
Scale out Full Text Search in Couchbase Server 4.5 Beta
Couchbase Server 4.5 includes a new service, full text search (FTS) . In this blog, I’ll talk about how FTS scales out across nodes, how to replicate indexes, and how it behaves in a rebalance.
Since the Couchbase Server 4.5 Developer Preview released, the FTS team has been busy. The beta release of Couchbase Server 4.5 not only squashes a lot of FTS bugs, it also includes many big FTS improvements:
- 12x faster indexing performance
- better statistics
- support for authentication and role based access control
- audit logging of administrator events
- support for partial results
The most notable new search feature in the 4.5 beta is the ability to run the FTS service across multiple nodes. You can try it out today with the beta, and what you read here will still apply when Couchbase Server 4.5 goes GA.
Let me get the disclaimer out of the way right now: FTS will remain a developer preview in the GA version of Couchbase Server 4.5, so don’t run it on a production server please. There’s a lot of really great functionality in FTS but we haven’t yet ticked off all the performance and system testing check boxes on our to do list. On the plus side, that gives us a chance to address some of the feedback we’re getting from early test users. (Got feedback? Feel free to email me directly at will dot gardella at couchbase dot com)
Ok, let’s get to the good stuff. You can use the search service to index and search text in your Couchbase documents without relying on a third party search package. The new search service joins the data, index, and query services and can be managed like other services for the purposes of multi-dimensional scaling (MDS). Note that unlike N1QL, the search service does both full text query and indexing in a single service.
Distributed Search Service – Under the Hood
For the most part, distributed search indexes “just work”: the Couchbase Full Text Search service takes advantage of new hardware as you add nodes, and full text indexes are failed over and rebalanced along with the data service. This section talks about the mechanisms that enable this, which you usually don’t need to know as a user but you will sometimes encounter, as in partial search results (touched on later).
From the start, full text search was designed to distribute text indexes across nodes, in very much the same way that the data service distributes data in buckets. If you understand Couchbase Server’s buckets and vBuckets, you’ve got a good mental model for understanding this. The bucket is a logical unit of data containment that is easy to work with, and the vBucket is a physical portion of the data that’s in a bucket, that lives on a specific node on a cluster. When you turn on replication on a bucket, Couchbase Server creates copies of all the necessary vBuckets that make up that bucket. Couchbase Server also makes sure that the layout of those vBuckets is optimal, which is itself a complex topic but for now, you can just think of it as balancing the locations of the vBuckets so that they are spread evenly across nodes.
FTS works similarly. Full text indexes are automatically divided into fragments called pindexes, which is short for “partitioned indexes” or “physical indexes”, depending on who you ask. Like a bucket, a full text index is a logical concept. The pindex is the physical implementation of the index, just like the vBucket is the physical implementation of the bucket.
Pindexes are physically distributed across the Couchbase nodes that run the search service, however many that might be. In the developer preview, it was a single node but that restriction has been lifted in the Beta. In the examples below, we’ll use just two nodes to keep it simple.
Adding a search node
Time to get hands on. If you have Couchbase Server 4.5 Beta or newer, you’re all ready to go. You’re going to need to set up more than one node, so get a VM ready. For this example, I’m going to use a couple of Windows Server 2012 VMs.
Let’s go ahead and start with a single node running the search service. We’ll create a simple index on the travel-sample bucket’s hotel documents. If you don’t have the travel sample installed, you can get it by clicking Settings > Sample Buckets and then checking the box.
For the purposes of this demo, any full text index will do. I created an index on type=”hotel” (don’t forget to disable the default type mapping) with two fields, “name” and “description”, store = true, and “index only specified fields” just so it will build fast.
Here’s the curl command, in case you have a UI allergy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
curl -XPUT -H "Content-Type: application/json" http://localhost:8094/api/index/hotel -d '{ "type": "fulltext-index", "name": "hotel", "sourceType": "couchbase", "sourceName": "travel-sample", "planParams": { "maxPartitionsPerPIndex": 32, "numReplicas": 0, "hierarchyRules": null, "nodePlanParams": null, "pindexWeights": null, "planFrozen": false }, "params": { "mapping": { "byte_array_converter": "json", "default_analyzer": "standard", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "default_mapping": { "display_order": "1", "dynamic": true, "enabled": false }, "default_type": "_default", "index_dynamic": true, "store_dynamic": false, "type_field": "type", "types": { "hotel": { "display_order": "0", "dynamic": false, "enabled": true, "properties": { "description": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "", "display_order": "0", "include_in_all": true, "include_term_vectors": true, "index": true, "name": "description", "store": true, "type": "text" } ] }, "name": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "", "display_order": "1", "include_in_all": true, "include_term_vectors": true, "index": true, "name": "name", "store": true, "type": "text" } ] } } } } }, "store": { "kvStoreName": "forestdb" } }, "sourceParams": { "clusterManagerBackoffFactor": 0, "clusterManagerSleepInitMS": 0, "clusterManagerSleepMaxMS": 2000, "dataManagerBackoffFactor": 0, "dataManagerSleepInitMS": 0, "dataManagerSleepMaxMS": 2000, "feedBufferAckThreshold": 0, "feedBufferSizeBytes": 0 } }' |
When you’re done, you can search for a common word like “Inn” to make sure things are working.
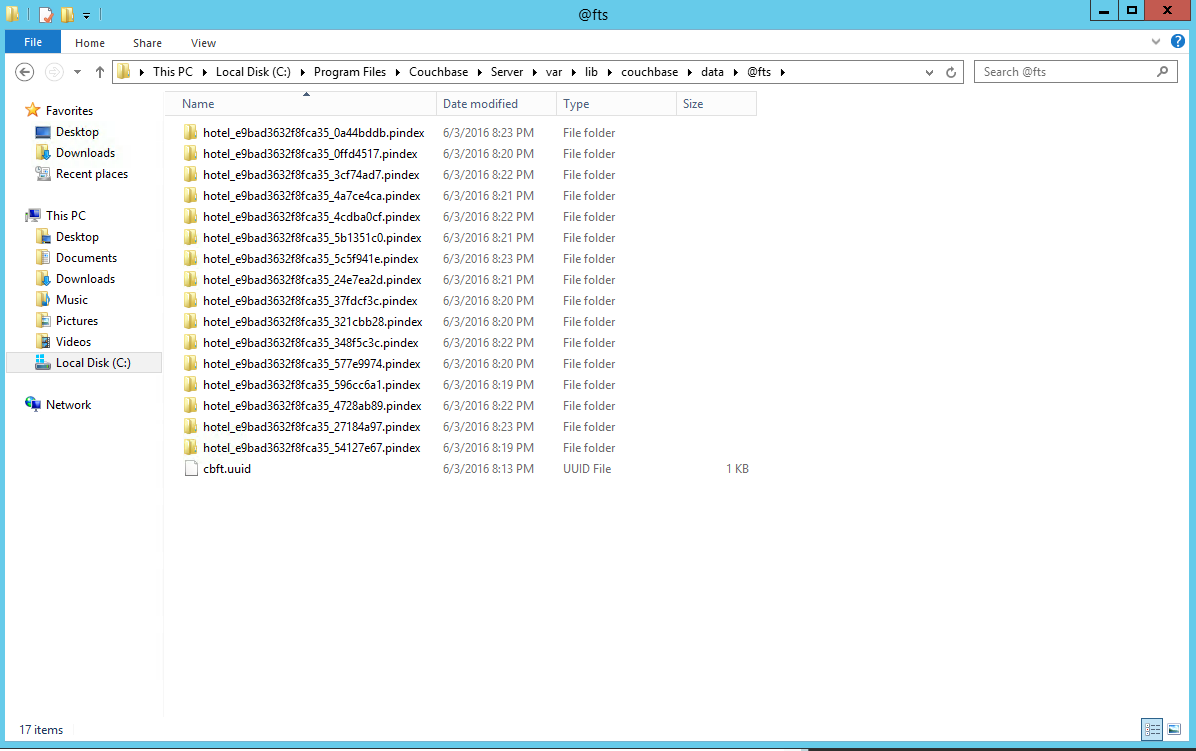
When you take a look at your Couchbase data directory, you’ll see an @fts directory. Open it and you will see a bunch of directories containing the pindexes.
Second Search Node and Rebalance
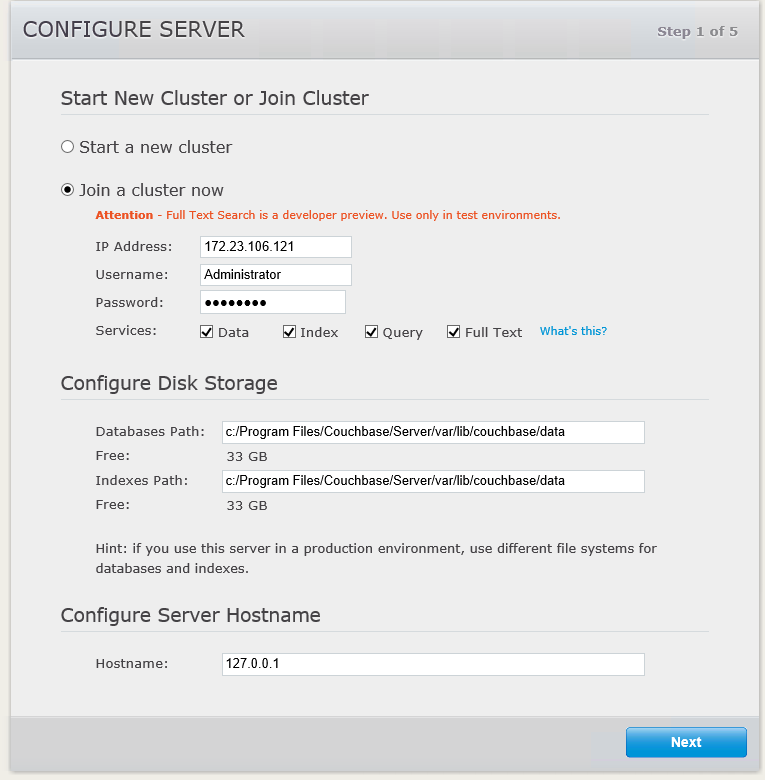
Go ahead and add a second node to the cluster, like you normally would. Don’t forget to tick the box to enable the search service.
You will see a screen that looks like this when you get done, showing a server pending rebalance.
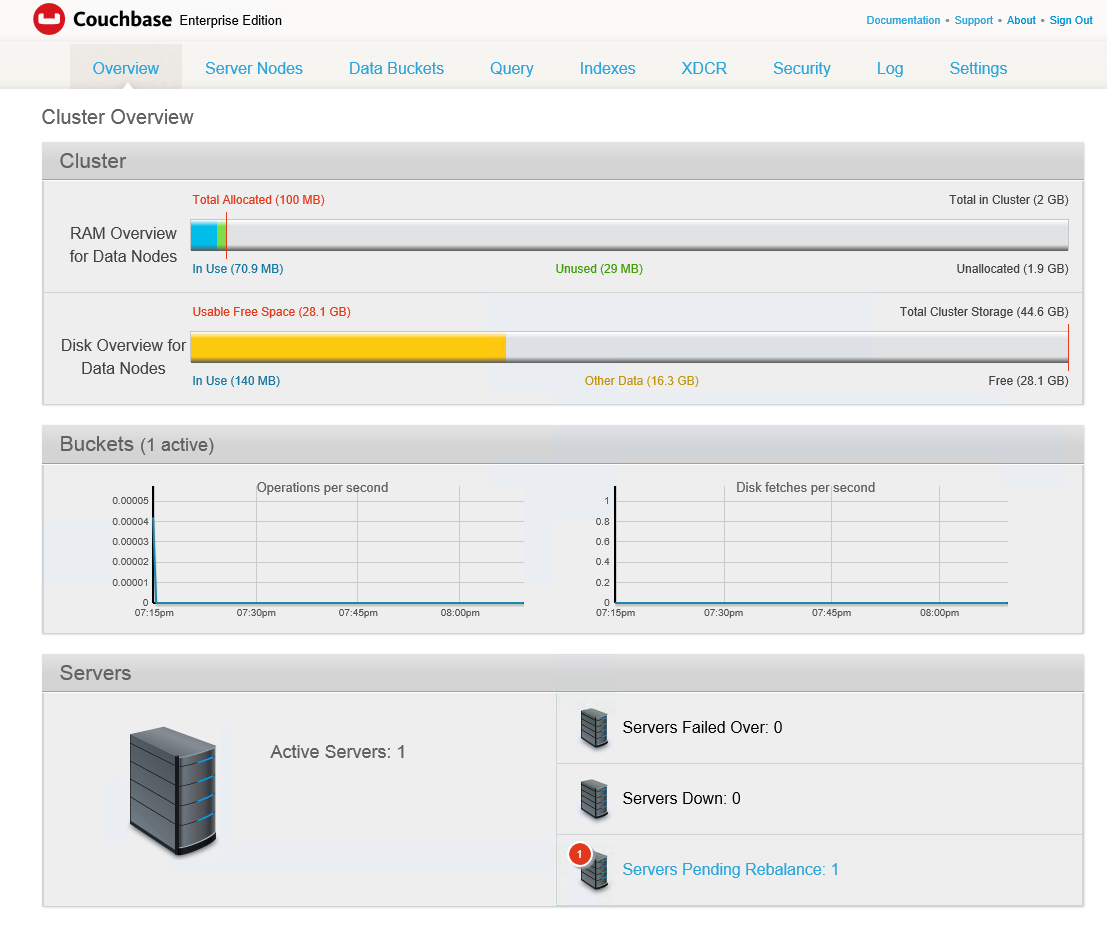
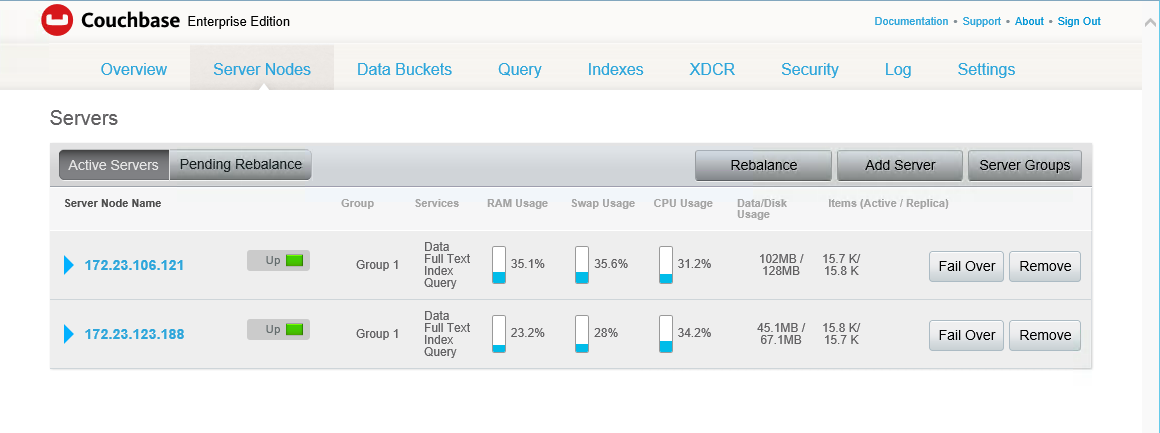
In this case, I see a fail over warning because the travel sample data has no replicas. Go in and hit the rebalance button. Documents begin to copy to the new node, replicas are created, and the travel sample’s views show as “building” because they are a form of local index, so the data rebalance means views also have to be rebuilt as the active data moves. (If you want to save yourself some time for the purposes of this demo, you can delete the views). Your pindexes are also rebalanced over the available nodes.
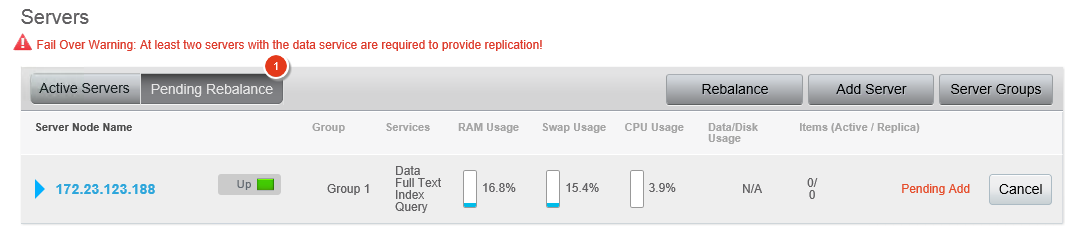
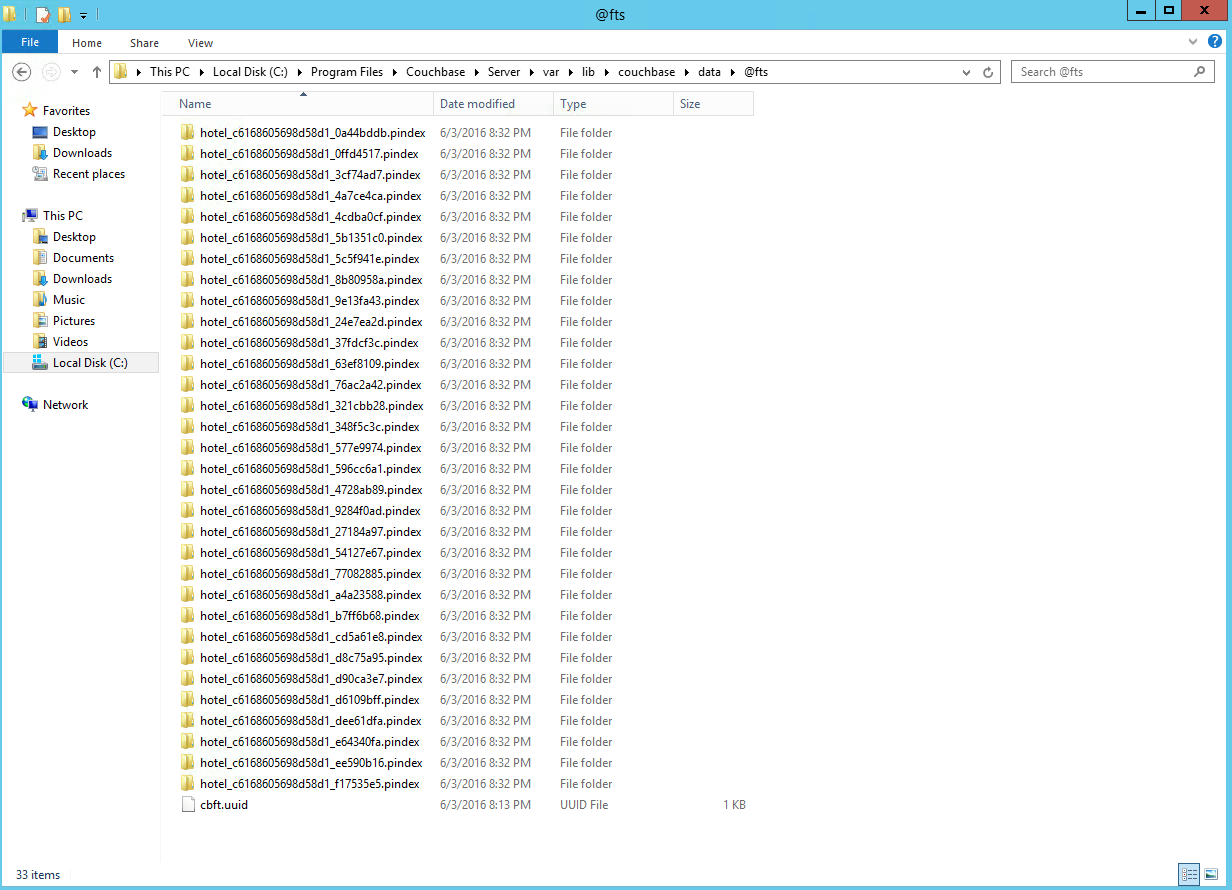
Once the process finishes, you will now have one half of the pindexes on each server.
To verify this, check your Couchbase data directory again. You will see half as many directories:
Index Replicas
Full text indexes can be replicated, just like you can have active and replica documents in Couchbase. Like document replicas, text index replicas get automatically laid out in the cluster in a balanced distribution depending on what hardware is available. Replicating full text indexes is mainly to speed up failover. Unlike documents, full text indexes are not at risk of data loss because they can always be recreated by reindexing using the index definition.
When you create or update a full text index, you have the option to specify one or two replicas. To do this, navigate to your index definition, click Edit, and then check Show advanced settings.
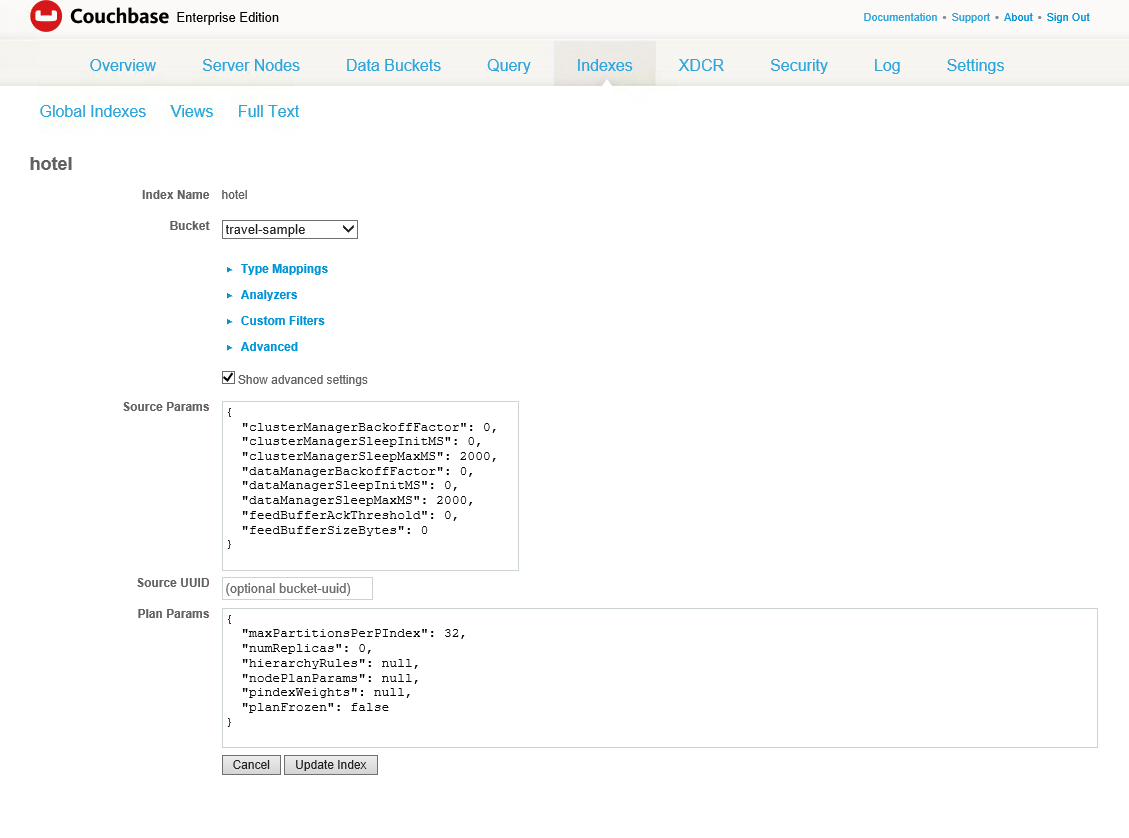
In Plan Params, change numReplicas to 1 and then Update Index.
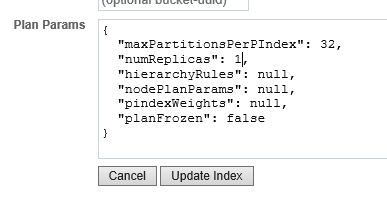
As soon as you save your definition, Couchbase Server will begin creating the active and replica text indexes. This will give you another copy of the index. Again, you can verify this by looking at one of the data@fts directories an counting the pindexes. Each node should now have 1/2 of the active pindexes and 1/2 of the replica pindexes.
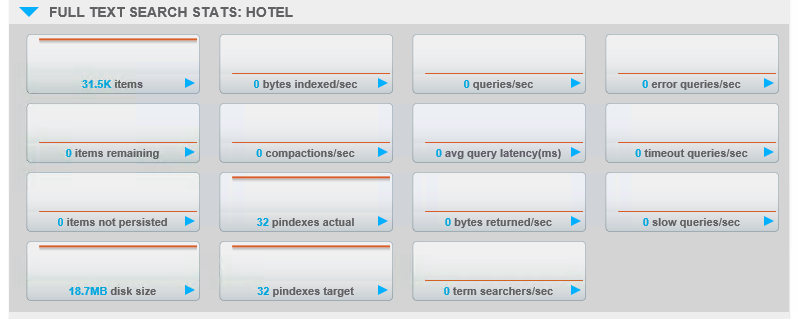
You can also see this by clicking on the Server Nodes tab, clicking on one of the servers and then expanding “Full Text Search Stats” for the index you created. You will see stats for pindexes actual (how many exist) and pindexes target (how many should exist, given the number of replicas you’ve requested).

Failing Over
Now failover one node. If you search now, you will get partial results – that is, you will get search results from the remaining pindexes. This is by design since some applications may elect to continue with partial results rather than throw an error. After all, with a large enough data set, users may not even notice missing documents.
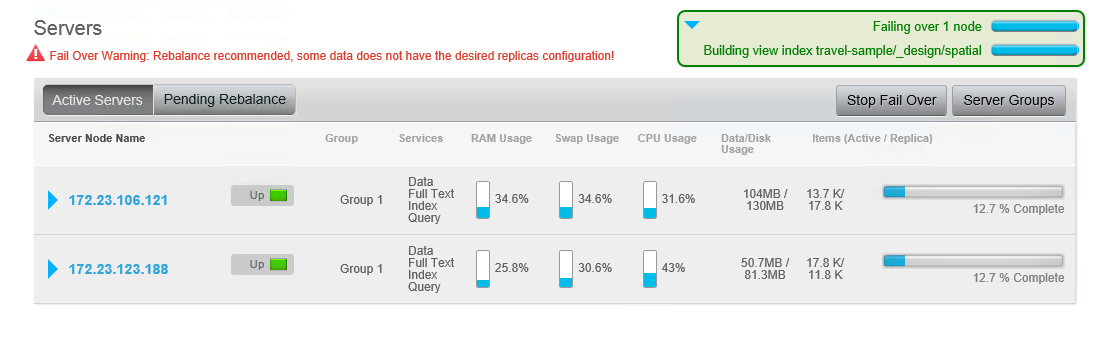
Now, rebalance the node. Rebalance with replicas is quite fast. (If you didn’t delete the travel sample views earlier, the failover takes significantly longer).
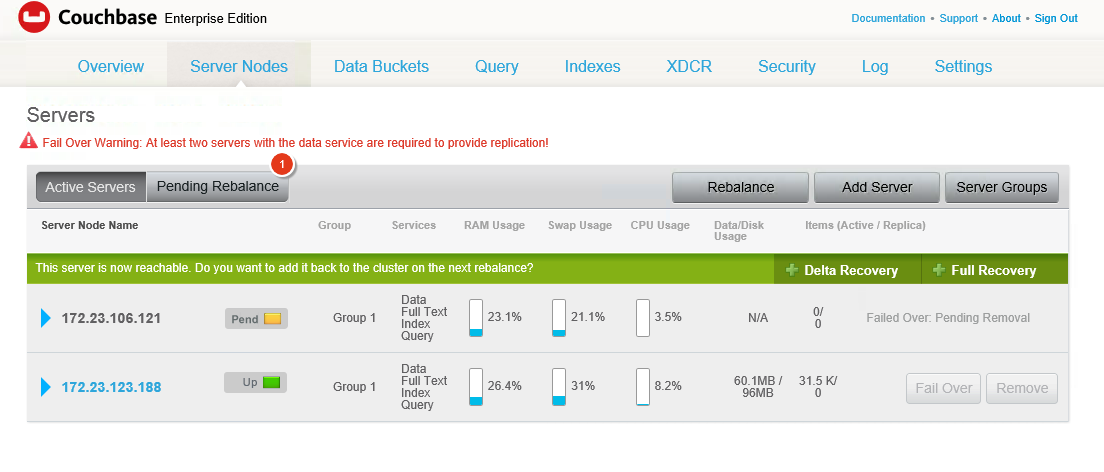
When you hit rebalance, the other node takes over very quickly by activating replicas – both document replicas and pindex replicas. This promotion is instantaneous. If indexing is ongoing, either because the index isn’t fully caught up or document mutations are going on, the full text indexes may take more time to build. As vBuckets move, nodes running the FTS service will reconnect their DCP streams to wherever the vBuckets ended up in the rebalance.
You should see something like this when the rebalance completes. Now we have no replicas and we’re back to the number of pindexes that we had at the beginning:
Failing Over without Replicas
You might be wondering what would happen if you were to do the above experiment without having created any full text index replicas first. That works too, and it’s worth doing at least once to see what happens. You won’t have primaries for some of your pindexes – exactly half in this case. That’s OK – as I mentioned above, you don’t have data loss, because the missing pindexes can be recreated by reindexing the documents using the original index definitions. You will get partial results, and you will get them for a longer period of time, too. This is because when you do a rebalance, the missing pindexes have to start from scratch and will not be as caught up as they would be if there were pindex replicas available.
Try it out
Distributed full text indexes are one of my favorite features of this release. They definitely take longer to explain than they take to use! We invite you to try them out and let us know what you think. Happy searching!