification": "emailOnly", “randomAttributeName’': null } ] |
- JSON with missing “randomAttributeName’’ :
|
1 2 3 4 5 6 7 8 |
[ { "name": "lang", "value": "en", "timezone": "GMT+2", "notification": "emailOnly" } ] |
It might not be a big deal for you right now, but this differentiation helps to troubleshoot possible problems in your schema or when you need to upgrade the structures of the JSON itself.
The ? operator can check if and attribute exists, but it can only be used with top-level keys according to the docs.
Couchbase:
In N1QL there is already a proper syntax for this scenario:
|
1 |
Select * from `test` where randomAttributeName is missing |
Additionally, there is also a syntax-sugar to check if the attribute exists (same as “is not missing”):
|
1 |
Select * from `test` where randomAttributeName exists |
Indexes
Databases that allow you to store data as JSON usually don’t enforce any kind of schema, but there is an inherent problem when you add schema-flexible support: By default, you don’t know in advance which documents even have the attributes you are querying for.
This issue can be quickly addressed with the creation of proper indexes, as you can reduce significantly the number of documents scanned and sort them in some way to make it easier to find the target value. However, as we are dealing with JSON, indexes also have to deal with nested entities and arrays, which adds a significant extra level of complexity.
Naturally, creating the right index for a query is also a task that requires some thought. In fact, ~15% of the questions on Couchbase’s forums are exactly about it. Couchbase 6.5 will even come with an Indexer Recommender which will suggest an index according to a given query:
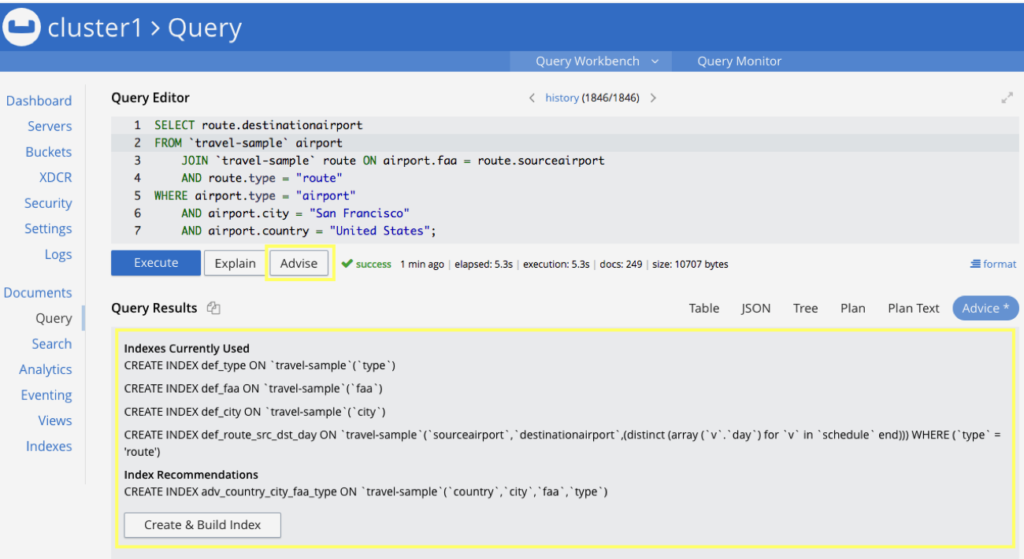
Postgres:
Indexes for JSONB data are one of the newest features in Postgres, developers are really excited about it as query performance will increase significantly while compared with the previous versions. According to the main documentation, Postgres supports two types of indexes: the default and jsonb_path_ops:
Default
|
1 |
CREATE INDEX idxusersall ON users USING GIN (address); |
This index allows you to use queries with top-level key-exists operators ?, ?& and ?| operators and the path/value-exists operator @> . Additionally, you can also index a specific field:
|
1 |
CREATE INDEX idxusers ON users USING GIN ((address -> 'entrances')); |
For GIN Index, you can only specify a single field.
jsonb_path_ops
|
1 |
CREATE INDEX idxginp ON api USING GIN (jdoc jsonb_path_ops); |
The non-default GIN operator class jsonb_path_ops supports indexing the @> operator only. It usually will result in a faster and smaller index. You can read more about it here.
Article Update:
Mark (who commented here in this article) and @postgresmen on twitter highlighted that you can create indexes with multiple fields using BTrees or GIST:
|
1 2 3 |
// for a JSONB collumn called "data" with the following content: // {"a": %s, "b":2, "c":1, "d":3} create index t1_l2 on users using btree((address->>'a'), (address->>'b'), (address->>'c')); |
Then you can use the index above with the following query:
|
1 |
select from t1 where address->>'a' = 1::text |
You can also use partial indexes with the syntax above:
|
1 2 |
create index t1_l3 on users using btree((address->>'a'), (address->>'b'), (address->>'c')) where address->'state' = '"CA"'; |
The official documentation has just 2 pages about how to index JSONB fields, just after Mark/@postgresmen heads up I could find out how to create certain types of indexes. JSONB indexing should get interesting updates in the next versions of Postgres.
Couchbase:
Indexes are actually the core of Couchbase, we currently support 7 different types:
- Primary – Indexes the whole bucket on document key
- Secondary – Indexes a scalar, object or array using a key-value
- Composite/Covered – Multiple fields stored in an index
- Functional – Secondary index that allows functional expressions instead of a simple key-value
- Array – An index of array elements ranging from plain scalar values to complex arrays or JSON objects nested deeper in the array.
- Adaptative – Secondary array index for all or some fields of a document without having to define them ahead of time.
- Partial Index – Allows you to index just a subset of your data
As you can see, indexes are something quite mature in Couchbase and far more flexible than the ones supported by Postgres JSONB. I won’t go deeper on it as this article is already quite long, I just would like to highlight two things that I personally think are really cool: Covered Partial Indexes and Aggregate Pushdowns
Covered Partial Indexes
With a combination of Covered and Partial you can create indexes just for the subset of the data you care about.
EX: Let’s say you have an online game and need to show a leaderboard by country, you also ignore inactive users or with less than 10 points. Your leader board performance is fine for all countries except China, which has 10x more players. In this case, you could create a specific index to improve the speed of your query:
|
1 2 3 4 5 6 |
CREATE INDEX `china_leader_board` ON `user_profiles`( username, points DESC) WHERE active = true and countryCode = "CN" and points > 10 |
Note that we are already keeping the points sorted, so a query like the following should be blazing fast:
|
1 |
Select username, points from user_profiles where active = true and countryCode = "CN" order by points DESC limit 20 |
Aggregate Pushdowns
Aggregation is always a difficult task for non-columnar storages, in Couchbase we allow you to create indexes to make your aggregation faster. Let’s pick the following example:
|
1 2 3 4 5 |
SELECT country, state, city, COUNT(1) AS total FROM `travel-sample` WHERE type = 'hotel' and country is not null GROUP BY country, state, city ORDER BY COUNT(1) DESC; |
This query took ~90ms to be executed, here is the query plan:

Now, let’s create the following index:
|
1 |
CREATE INDEX ix_hotelregions ON `travel-sample` (country, state, city) WHERE type='hotel'; |
If we execute the same query again it should run in ~7ms, note that in the new query plan there is no “group” step:

You can read more about Couchbase indexes here
Note: travel-sample is one of the demo databases that you can load when you install Couchbase
Performance
Although both databases are considered CP (Consistent/Partition Tolerant), Postgres is a traditional Master/Slave RDBMS, while Couchbase is optimized for fast reads/writes at scale and additional support for Monotonic Atomic Views
Unfortunately, there are just a few JSONB benchmarks published online, and in the most recent ones Postgres has been reported to be faster than Mongo for a single node instance (here also). The results are quite impressive, but worth to highlight that most of those comparisons were made against just one or two nodes, which is a scenario that favors RDBMS in general.
I don’t want to stress Couchbase’s architecture here, but as a memory-first database, your application receives the acknowledge of a successful write as soon as the database receives the request, and then your document is asynchronously replicated and written to the disk (yes, you can also change when you want to receive the acknowledge).
If we add on top of that the fact that Couchbase has a master-less architecture (your application sends the writes/reads directly to the right server), a far better indexing support, and the high scalability ( there are clients running single CB clusters in production with +100 nodes), It is clear to me which one will have a better performance at scale, the question is just “how much”.
There is no Postgres vs Couchbase benchmark yet, if you want to see one, tweet me at @deniswsrosa. In the meantime, you could indirectly compare the performance of both using this Couchbase/Mongo/Cassandra benchmark
Conclusion
I’m really excited about the increasing support of JSON in Postgres, it will definitely make developers more familiar with the benefits of storing data as JSON and consequently make Document Databases also more popular.
Many tools and frameworks in the market already offer support for JSON data, and as the adoption of Postgres JSONB increases, it should become a standard feature, which is again a good thing for every NoSQL database.
There are, however, some things to bear in mind before jumping in the Postgres JSONB:
- Complex query language: the current query language for JSONB is not intuitive, even after reading the docs it is still a little bit complex to understand what is going on in the query. PG 12 might address some of those issues with the JSON Path language, but it still will look like a mix of some other language with SQL. I would rather see Postgres adding support for SQL++.
- Limited query language: Apart from being complex, the query language is not there yet. There are missing functions to manipulate JSON data, for instance, you have to use some workarounds just to do some basic array manipulations. If you have a very dynamic JSON and need to query it in multiple ways, things can get really challenging. Seems like the main focus so far was on building the bridge between the JSON and the relational data.
- Indexing: With the new index type, queries will run much faster than before. You can additionally use BTree and Gist to cover cases not supported by GIN.
- Shallow Documentation: There are only ~6 pages of documentation talking about JSONB. Most things that I learned while writing this article were based on trial and error, StackOverflow questions, blog posts, and youtube presentations and
- Tooling: I haven’t mentioned this during the article but as it is a rather new feature, naturally some frameworks/SDKs haven’t added full support for yet. Let’s pick SpringData as an example, there are some community efforts already, but it is not a totally smooth experience. You might expect some hiccups along the way.
Some of the problems above are known-issues, a few talks/articles linked in this article even mention them. The most critical ones are already in the roadmap for the next Postgres releases.
Contrary to most popular presentations that I have watched, I don’t think that it is a good fit for very dynamic models yet, notably because querying and manipulating data is not as easy as it could be.
Where Postgres JSONB is a good fit?
Although I have pointed out some issues from my point of view, I think that it is a valuable feature and you should definitely consider using it. Here are some scenarios that I think it is a good fit:
- CQRS/Event Sourcing systems which need to be highly transactional
- Metadata
- Avoiding unnecessary joins by storing some related entities as JSONBs instead
- Whenever you have to store JSON-encoded strings but you don’t need to manipulate or query the data too often.
In the cases above, Postgres should work well, even for big deployments. Indexes might get a little big with GIN, but still manageable.
Where Couchbase is a good fit?
I have been successfully working with document databases for +4 years already, and at this point, I might be a little biased, but I think the scenarios where it can be used as a replacement for an RDBMS are much bigger than you might expect. Some of the most famous use cases are:
- User profile stores;
- Product catalogs/Shopping Carts;
- Medical history (for HealthCare);
- Contracts, insurance policies;
- Social Media;
- Gaming;
- Caching;
- …
In fact, most of the systems that do not require strong serializable transactions between multiple documents should be a good fit, that doesn’t mean that transactions are not supported at all, it is just a more relaxed version that won’t compromise the scalability of the database, especially with Couchbase 6.5!
Couchbase CE and EE really shine when you need performance at scale. You can easily create clusters with 3,5,10,50,100 nodes and still keep up with good performance and strong consistency, that is why it is currently one of the main choices for mission-critical applications. If you have time check out some of the public use cases.
All those critical use cases over the years made N1QL and indexing very solid, fast and flexible. That is why I even consider it an unfair comparison given the current state of Postgres JSONB, although is valid to show developers the gaps between an early implementation versus the best JSON support so far.
If you have any questions, comments or completely disagree with me, feel free to tweet me at @deniswsrosa
You can use normal btree functional indexes on some function which extracts data from a JSONB column.
This is very useful, e.g. if you have a value inside a json object which you want to index for exact-match operations, or other things which work with btree.
Also it’s possible to use a partial index simultaneously.
Thanks for the tip mark! I will update the article post.
Hi Mark, I have updated the content with your recommendations. Thanks a lot for the heads up.
good explanation. Thanks
I am trying to copy .json file (generated using cbexport) but getting errors. Is there any link that has good explanation on how to copy couchbase bucket to postgres JSON table please do send me
[…] Outras consultas […]