
Monitoring uncovered the resource hog. Now what?
Couchbase Server 4.5 introduced a mechanism to keep an eye on executing requests, so that slow performers could be highlighted.
This DZone article covers the subject of N1QL monitoring in great detail, but the question now is – we have the rioters, how do we check their demands?
In general terms, every database engine provides means to analyse the query plan used by a request to return data, in the form of some sort of EXPLAIN statement, but this does exactly what the word says: it explains the plan, but it does not actually say what part of the plan is misbehaving, using hard numbers.
Experienced database administrators can tell, using a mixture of, well, experience, heuristics and gut feelings how a specific plan could be improved, but this specific skill set requires a substantial amount of training, and, to be fair, a certain degree of guesswork is involved too.
Can we do better?
Enter profiling
Couchbase 5.0 introduces, among other things, the ability to collect metrics on all moving parts of individual requests.
When the feature is enabled, profiling information is returned by the request following the results document, and it is available in system keyspaces for later processing.
This metric shows the execution tree in detail, with such information as the time spent in each operator an and in each processing phase, as well as the documents ingested and digested.
Armed with this trove of data, database administrators can easily identify the costly operators in a request and address the problem, for example, creating the right index to minimize the number of qualified keys returned by the index scan.
But let’s start from the beginning.
Enabling profiling
The more frequent use of profiling is to understand why a particular statement is slow.
As such, the slow statement has already been identified and it is probably being tested in a sandbox environment – the only information needed is the culprit statement text and there’s no need to collect profiles from anything else.
Conversely, a production node may be going through a slow patch.
The culprit request has not been identified and it is important to collect all available diagnostic information immediately so that once the slow request is identified, the profiling is already available without having to rerun the offending statement.
At the request level
This can be done with the profile request REST API parameter, passed to the query service alongside the request statement – ideal for investigating individual statements.
This could be down at the lowest possible level, as exemplified by this curl example
|
1 |
curl http://localhost:8093/query/service -d 'statement=select * from `travel-sample`&profile=timings' -u Administrator:password |
Or more simply from a cbq shell session
|
1 |
cbq> \set -profile timings; |
Query Workbench enables profiling by default as we will see later.
The profile parameter takes three values: off (the default), phases, and timings.
The first, as expected, just disables the feature.
The second enables a summary of execution timings for each request phase, while the last offers the highest level of information available: full timings on a per execution operator basis.
At the service level
When profiling is required across all requests, it can be enable at node startup via the -profile command line parameter.
This takes the same arguments as the query REST API parameter, with the same meaning.
Any request that does not specify any profiling level at the REST API level takes the value of the command line argument as the selected option.
On the fly
When production clusters are showing signs of fatigue, it is possible to change query service profile setting on the fly via the /admin/settings REST endpoint, as an example
|
1 |
curl http://localhost:8093/admin/settings -d '{ "profile": "timings"}' -u Administrator:password |
This has the same effect as initializing the query service using the -profile command line parameter, however it also applies to requests that have already started, meaning that when the requests does not specify a query level profile setting, it will take the newly set level as the selected option.
It is important to know that profiling information is collected at all times – the switches above merely determine if and how much information is reported.
It is therefore possible to retroactively turn on profiling for requests that had already started, meaning that when noticing a system slowdown, a DBA can profile all already running requests, without having to resubmit any of the requests or investigate first which one is mis-performing!
Obtaining profiling information
Individual request profiling information is made available as a json subdocument detailing the execution tree.
In general terms, this is a structure in the same format and very close contents as the EXPLAIN statement output, but augmented with execution statistics.
This can be accessed by the client application, via the response document (which is useful for one off investigations), and third parties, via the system keyspaces, which is useful for instance to compare different variations on the same statement, or execution of the same statement with different values for placeholders.
From the request response
The following example shows the execution of a statement in cbq, with profiling turned on
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 |
cbq> \set -profile timings; cbq> select * from `travel-sample` limit 1; { "requestID": "eff5d221-fc0d-459f-9de3-727747368a3e", "signature": { "*": "*" }, "results": [ { "travel-sample": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" } } ], "status": "success", "metrics": { "elapsedTime": "65.441768ms", "executionTime": "65.429661ms", "resultCount": 1, "resultSize": 300 }, "profile": { "phaseTimes": { "authorize": "1.544104ms", "fetch": "1.776843ms", "instantiate": "777.209µs", "parse": "840.796µs", "plan": "53.121896ms", "primaryScan": "6.741329ms", "run": "10.244259ms" }, "phaseCounts": { "fetch": 1, "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "executionTimings": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "3.41µs", "kernTime": "10.23877ms" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 4, "execTime": "3.268µs", "kernTime": "8.651859ms", "servTime": "1.540836ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 3, "execTime": "8.764µs", "kernTime": "8.639269ms" }, "~children": [ { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "8.037µs", "kernTime": "8.591094ms" }, "~children": [ { "#operator": "PrimaryScan", "#stats": { "#itemsOut": 1, "#phaseSwitches": 7, "execTime": "6.254658ms", "kernTime": "1.609µs", "servTime": "486.671µs" }, "index": "def_primary", "keyspace": "travel-sample", "limit": "1", "namespace": "default", "using": "gsi" }, { "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "48.055µs", "kernTime": "6.766558ms", "servTime": "1.728788ms" }, "keyspace": "travel-sample", "namespace": "default" }, { "#operator": "Sequence", "#stats": { "#phaseSwitches": 5, "execTime": "1.675µs", "kernTime": "8.580305ms" }, "~children": [ { "#operator": "InitialProject", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 9, "execTime": "4.113µs", "kernTime": "8.555317ms" }, "result_terms": [ { "expr": "self", "star": true } ] }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "2.201µs", "kernTime": "8.570215ms" } } ] } ] }, { "#operator": "Limit", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "3.244µs", "kernTime": "8.621338ms" }, "expr": "1" } ] } }, { "#operator": "Stream", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 9, "execTime": "8.647µs", "kernTime": "10.225903ms" } } ], "~versions": [ "2.0.0-N1QL", "5.1.0-1256-enterprise" ] } } } |
Note that the response now includes a profile section, showing phase information such as phaseTimes, phaseCounts, phaseOperators (respectively the time spent executing each phase, the number of documents processed per phase, and the number of operators executing each phase) – the only information provided when profile is set to phases – as well as an executionTimings subsection.
From system keyspaces
Queries on system keyspaces can return request profiling information, provided profiling is turned on for said requests at the time of the query.
Here’s a quick example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
cbq> select * from system:active_requests; { "requestID": "7f500733-faba-45dc-8015-3127e305e86e", "signature": { "*": "*" }, "results": [ { "active_requests": { "elapsedTime": "87.698587ms", "executionTime": "87.651658ms", "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "phaseTimes": { "authorize": "1.406584ms", "fetch": "15.793µs", "instantiate": "50.802µs", "parse": "438.25µs", "plan": "188.113µs", "primaryScan": "75.53238ms" }, "remoteAddr": "127.0.0.1:57711", "requestId": "7f500733-faba-45dc-8015-3127e305e86e", "requestTime": "2017-10-09 19:36:04.317448352 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select * from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" } } ], "status": "success", "metrics": { "elapsedTime": "88.016701ms", "executionTime": "87.969113ms", "resultCount": 1, "resultSize": 1220 } } |
The record for the select on system:active_requests itself is sporting phase information.
If profiling is set to timings, the detailed execution tree is reported as the plan attachment, accessible via the meta() function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 |
cbq> select *, meta().plan from system:active_requests; { "requestID": "53e3b537-c781-402a-b3ae-49cd4ad4b4ac", "signature": { "*": "*", "plan": "json" }, "results": [ { "active_requests": { "elapsedTime": "58.177768ms", "executionTime": "58.163366ms", "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "phaseTimes": { "authorize": "674.937µs", "fetch": "8.26µs", "instantiate": "20.294µs", "parse": "985.136µs", "plan": "69.766µs", "primaryScan": "47.460796ms" }, "remoteAddr": "127.0.0.1:57817", "requestId": "53e3b537-c781-402a-b3ae-49cd4ad4b4ac", "requestTime": "2017-10-09 19:36:31.374286818 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select *, meta().plan from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" }, "plan": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "818ns", "kernTime": "57.105844ms", "state": "kernel" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "3.687µs", "kernTime": "56.428974ms", "servTime": "671.25µs", "state": "kernel" }, "privileges": { "List": [ { "Priv": 4, "Target": "#system:active_requests" } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "1.35µs", "kernTime": "56.439225ms", "state": "kernel" }, "~children": [ { "#operator": "PrimaryScan", "#stats": { "#itemsOut": 1, "#phaseSwitches": 7, "execTime": "19.430376ms", "kernTime": "2.821µs", "servTime": "28.03042ms" }, "index": "#primary", "keyspace": "active_requests", "namespace": "#system", "using": "system" }, { "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#phaseSwitches": 7, "execTime": "8.26µs", "kernTime": "47.474703ms", "servTime": "8.946656ms", "state": "services" }, "keyspace": "active_requests", "namespace": "#system" }, { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "638ns", "kernTime": "56.466039ms", "state": "kernel" }, "~children": [ { "#operator": "InitialProject", "#stats": { "#phaseSwitches": 1, "execTime": "1.402µs", "kernTime": "56.471719ms", "state": "kernel" }, "result_terms": [ { "expr": "self", "star": true }, { "expr": "(meta(`active_requests`).`plan`)" } ] }, { "#operator": "FinalProject", "#stats": { "#phaseSwitches": 1, "execTime": "1.105µs", "kernTime": "56.49816ms", "state": "kernel" } } ] } ] } }, { "#operator": "Stream", "#stats": { "#phaseSwitches": 1, "execTime": "366ns", "kernTime": "57.250988ms", "state": "kernel" } } ], "~versions": [ "2.0.0-N1QL", "5.1.0-1256-enterprise" ] } } ], "status": "success", "metrics": { "elapsedTime": "59.151099ms", "executionTime": "59.136024ms", "resultCount": 1, "resultSize": 6921 } } |
The information shown here in system:active_requests is also accessible from system:completed_requests, assuming that the request in question, on completion, qualifies for storage in system:completed_requests and profiling was turned on.
Note that the timing information returned by system:active_requests is current, meaning that it includes the execution timings accrued up to now: a second select on system:active_requests can therefore be used to determine the cost of a particular operator in the interval of time elapsed between the two selects.
Information provided
As shown in the following example
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#phaseSwitches": 7, "execTime": "8.26µs", "kernTime": "47.474703ms", "servTime": "8.946656ms", "state": "services" }, "keyspace": "active_requests", "namespace": "#system" } |
the execution tree document reports, for each operator, the number of documents ingested and digested (#itemsIn and #itemsOut), time spent executing operator code (execTime), waiting to be scheduled (kernTime) and waiting for services to supply data (servTime), the number of times the operator has changed state (executing, waiting to be scheduled, waiting for data), and the current state (assuming that the request has not already completed).
The operator statistics are purposely very detailed in nature: each individual measure has been known to stand out prominently during specific performance investigations, and I am not ashamed to say that they have also been gainfully used during my own debugging sessions!
To give a feeling of the sort of things that can be achieved, let’s consider phaseSwitches.
Suppose that, after gathering profiles twice, the number of phaseSwitches for a particular operator has not increased.
That particular operator may not be operating correctly: should the state be stuck in “services”, then depending on the operator, it may be waiting on the document store (for a Fetch), or the indexing service (for a Scan).
Maybe the relevant service is down or stuck?
Conversely, if stuck in “kernel”, then maybe a consumer down the pipeline is not accepting data, or the machine might be so loaded that the scheduler is not actually finding time slices for the operator.
The next section will cover some tell tale signs of some common scenarios, most likely scenarios first.
Interpreting profiles
Any operator: high kernel time
This is a bottleneck in an operator further down the pipeline.
Look for an operator with high execution or services time.
If one can’t be found, the runtime kernel is struggling to schedule operators: the query node is overloaded and adding a new one might come handy.
Fetches, Joins, Scans: high service times
This may indicate a stressed outside service.
A confirmation of this would come from a low rate of change in #itemsOut, although this requires taking the same profile more than once, which may be inconvenient (or impossible, if the request has already completed).
As an alternative, look for the symptoms described next.
Fetches and Joins: high service time per incoming document
Individual document fetches should be fast.
Dividing servTime by #itemsOut should always yield Fetch times of substantially less than a millisecond.
If it isn’t, then the document store is under stress.
To be clear – it isn’t necessarily the request being profiled that’s putting the store under stress: more likely than not it is the overall load on the service that’s being the issue.
One way to ascertain that overall load is the issue, at least, while performing stress tests, is just to reduce the number of worker clients: on an overloaded store, individual fetch times stay constant as the number of clients goes down, and only start to improve when the load gets to level that can be more easily handled.
Fetches: high number of documents ingested
A good query plan should use an index that produces only the document keys that are relevant for the request.
If the number of keys passed to the Fetch operator is much more than the final number of documents returned to the client, the index chosen in not selective enough.
Scans: high number of document produced
This is the counterpart of the previous symptom: the index chosen in not selective enough. Consider creating an index so additional predicates can be pushed to the index scan.
Joins: low ingested documents, high documents produced
Again, definitely a wrong index path: is the join supposed to produce so many results in the first place?
Filters: high ingested documents, low documents produced
Another “index chosen definitely not selective enough” indicator.
Filters: high execution time
This should never happen, and if it does, it’s more likely than not accompanied by the previous symptom.
Not only was the index not selective enough and returning too many document keys, but evaluating all the expressions in the WHERE clause for so many documents is proving to be rather expensive!
Projection: high execution time
Again, an unlikely one: the query service is struggling to assemble the result documents for the request.
How many terms do you have in the SELECT statement’s projection clause? Shave a few!
Do you have complex expressions?
Stream: high execution time
The request is struggling to convert the result in JSON form and send it to the client.
The pretty REST parameter may have been set to true in error.
The projection list may have too many terms.
Alternatively, there is a network problem, or the result documents being sent are way too large for the network to cope.
Controls
Many times, request behaviour is dependent on placeholder values, therefore it would be very useful to capture placeholder values alongside profiles.
This can be done with the controls query REST API, command line parameter and /admin/settings REST endpoint, which takes a true or false value.
Its behaviour is exactly the same as the profile setting, and can be set on a per request basis, at start up, on the fly, service wide – this too being retrospectively applied to running requests that hadn’t specified a setting.
Named and positional parameters will be reported in the request output in their own control section:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
cbq> \set -controls true; cbq> \set -$a 1; cbq> select * from default where a = $a; { "requestID": "bf6532d6-f009-4e55-b333-90e0b1d17283", "signature": { "*": "*" }, "results": [ ], "status": "success", "metrics": { "elapsedTime": "9.864639ms", "executionTime": "9.853572ms", "resultCount": 0, "resultSize": 0 }, "controls": { "namedArgs": { "a": 1 } } } |
as well as in system keyspaces (although, unlike profiles, there’s no need to access any attachment via the meta() function):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
cbq> select * from system:active_requests; { "requestID": "dced4ef6-7a31-4291-a15d-030ac67b033c", "signature": { "*": "*" }, "results": [ { "active_requests": { "elapsedTime": "69.458652ms", "executionTime": "69.434706ms", "namedArgs": { "a": 1 }, "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "remoteAddr": "127.0.0.1:63095", "requestId": "dced4ef6-7a31-4291-a15d-030ac67b033c", "requestTime": "2017-10-09 20:51:33.400550619 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select * from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" } } ], "status": "success", "metrics": { "elapsedTime": "69.62242ms", "executionTime": "69.597934ms", "resultCount": 1, "resultSize": 977 } } |
Visual profiles
A rather easy way to access detailed profiling information for individual statements, without having to do anything special, is through the Query tab in the Admin Console UI.
Query WorkBench turns profiling on by default, and upon completion of the request, timings and document counts are readily available in pictorial form, by clicking on the “plan” button.
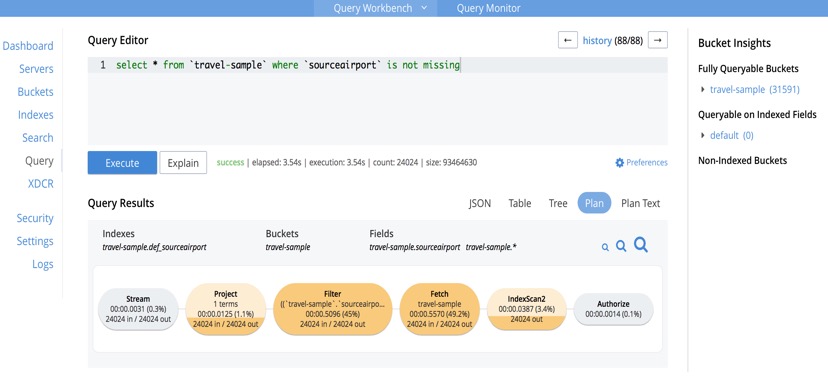
The operators are neatly colour coded by cost, and hovering over individual operators will result in copious amounts of raw timings popping up.
The Preferences allows to change profiling settings, as well as other settings such as named and positional parameters.
Profiling is much more than just profiling
Profile and controls information can be used for more detailed monitoring as well.
For instance, to find requests with any operator producing excessive amounts of documents, one could use
|
1 2 |
select * from system:active_requests where any o within meta().plan satisfies o.`#itemsOut` > 100000 end; |
(change the threshold for output documents as required).
The example is quite simplistic, and could actually be more easily done using phaseCounts, but switch the ANY clause to satisfying
|
1 2 3 |
o.`#operator` = "Fetch" and o.keyspace = "travel-sample" and o.`#stats`.`#itemsOut` > 100000 |
and presto!, the requests loading a specific keyspace are revealed.
Similarly, finding any request that used a specific value for any named parameter can be achieved with
|
1 2 |
select * from system:active_requests where namedArgs.`some parameter` = "target value"; |
(substitute “some parameter” and “target value” with the required values!)
The possibilities are endless.
One last consideration
Profiling information is held in the execution tree itself, which does use a fair amount of memory.
This in itself is not a problem, however, be mindful that when a slow running request becomes eligible for storage in system:completed_requests and profile is set to timings, the whole execution tree will be stored as well.
This, again, is not a problem in itself. It may become a problem, though, if system:completed_requests is set to log all requests, it has no limit, and all requests have profile set to timings: in this case, memory usage may grow beyond what is reasonable, because you are storing all timings for all requests ever executed since the beginning of time!
Happily, the default settings for system:completed_requests logging mean that you will not unknowingly land into trouble, and, anyway, I am not suggesting you should be thrifty with the amount of timings you log, but this is a case in which excess may be painful.
You have been warned.
Conclusions
Starting from Couchbase Server version 5.0, N1QL offers specialised tools to slice and dice execution timings in considerable depth.
Examples have been given on how to access the functionality and interpret the data collected.