We’re happy to announce that the release of Couchbase Cloud 1.6 comes with a number of key improvements, particularly in data import.
These feature improvements include Import of documents using the Couchbase Cloud Web UI with various key generation and configuration options. This provides an easy way to quickly import small datasets, typically less than 100 MB, in a variety of formats. This is an extension of the familiar cbimport tool, and it further exploits Cloud Native technologies like local S3 storage.
The new Import feature is part of a data migration strategy, from on-prem to cloud, in addition to Backup/Restore and XDCR
In this blog post, we will look at some use cases and some “gotcha”s during Import with Couchbase Cloud. This is not intended to be an exhaustive in-depth look at all the features; please refer to our excellent documentation on Couchbase Cloud for that.
Feature Overview
Let’s take a quick look at the feature list for Couchbase Cloud 1.6:
| Function | Operation |
|---|---|
| Custom Key Generation Expression – The same familiar format as cbimport tool – Or choose auto generated UUID Check the Generated Key – Paste a sample JSON doc in the UI and examine the generated Key Visually Configuration Options – Skip Documents – Limit Documents – Ignore Fields in Imported documents – Additionally CSV – Infer Field Types – Additionally CSV – Omit Empty Types |
Asynchronous and Concurrent Imports – Carry on with other activity while importing your data in the background Email notification – Get notified by email when import completes. Multiple methods to upload file – Through the web browser – Directly to S3 through cURL Local Storage of Imported Files – Re-import without reload Import Activity history – Audit your Import activity Import Log preservation – Ease troubleshooting |
The Example Dataset
To illustrate some of the features, we will use a decidedly small (just three) and decidedly contrived documents. Since Import allows you to import data from a variety of file formats, a quick refresher on what these file types are:
-
- JSON List
- A JSON list is a list (indicated by square brackets) of any number of JSON objects (indicated by curly braces) separated by commas.
- JSON Lines
- JSON lines is a file where each line has a separate complete JSON object on that line.
- CSV (Comma Separated Variables)
- The CSV format “flattens” JSON data and does not support arrays or nested values.
- Archive
- Compressed file of individual JSON documents
- JSON List
Now, let’s take a look at the three documents themselves:
Person with id 101 |
Person with id 102 |
Person with no id |
| { “id”: 101, “short.name”: “JS”, “%SS%”: “091-55-1234”, “name”:{ “first”: “John”, “full.name”: “John P Smith”, “last”: “Smith” }, “contact”: { “@email”: “john.smith@gmail.com“, “Office”: { “cell#”: “1-555-408-1234” } } } |
{ “id”: 102, “short.name”: “JS”, “%SS%”: “091-55-1234”, “name”:{ “first”: “Jane”, “full.name”: “Jane P Smith”, “last”: “Smith” }, “contact”: { “@email”: “jane.smith@gmail.com“, “Office”: { “cell#”: “1-555-408-2345” } } } |
{ “short.name”: “AS”, “%SS%”: “091-55-0000”, “name”:{ “first”: “Adam”, “full.name”: “Adam P Smith”, “last”: “Smith” } } |
The people.json File
Create a file with the above three documents.
|
1 2 3 4 5 |
[ {"%SS%":"091-55-2345","contact":{"@email":"jane.smith@gmail.com","Office":{"cell#":"1-555-408-2345"}},"id":102,"name":{"first":"Jane","full.name":"Jane P Smith","last":"Smith"},"short.name":"JS"}, {"%SS%":"091-55-1234","contact":{"@email":"john.smith@gmail.com","Office":{"cell#":"1-555-408-1234"}},"id":101,"name":{"first":"John","full.name":"John P Smith","last":"Smith"},"short.name":"JS"}, {"%SS%":"091-55-0000","name":{"first":"Adam","full.name":"Adam P Smith","last":"Smith"},"short.name":"AS"} ] |
The Data Import Process
Now that we have the data file, let’s begin the Import process. Before we begin this, I have created a bucket test with 100 MB size. This is sufficient for me to import this small dataset. A few things to note:
-
- You need to have Administrator privileges.
- The bucket should exist.
- The bucket size has to be sufficient to hold the imported dataset.
- You do not need to have a database user.
- You do not need to whitelist your IP.
Upload the File
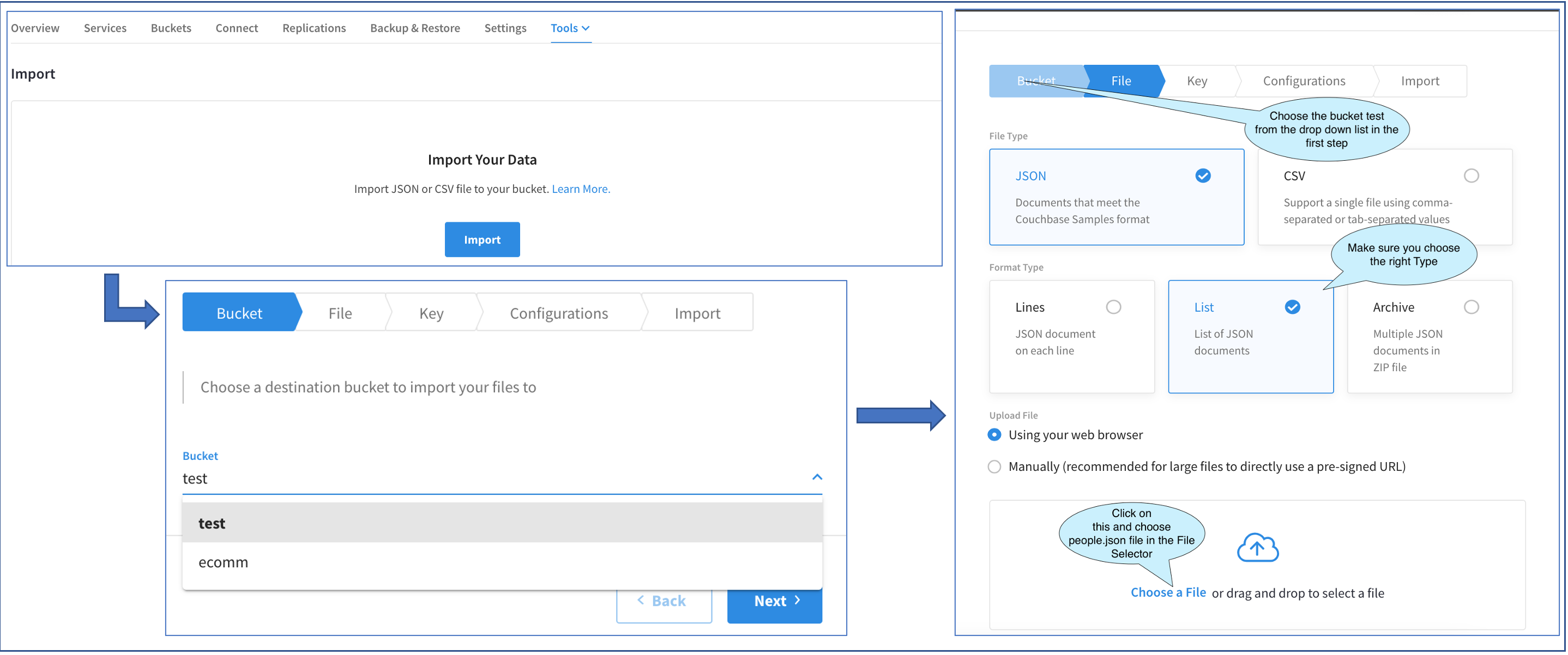
The above diagram shows the progression of three screens. Access the first Import Main UI by Cluster > Tools > Import.
Since we are performing the Import for the very first time, the main Import UI just has an Import button. Clicking on that brings out the Import Fly-out. The rest of the operations will be performed in this Fly-out.
The first screen in the Fly-out allows us to choose the bucket. I have two buckets. Let’s choose the test bucket.
The next screen asks us to choose the File Type. Our sample file is a JSON file and the file type is a LIST. After choosing that, we have a couple of options to upload the file. We could do it through the browser or upload it manually through a URL.
Typically, files less than 100 MB can be uploaded through the browser. So, let’s go ahead and choose that option. Clicking on Choose a File brings out the File Selector (not shown here). This is the standard File Selector. Let’s go ahead and choose people.json.
If the file was larger than 100 MB, we would have chosen to load manually through a URL. Clicking on that option would have brought up a text box with a cURL command, which we would have copied and executed from a terminal window on our laptop.
Irrespective of the file upload method, the rest of the process is the same.
Generate the Key
Once the file has been chosen, let’s proceed to the Key generation section. Note that at this time, the file has not been actually uploaded yet. That will happen a few steps further down.
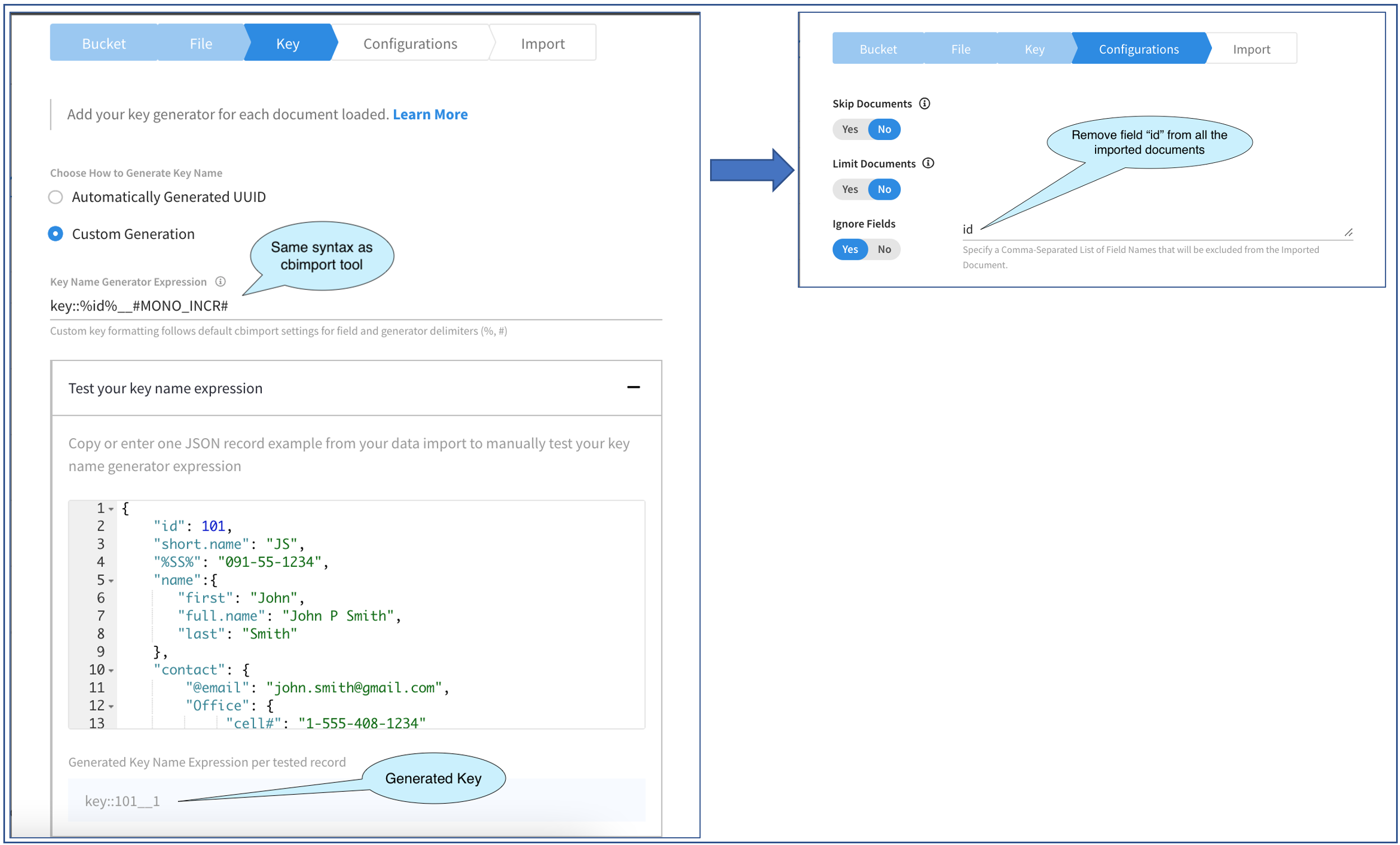
The picture above shows the progression through two screens in the Import Fly-out.
The first screen allows us to specify how the document key is to be generated. Here we are given a couple of choices: Either auto-generate the key or generate the key using an expression supplied by us. The first option is simple and can be used for small test cases where the document key is not important. Let’s go ahead and select the second option and generate the document keys to a certain pattern.
We need to specify the Expression in the Key Name Generator Expression. This is a string and follows the same syntax as that of the cbimport Key Generators. The generated key can be static text or derived from a field value in the document a generator function like MONO_INCR or UUID with any combination of the three.
A few things to note when building the expression:
-
- Field names are always enclosed in “%”
- Generator functions are always enclosed in “#”
- Any text that isn’t wrapped in “%” or “#” is static text and will be in the result of all generated keys.
- If a key needs to contain a “%” or “#” in static text then they need to be escaped by providing a double “%” or “#” (ex. “%%” or “##”).
- If a key cannot be generated because the field specified in the key generator is not present in the document then the key will be skipped.
The expression that we choose for this example is: key::%id%__#MONO_INCR#. By this we mean:
-
- Replace %id% with the value of the field “id” in the document.
- Replace #MONO_INCR# with a monotonically increasing number starting with 1.
- Treat the rest as static text in the key
This screen also provides a cool way of checking our expression syntax as well as the actual key generated by the expression.
For this, we need to paste a sample document in the JSON editor. I have done that as you can see. Of the three documents in the file, only the first two have the id field and so I was careful in choosing a document which did have the field. This validator, of course, works only with JSON documents and not a CSV document. Finally, as you can see in the picture above, I have “prettified” the JSON document. This is for convenience. This would have worked even if I had pasted the document as a single line. As we type in the expression, the generated key is shown on the bottom. It’s very interactive and allows you to play with the expressions and instantly check the generated key.
Once you are satisfied you can move on to configuration options and that’s exactly what we’ll do. This screen offers three options of which we are interested in the last, Ignore Fields. This option allows you to import all the documents in the file but without the specified fields in the document. This option allows you to specify multiple fields, delimited by commas.
In our example here, since we have made the value of id part of the document key, we really do not need that same information to be in the document as well, so let’s remove it. To do that, I have entered the string as id. Note that this is plain text and you should not enclose the field names here within “%”.
Key Generation Examples
| Key Generation Expression | Generated Key |
|---|---|
| key::%id%::#MONO_INCR# | key::102::1 |
| key::%id%::#UUID# | key::102::29ee002c-06e4-4dbf-bb5b-b2f148167536 |
| key::%id%::###UUID# | key::101::#3c671afe-fb02-48aa-a027-d74a8d38bcbc |
key::%short.name%_%%%SS%%% |
key::AS_091-55-0000 |
key::%name.full.name% |
key::Adam P Smith |
| key::%contact.@email% | key::jane.smith@gmail.com |
| key::%%%contact.@email% | key::%jane.smith@gmail.com |
| contact##::%contact.@email% | contact#::jane.smith@gmail.com |
| Tel##:%contact.Office.cell#% | Tel#:1-555-408-1234 |
Verify and Run the Import
Now that the key has been generated to our satisfaction and the data import has been configured to ignore the id field in the documents, let’s proceed to the next step: verifying and running the import.
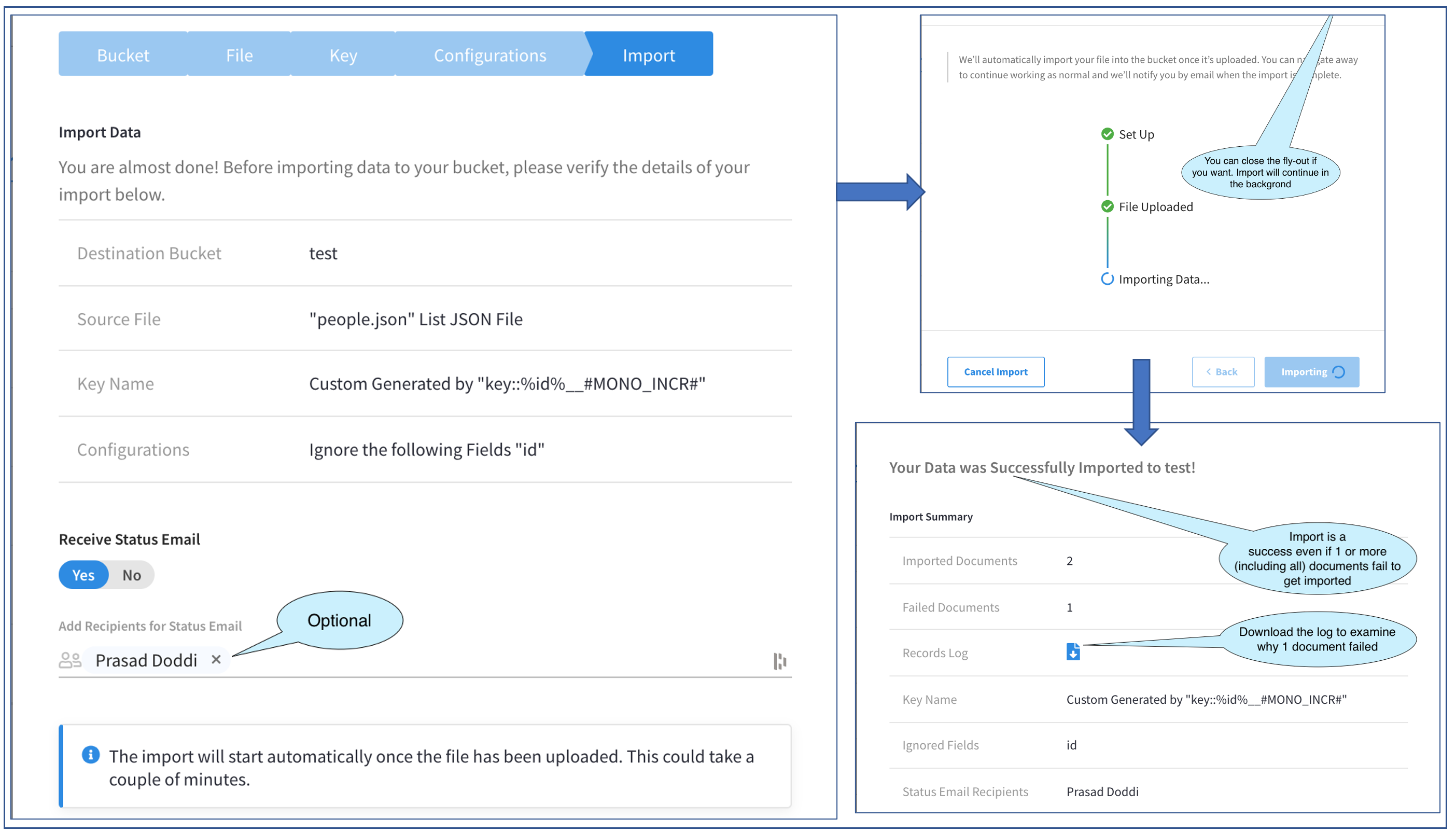
The picture above shows the progression through three screens in the Fly-out.
Let’s start with the first. This screen verifies what we intend to do and allows us to go back in case we missed something. In addition, this allows us to specify a list of users to get a confirmation email after the import is done. This is very convenient for large import files which can be run in the background while we move over to other tasks. This, of course, is optional. I have chosen to add myself to receive the confirmation email. The list of users who are displayed in the selector to Add Recipients are the Admins who are part of the Project.
The next screen begins the actual Import. The Import runs in the background and does not need the Fly-out to be open. We could close the Fly-out by clicking on the X in the top right corner (not visible in pic). We are also given the option of canceling the Import. In this example, I’ll keep it open until completion.
After completion, the third screen in the above picture is displayed. Note that you can still get to this screen from the Main Import page, and we will check that out later.
The third screen displays the Import Result. At this point in time, we would also get the confirmation email. In our example here, this screen tells us that two documents were imported successfully and one failed. The overall status is a successful import.
An important thing to note here is that the overall success of the Import does not depend on the successful data import of all, some, or none of the documents. The success of the Import process is just that the process completed without crashing.
Coming back to our example, let’s dig a little deeper into this failure of one document. To troubleshoot this failure, we are provided with a helpful button to download the Records Log and this is what we will do.
Troubleshooting with the Records Log
This is the Records Log that I downloaded. (I snipped out some lines.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Custom generator key: key::%id%__#MONO_INCR# User args: --verbose --ignore-field id ======================= 2021-06-03T01:50:07.322+00:00 (Rest) GET http://cb:8091/pools/default 200 2021-06-03T01:50:07.322+00:00 (Plan) Executing transfer plan ... 2021-06-03T01:50:07.330+00:00 (Rest) GET http://cb:8091/pools/default/buckets 200 2021-06-03T01:50:07.331+00:00 (Rest) GET http://cb:8091/pools/default/nodeServices 200 2021-06-03T01:50:07.356+00:00 ERRO: Key generation for document failed, field id does not exist -- jsondata.(*Parallelizer).... 2021-06-03T01:50:07.376+00:00 ERRO: Data transfer failed: Some errors occurred while transferring data, ... 2021-06-03T01:50:07.376+00:00 (Plan) Transfer plan failed due to error Some errors occurred while transferring data, ... 2021-06-03T01:50:07.376+00:00 JSON import failed: 2 documents were imported, 1 documents failed to be imported 2021-06-03T01:50:07.376+00:00 JSON import failed: Some errors occurred while transferring data, see logs for more details JSON import failed: 2 documents were imported, 1 documents failed to be imported JSON import failed: Some errors occurred while transferring data, see logs for more details |
The error line is: ERRO: Key generation for document failed, field id does not exist. The error says the field “id” does not exist in some document. This, of course, is right and why this document did not get imported.
Checking the Imported Documents
Now that the Import is done, and we have also performed a little bit of troubleshooting, let’s go ahead and check the actual Imported documents.
We need to see two documents with the correct Key format and the documents should not have the id field since we configured Import to ignore this field. To check, let’s bring up the Tools > Documents Viewer.
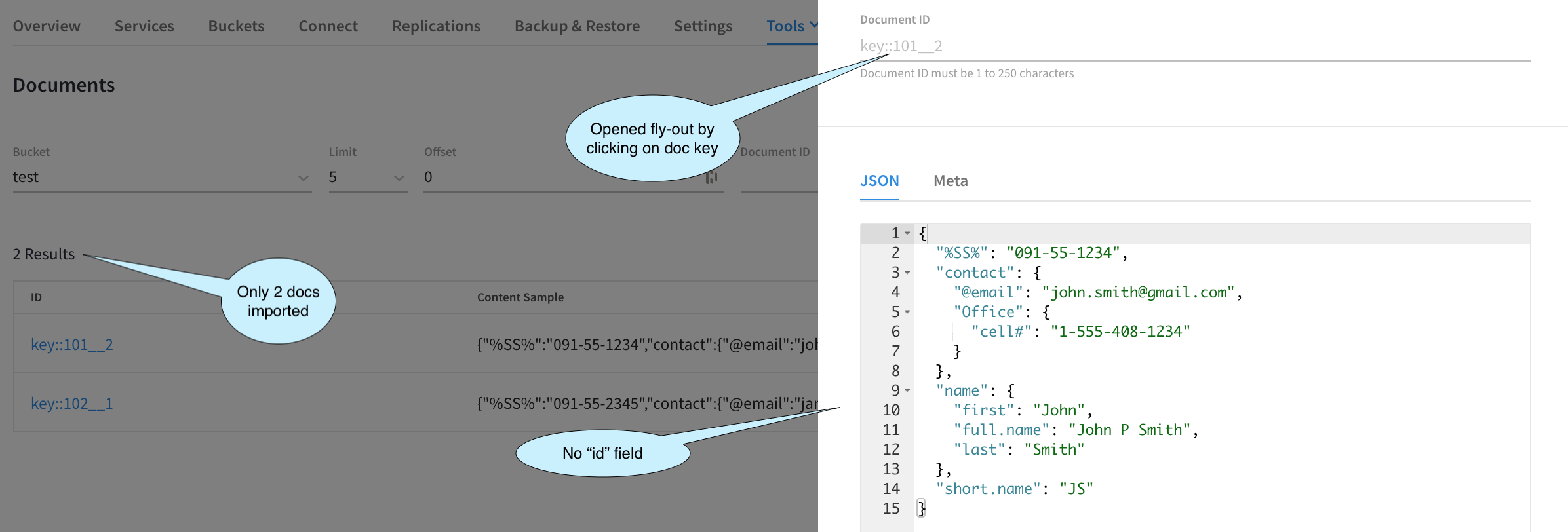
This image above just confirms that we have achieved our desired result.
Import Main Screen: Activity List
Once the Import Fly-out is closed, we are back to the main screen. Now, we see a list of all our data import activities. In this example below, I have performed a bunch of Imports and also canceled one to illustrate the Activity UI.
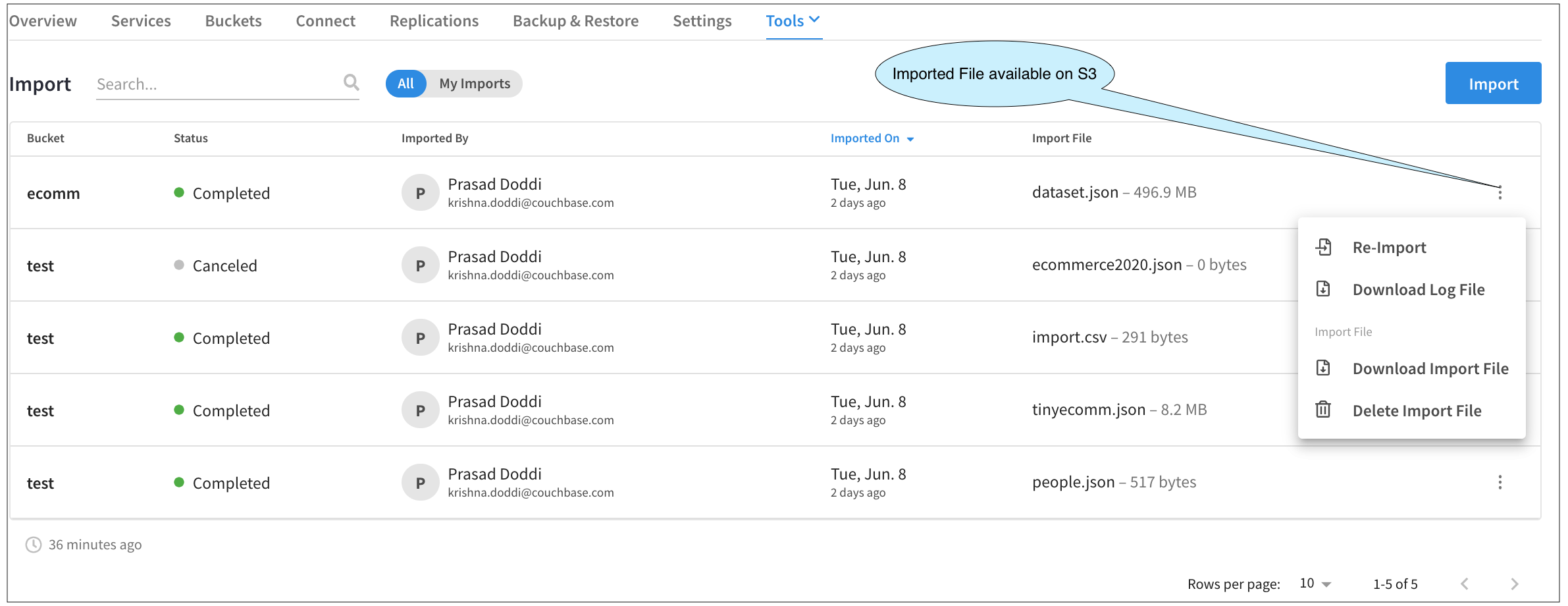
If we had closed the Import Fly-out (clicking on the X), then the status of that would show up as In Progress.
Not only does this screen act as an audit log, but we can also perform other activities as well.
Clicking on any line here brings up the Import Result Fly-out. Clicking on the three-dot buttons on each line brings up a menu from which we could Download the Log File, etc.
One of the more interesting menu items is Re-Import. Since the uploaded files are now in the cloud storage (S3 in case of AWS, for example), we can use the same file for import avoiding the initial step of uploading the file from your laptop. Clicking this will take you through the Import steps once again, but this time, allow you to re-use the imported file and keep all the selections that you had previously made, like File Type, Key Expression, etc. Of course, you could always change those. Since the process is pretty much the same, we will not go through that again in this demo.
Best Practices and “Gotcha!”s
Here are a few best practices to consider for your project, as well as a few common “gotcha!”s to avoid:
-
- Check the File Type while Importing
- Don’t mix up
LINESandLISTtype JSON Files. - Import may show up as successful but no documents or just one document (the last one) will get imported.
- Don’t mix up
- Check the generated Key whenever possible when using Custom Key Generation Expression.
- Take particular care of the field delimiter %
- For example, if you miss it and specify the custom key as
key::idinstead ofkey::%id%at the end of the data import process, you will see just one document with the key askey::id
- Make sure that your bucket is sized to hold the imported docs.
- If you have a three-node cluster and specify 100 MB as the bucket size and decide to import a 2 GB file, with long key names (like auto-generated UUIDs), then the bucket will quickly fill up with metadata.
- Remember all Couchbase Cloud Buckets are all Value Ejection only.
- Use cURL to import large files, typically anything more than 100 MB.
- Each time you want to upload through this, the cURL may be different, so don’t reuse the old cURL command.
- Check the File Type while Importing
Conclusion
This has been a closer look at some use cases and some “gotcha”s during data import with Couchbase Cloud. Check out this article to learn more about other new features in Couchbase Cloud 1.6, including the new Public API and more.
If you haven’t taken advantage of the Couchbase Cloud Free Trial yet, give it a try today!