
Note: This recommendation note was written in collaboration with Till Westmann and Mike Carey, who lead the Couchbase analytics R&D.
[Part 2 of this article by Even Pease is at: https://www.couchbase.com/blog/part-2-n1ql-to-query-or-to-analyze/]
Couchbase’s Query and Analytics Services both support N1QL (SQL for JSON). A common question is: “Which service should run my query?”. The quick answer is: “It depends on your workload”. This blog explains this answer.
A transaction is when you buy coffee and cake at the grocery store. The analysis is when the grocery store looks at all the sales data to see what day of the week, what month of the year coffee and/or cake sells more – so they can plan the inventory, sales, and prices.
Every business does these three things in a cycle or a spiral [The Goal].
- Run the business process to deliver products or services to the customers.
- Analyze the business to determine what to change and what to change to.
- Make the change happen.
In modern day business, each step requires applications perform the steps.
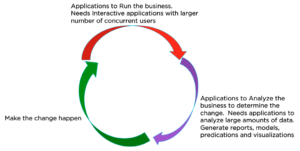
The Query Service is used by the applications needed to run the the business; it is designed for large number of concurrent queries, each doing small amount of work. In the RDBMS world, this workload is called the OLTP workload.
Applications or tools used for analysis have different workload characteristics. These typically use the Analytics Service; it is designed for a smaller number of concurrent queries analyzing a larger number of documents. In the RDBMS world, this workload is called the OLAP workload.
Let’s drill down into details into these two services.
| Query Service | Analytics Service |
| Tutorials | |
| https://query-tutorial.couchbase.com/tutorial/#1 | https://sqlplusplus-tutorial.couchbase.com/tutorial/#1 |
| High Level Comparison | |
| Used for data manipulation within application logic | Used for reports, analysis (historical, interactive), dashboards |
| Short queries
— Relatively simple SQL — Typically involving small amounts of data |
Longer operations
— Complex SQL with analytics — Typically involving larger amounts of data |
| Run SELECT, INSERT, UPDATE, DELETE, MERGE for operational applications | Run SELECT for analysis |
| Random Updates
— Update few documents per query |
No Updates
— Changes ingested from Data Service |
| Millisecond to a second latency,
high throughput (10-1000 qps), performance goal is queries/second |
Second to minutes response time,
<1-10 queries per second, performance goal is seconds/query |
| Large number of Indexes | Fewer indexes |
| Developer written queries; generated queries are well known | Ad-hoc queries; complex reports, dashboards, BI workload |
| Queries execute on a single query node using the distributed index and data infrastructure | Queries execute on all analytics nodes using its distributed compute, index and data infrastructure |
| Technical Comparison: Architecture | |
| Queries run in SMP mode, throughput is scalable by adding new query nodes | Queries run in MPP mode, can handle larger data or reduce query execution times by adding new analytics nodes |
| Technical Comparison: Optimizer | |
| Nested loop join by default
Hash join via query hint |
Parallel hash join by default,
(Index-)Nested loop join or broadcast join via query hint |
| Technical Comparison: Indexes | |
| Global secondary indexes | Local secondary indexes (co-located with data partitions) |
| Uses Memory Optimized Indexes; standard secondary indexes (Plasma) | Log-structured Merge Tree (LSM) based secondary indexes |
| Support for both covered and non-covered index scans | Non-covered index scans |
| Can use full text index for queries (6.5) | |
| Technical Comparison: Execution | |
| Most queries are prepared once and executed many times | Ad-hoc and exploratory queries |
| SDKs use the prepare-execute model based on a ad-hoc flag | SDKs offer ad-hoc and parameterized queries |
| Most operations are done in memory; only when an index scan returns large data is it written to the disk backfill | Bounded-memory operations on large data (larger than cluster memory) with graceful spilling as needed |
| Single node query parallelism | Multi-node partitioned-parallel join, sort, aggregate, and grouped aggregate operators |
| Expects a single (possibly RAIDed) storage device | Un-RAIDed use of multiple storage devices |
| Performance isolation via covering indexes that support scan, grouping, and aggregation operations on Index Service nodes | Performance isolation for all queries via shadowing of data on Analytics Service nodes |
| Technical Documentation | |
| https://docs.couchbase.com/server/6.0/n1ql/n1ql-language-reference/index.html | https://docs.couchbase.com/server/6.0/analytics/introduction.html |
| Technical Information | |
| https://www.couchbase.com/products/n1ql | https://www.couchbase.com/sqlplusplus |
| Technical Books | |
| https://www.couchbase.com/blog/a-guide-to-n1ql-features-in-couchbase-5-5-special-edition/ | https://resources.couchbase.com/sql_tutorial
https://www.amazon.com/SQL-Users-Tutorial-Don-Chamberlin/dp/0692184503/ |
- [The GOAL]: The Goal: The process of ongoing improvement. https://www.amazon.com/Goal-Process-Ongoing-Improvement/dp/0884271951/ref=sr_1_1?keywords=the+goal&qid=1547969233&sr=8-1
- Systems of Engagement for Customer Jobs: https://marketing.cioreview.com/cxoinsight/systems-of-engagement-for-customer-jobs-nid-24677-cid-51.html
- Part 2 of this article by Even Pease: https://www.couchbase.com/blog/part-2-n1ql-to-query-or-to-analyze/