
N1QL enhancements have come to Couchbase. N1QL is one of the flagship features of Couchbase Server. The release of Couchbase Server 5.0 further bolsters N1QL with a range of enhancements.
Many of these enhancements have been covered in previous blog posts (such as Nic Raboy’s post on performance enhancements). This post won’t cover all the N1QL enhancements. Check out What’s New? in Couchbase for the full scoop.
Important notes: To follow along, you can install Couchbase Server 5.0 on your local machine. You can also explore some of these N1QL Enhancements without even installing Couchbase Server by checking out the 10 minute online tutorial. Also, this blog is being written with a release candidate build of Couchbase Server that may differ slightly from the actual release.
N1QL Enhancements for RBAC
One of the biggest new features in Couchbase Server 5.0 is the built-in Role Based Access Control (RBAC). For the full story, you can check out previous blog posts on RBAC.
But, from a N1QL enhancements point of view, there are two keywords you should know about: GRANT and REVOKE.
The documentation covers it well, but here’s a quick example. I’ll create a user “myuser”, and give that user only one role: Data Reader on the “travel-sample” bucket.
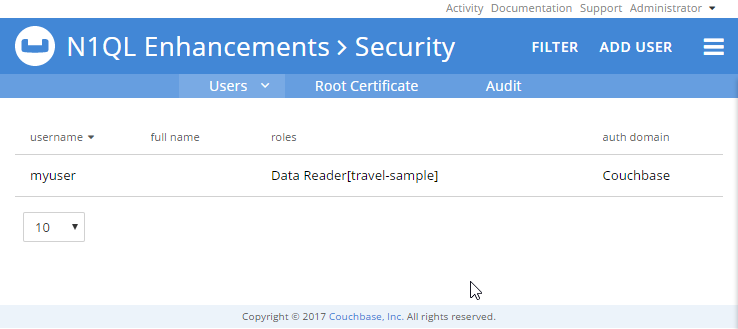
I could edit that user in the UI to give them Data Writer.
GRANT and REVOKE
But here’s how to do it with a GRANT N1QL command:
|
1 2 3 |
GRANT data_writer ON `travel-sample` TO myuser; |
After, you can navigate over to the “Security” section of Couchbase Console to see that “myuser” has the new permission.
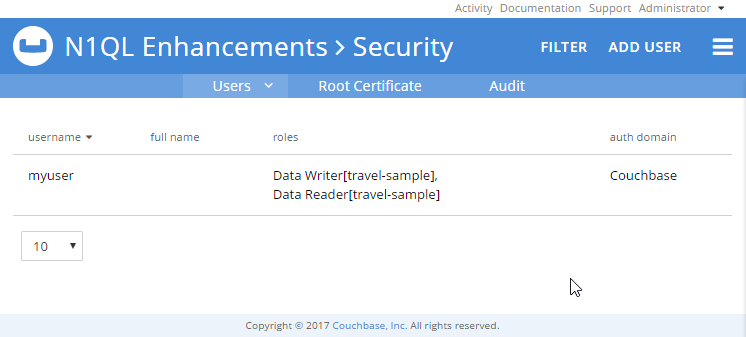
You can find all of the role names (like “data_writer”) in the 5.0 documentation.
REVOKE works the same way, but in reverse.
system keyspaces for RBAC
There are a couple of new system keyspaces that are part of the 5.0 N1QL enhancements. SELECT * FROM system:user_info will return information about each user and their roles.
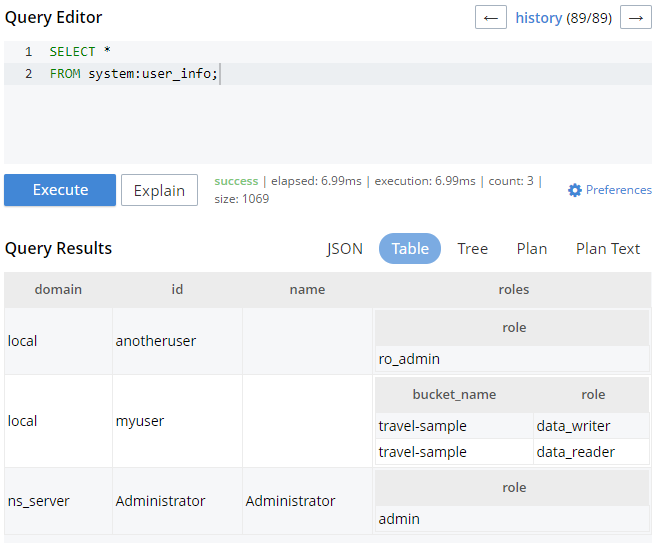
You can use SELECT * FROM system:applicable_roles keyspace to get a list of all the role information.
Note that only Adminstrators and users with a “Query System Catalog” role themselves have access to these keyspaces.
curl
As Isha blogged about earlier, you can now use a CURL function from N1QL to query external JSON data. There are definitely security implications when using CURL, so make sure to read the full N1QL CURL documentation before you decide to use this N1QL enhancement.
Before I can use CURL, I have to add a URL to a whitelist. On Windows, this is done by creating a file in the /var/lib/couchbase/n1qlcerts folder (I had to create the n1qlcerts folder myself too) called curl_whitelist.json. The full default path for your reference is: C:\Program Files\Couchbase\Server\var\lib\couchbase\n1qlcerts\curl_whitelist.json.
I created a file with a single URL entry (swapi.co is the Star Wars API):
|
1 2 3 4 |
{ "all_access": false, "allowed_urls": ["https://swapi.co"] } |
Then, you can use the CURL function from with a N1QL query to retrieve JSON data. You could retrieve a single planet, for instance, with https://swapi.co/api/planets/3/, or you could retrieve all the planets (which is what I did):
|
1 2 |
SELECT p.name, p.climate, p.residents FROM CURL("https://swapi.co/api/planets/").results as p; |
That endpoint returns 10 planets at a time. I’m narrowing it just to the results field, and to the name, climate, and residents.
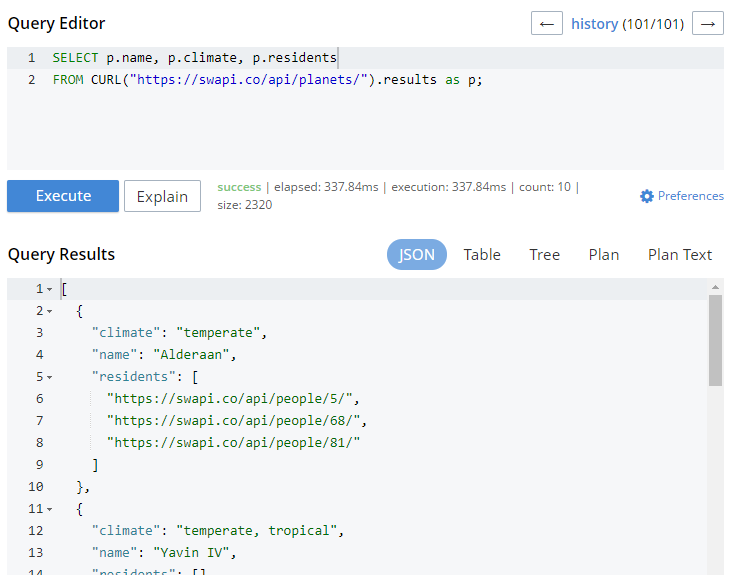
Note that CURL to a query also introduces other issues: you are yielding performance and reliability to the external data source. Also note that you can use CURL on Couchbase Server’s own REST API, which opens up a lot of interesting possibilities.
Indexes
As always, good indexing is vital to getting optimal performance from your N1QL queries. There are a lot of index options in Couchbase Server, which I won’t cover in this blog post. Definitely check out this blog post from Prasad Varakur and also look at some of the optimizations that have been added to Couchbase in version 5.0.
For this post, I’m just going to touch on the new adaptive indexes and equivalent indexes.
Adaptive Indexes
In previous versions of Couchbase, if you wanted to index combinations of fields, you had to create an index for each combination. For example, if I plan to write queries that check “type” and “name” field together or the “type” and “age” field together, that would require two compound indexes: one for type,name and one for type,state.
Consider this query:
|
1 2 3 4 |
SELECT l.* FROM `travel-sample` l WHERE l.type='landmark' AND l.state='California'; |
In the default travel-sample bucket, the type field is indexed, but not the state. This query works, but notice how flat the query plan is:
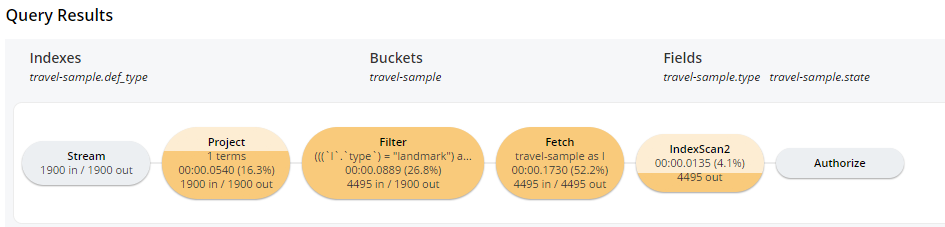
Also notice that the “fetch” and “filter” steps have to process almost 4500 documents.
Adaptive indexes make it easier to write indexes that better support adhoc querying. They can be used to index specified fields or all fields of a document.
A new keyword introduced by this round of N1QL enhancements is SELF. It can create an adaptive index on all fields in all ‘landmark’ documents in the travel-sample bucket like so:
|
1 2 3 |
CREATE INDEX `ai_n1ql_enhancements` ON `travel-sample`(DISTINCT PAIRS(SELF)) WHERE type = 'landmark'; |
You can also specify individual fields you want to index instead of SELF.
After creating this index, run the above SELECT query again.
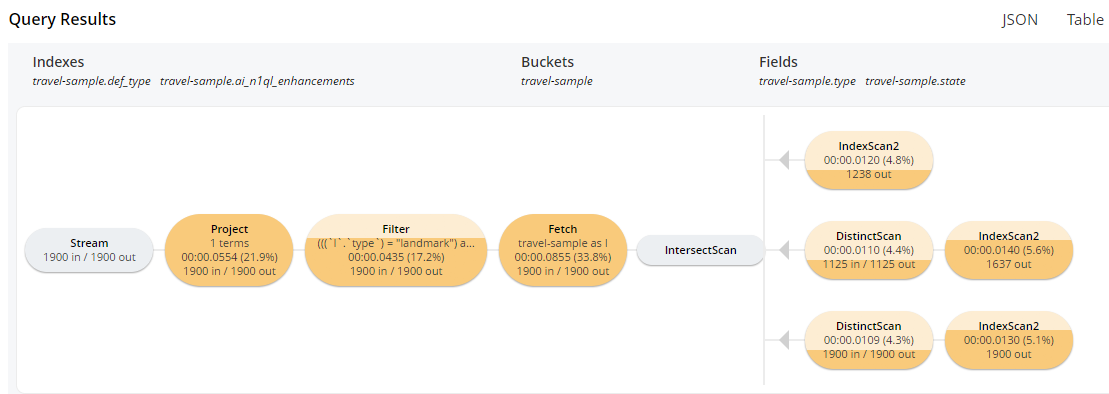
Notice the extra index scanning that’s occurring to accommodate the state field that it’s querying on. Also notice that “filter” and “fetch” are working through fewer documents: only 1900. With the relative small size of the “travel-sample” bucket, this is an overall small savings. With a real bucket containing millions of documents, the time saved can be significant.
Further, as your queries grow more complex, adaptive indexes will save you work while still giving you a performance boost.
Index Replicas
If you are making heavy use of N1QL in your application, you may want to create multiple indexes that get distributed across your cluster. These N1QL enhancements can improve performance, load balancing, and availability.
Until Couchbase Server 5, the way you did this was to create multiple identical indexes with different name. As Venkat covered in this earlier blog post on index replicas, there are some drawbacks to that.
So, in Couchbase Server 5, index replicas have been introduced. When creating an index, simply use a num_replica setting to specify how many replica indexes you want to create.
Here’s an index on the state field that I was using earlier in the “travel-sample” bucket. In this case, I’m going to replicate it twice.
|
1 2 3 4 |
CREATE INDEX `ix_state` ON `travel-sample`(state) WHERE state IS NOT MISSING WITH {"num_replica":2}; |
Note that in order for this to work, you’ll need at least three nodes running the index service (1 for the index, 2 for the replicas).
After running the above query (on a 3 node cluster), click “Indexes”. You should see “ix_state” show up 3 times on three nodes. Two of them are marked “replica”.

You can also specify the exact nodes you want the replicas on by specifying IP addresses in CREATE INDEX.
Couchbase will take care of the rest for you. Index replicas will be used for incoming queries.
If you’re not new to Couchbase, check out this guide on transitioning from “equivalent indexes” to index replicas.
For more details, definitely check out Venkat’s blog post on index replicas and the Couchbase Server 5.0 documentation on index replication.
Monitoring
The most difficult task in writing N1QL queries is making sure they are efficient and performant. To that end, Couchbase Server 5.0 has introduced a number of features to help you monitor and profile your queries.
Way back in March, I wrote about the new query plan visualization. I also wrote about the new system keyspaces for monitoring queries.
You can get the full story on the Monitoring N1QL Queries documentation page.
For this post, I just want to do a quick refresher. If you click the “Plan” button in Query Workbench, you’ll see a graphic representation of the query plan. You can get a visual guide to which parts of the query take the most time. For instance, the query plan for the above SELECT query:
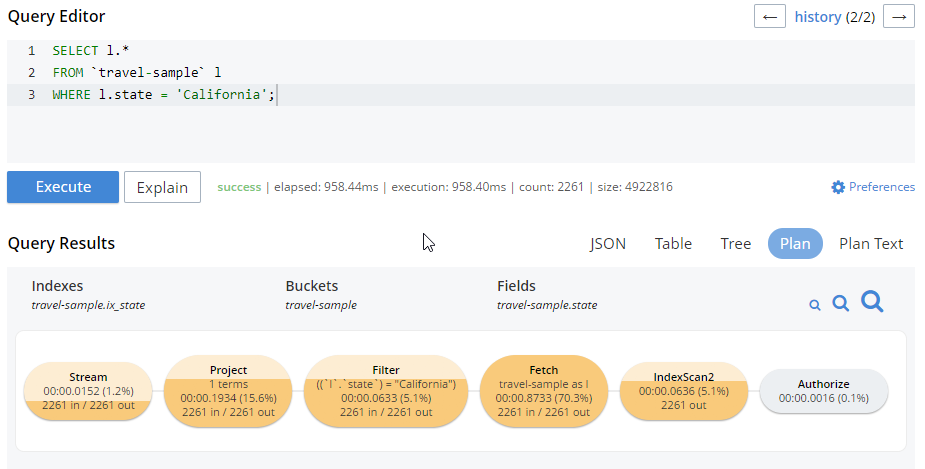
There are a couple more N1QL enhancements to remind you about as well. Two new system keyspaces: system:completed_requests and system:active_requests. These keyspaces contain information about queries that have run or are currently running: how much time they take, errors, which nodes they run on, and so forth. A quick example:
|
1 2 |
SELECT r.node FROM system:completed_requests r; |
Since I have index replicas, this query could have run on different nodes. The results show that they did:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[ { "node": "10.142.173.101:8091" }, { "node": "10.142.173.101:8091" }, { "node": "10.142.173.103:8091" }, { "node": "10.142.173.103:8091" }, // ... etc ... ] |
Be sure to check out the other tooling updates in Couchbase Server 5.0. It’s not just N1QL that’s getting enhancements.
Summary
N1QL is one of Couchbase Server’s major strengths, and Couchbase is committed to creating valuable N1QL enhancements.
If you’ve not used N1QL yet, why not try the 10 minute online tutorial today?
Got questions or comments? Find me on Twitter @mgroves or email me matthew.groves@couchbase.com.