
Note: this blog post is a revist of Matthew Revell’s Moving from MongoDB to Couchbase Server
This is a developer-focused guide to moving your application’s data store from MongoDB to Couchbase Server. If you’re interested in migrating from a relational database to Couchbase, start with Laurent’s guide to making the move from PostgreSQL, and I will be working on a SQL Server migration post in the future.
While this guide doesn’t cover every corner-case, it does offer pointers to what you should consider when planning your migration. If you’re interested in learning about why you would do this migration, or learning about a Couchbase customer that has done this migration, check out Viber.
If you currently use MongoDB, and you’re using Mongoose ODM with Node, here is a video from the Connect 2016 conference on Migrating from MongoDB with Ottoman.js.
Versions
This guide is written for Couchbase Server 4.5 and MongoDB 3.4.
Key differences
Couchbase Server and MongoDB are both document stores that can operate on one or many servers. However, they approach things in some significantly different ways.
When you begin your migration from MongoDB to Couchbase Server, you’ll need to consider the following differences:
|
Couchbase Server |
MongoDB |
|
|
Data models |
Document, key-value |
Document |
|
Query |
N1QL (SQL for JSON), map/reduce views, key-value |
Ad-hoc query, map/reduce aggregation |
|
Concurrency |
Optimistic and pessimistic locking |
Optimistic and pessimistic locking (with WiredTiger) |
|
Scaling model |
Distributed master-master |
Master-slave with replica sets |
Data model
Couchbase Server is both a document store and a key-value store.
Everything starts with key-value, as every document has a key that you can use to get and set the document’s contents. However, you can use Couchbase Server as a document database by indexing and querying document contents. Note: if you’re interested in using Couchbase as a plain key-value store, read my blog post on Using Couchbase to Store Non-JSON Data.
Differences between BSON and JSON
It’s likely that your application stores JSON-style documents in MongoDB, so we’ll start there.
MongoDB stores data in the BSON format, which is a binary JSON-like format. The key difference when migrating is that BSON records additional type information.
When you export data from MongoDB using a tool such as mongoexport, the tool will produce JSON that preserves that type information in a format called Extended JSON.
Let’s take a look at an example in Extended JSON:
|
1 2 3 4 5 |
{ "myInt": { "$numberLong": "123" } } |
As you can see, the Extended JSON is still valid JSON. That means you can store, index, query and retrieve it using Couchbase Server. However, you’ll need to maintain that additional type information (in the above example, Extended JSON is storing a long integer as a string, for instance) in the application layer.
Alternatively, you could convert the Extended JSON to standard JSON before (or after) you import it into Couchbase Server. With N1QL queries, this should be relatively straightforward, though potentially tedious. Here’s an example that converts the “myInt” field above to a standard JSON number field:
|
1 2 3 |
UPDATE `default` SET myInt = TONUMBER(myInt.`$numberLong`) WHERE myInt.`$numberLong` IS NOT MISSING |
Which would result in:
|
1 2 3 |
{ "myInt": 123 } |
Non-JSON data
Both MongoDB and Couchbase Server can store opaque binary data.
Although the internal representation of the binary data differs greatly between the two, you can continue to store in Couchbase Server the binary data that you’ve been storing in MongoDB.
The main difference is that Couchbase Server can store binaries of up to 20MB in size, while MongoDB offers a convenience layer for chunking very large files into multiple documents.
There are strong arguments against storing large binaries in your database. When you have many very large binaries, you might consider using a dedicated object storage service to store them while using Couchbase to hold metadata on those binaries.
Architecture
Sharding
Couchbase Server shards data, and scales horizontally, by automatically distributing a hash space amongst nodes in a cluster.
It then uses the key of your document to decide where in the hash space — and so on which node in the cluster — that document resides. As a developer, this is abstracted away for you by the client SDK.
With MongoDB you need to choose a sharding method and a shard key. The shard key is an indexed field inside your document that determines where in the cluster the document resides.
The primary difference here is that Couchbase Server automatically handles all sharding for you, whereas MongoDB gives you the choice of sharding method and the shard key. If your applications relies on a particular distribution of data across the cluster then you’ll need to adjust it to allow for the hash-based distribution used by Couchbase.
Hash-based sharding greatly simplifies scaling compared to MongoDB. As a developer, you might think this doesn’t concern you, and is an ops issue. However, it does mean that it’s easier to rely on Couchbase Server should usage of your software grow.
Replication and consistency
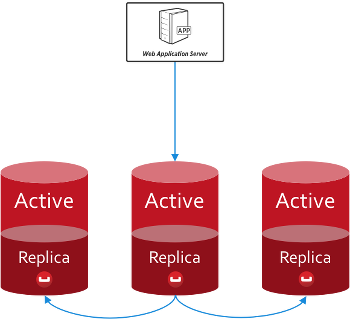
Couchbase Server maintains a single active copy of each document and then up to three replicas; you can configure the number of replicas on a bucketwide or per operation basis.
This means that, during normal operation, you deal with the same live copy each time you write into and read from a document. As a result, you don’t have to handle conflicting versions of documents. The replicas come into play only when the active copy is unavailable.
As a developer, the distribution and replication of documents is abstracted away for you. You write, read and query using your connection to the bucket and the SDK handles precisely where that data is stored. There’s no need to factor in replica sets or sharding schemes.
If you know the CAP theorem, then you also know that favoring consistency has an effect on availability. In the event of a node failure, its active documents will be unavailable for a short time to allow the cluster to promote the appropriate replicas to active status. In your code, all you need to do is retry a failed operation.
Indexing
Couchbase Server offers two broad types of index:
- GSI: global secondary indexes
- views: generated by map-reduce queries. The difference is more than an implementation detail, in that you create and manage both types of index differently. Mostly, you’ll use GSI indexes to replicate your MongoDB indexes.
|
MongoDB |
Couchbase Server |
|
Single field |
|
|
Compound index |
|
|
Multi-key index |
|
|
Geospatial index |
|
|
Text index |
Node types
When you grow beyond one MongoDB server you need to introduce router processes and config servers.
With Couchbase Server, both these functions are found in the client SDK. When you connect to the cluster from your application, the SDK receives a map of where in the cluster each shard lives. Couchbase Server then automatically updates the cluster map each time the shape of the cluster changes. Each request then happens directly from the application server to the relevant Couchbase node.
Once your cluster grows, you can choose to run specialised data, query and indexing nodes. Read more about multi-dimensional scaling.
This all happens transparently to you as the developer.
Buckets and collections
Both Couchbase Server and MongoDB allow you to divide your dataset into groups of documents: Couchbase has buckets and MongoDB has collections.
While MongoDB collections are of an equivalent scope to relational tables, Couchbase Server buckets are perhaps more the equivalent of a relational database.
That distinction matters because usually you’d want no more than ten buckets in a single Couchbase cluster. This makes them unsuitable as namespaces. Instead they serve as a way to share configuration and modeling decisions between similar types of documents.
This has two main consequences:
- You need another way to namespace your documents
- You need to think about when it’s appropriate to create a new bucket.
When to use multiple buckets
First, we need to think about how you can allocate resources to buckets. The two big considerations are:
- RAM
- Views and indexes.
When you create a bucket, you allocate to it a portion of each machine’s RAM. The RAM you give to a bucket should be big enough to store the working set of that data plus the few bytes of metadata associated with each document.
This means you can allocate different amounts of RAM appropriately to different datasets based on how you access them.
Similarly, Couchbase views and indexes run across the documents inside a bucket, much as a MongoDB map-reduce query runs across a single collection.
If you have some documents that don’t need indexing — because you only ever access them through their key — and you have some groups of documents that have different velocities, you can see that it would be prudent never to run indexers on the first set of data and to run the indexers with appropriate intervals across the rest.
Dividing our data into different buckets lets us accomplish both good use of RAM and of the CPU time needed by the indexers.
Let’s look at an example of an ecommerce application: the data you’d store, its profile and how you respond to that in your bucket configuration.
|
Data type |
Data profile |
Bucket profile |
|
Sessions |
Fast responses, key-value access, predictable concurrent sessions |
RAM to fit typical number of live sessions, no indexing |
|
User profiles |
Fast responses while users active, data changes slowly |
RAM to fit user profiles for typical number of live sessions, indexing on |
|
Order data |
Read-heavy after initial creation, short lifetime |
RAM to fit orders for typical number of live sessions, indexing on |
|
Product data |
Fast responses needed, read heavy |
RAM to fit entire catalogue, indexing on |
It’s a little more involved than deciding whether indexing is on or off. Rather, you choose the types of index, and the velocity of updates decides how often the indexers run. Mixing slow and fast moving data could be inefficient because a bucket’s indexers run across all documents in that bucket, including those that are unchanged.
Namespacing documents
If we can’t use buckets as namespaces, how do we easily distinguish different types of document?
You should use a combination of:
- Key naming
- Using a “type” in your JSON document.
Using semantic prefixes and suffixes in your key names is an easy way to namespace your documents, particularly when you’re using Couchbase for key-value.
Requiring a type in your document schemas gives you the data you need to create queries that apply only to certain types of document.
Programming model
There are three ways of working with Couchbase Server:
- Simple key-value access: strong consistency, sub-millisecond responses
- Views: generated by map-reduce queries
- N1QL: SQL-like querying (with JOINs)
Coming from MongoDB, you might be tempted to translate all of your MongoDB queries into N1QL. However, it’s worth thinking about the relative merits of each and then using the mix that suits your needs.
You can get a long way with key-value access, such as by using manual secondary indexes.
Query
Couchbase Server offers N1QL. N1QL is a SQL-like language and is quite different from querying in MongoDB.
Let’s look at an example where we return the name of employees from the Mountain View office who have worked there for two years or more, ordered by start date:
|
1 2 3 4 5 6 |
SELECT name FROM `hr` WHERE office='Mountain View' AND type='employee' AND DATE_DIFF_MILLIS(startDate, NOW_MILLIS) >= 63113904000 ORDER BY startDate; |
N1QL should be very familiar to you if you’ve ever worked with SQL. You’ll be able to translate your MongoDB queries to N1QL with relatively little effort.
Before you begin rewriting your queries, you should consider one major advantage that N1QL offers: you can perform JOINs across documents. Let’s take our query above and also return the name of each person’s manager.
|
1 2 3 4 5 6 7 |
SELECT r.name, s.name AS manager FROM `hr` r JOIN `hr` s ON KEYS r.manager WHERE r.office='Mountain View' AND r.type='employee' AND DATE_DIFF_MILLIS(r.startDate, NOW_MILLIS) >= 63113904000 ORDER BY r.startDate; |
Concurrency
In Couchbase Server, locking always happens at the document level and there are two types:
- Pessimistic: no other actor can write to that document until it is released or a timeout is hit
- Optimistic: use CAS (check-and-set) values to check if the document has changed since you last touched it and the act accordingly.
Optimistic locking can be more efficient, but pessimistic locking may be necessary sometimes. Read more about choosing the right type of lock.
Libraries and integrations
There are officially supported SDKs for all major languages, including Java, .NET, NodeJS, Python, Go, Ruby and C. You’ll also find community-developed client libraries for languages including Erlang.
Similarly there are official integrations with Spring Data, Spark, Hadoop, Kafka, Talend, Elasticsearch, and ODBC/JDBC, Linq2Couchbase for .NET, and there’s a NodeJS ODM called Ottoman. If you currently use Mongoose for MongoDB, watch this video on Migrating from MongoDB with Ottoman.js.
Conclusion
Moving from one document store to another is relatively straightforward, as the broad shape of your data doesn’t need to change all that much (as opposed to a relational migration).
As a developer porting an application from MongoDB to Couchbase Server, your main considerations are that you need to:
- Replace collection namespacing with key naming and document types
- Simplify your queries by using N1QL JOINs
- Consider where key-value access can be the best choice.
If you’re moving from MongoDB to Couchbase Server, you certainly aren’t the first. That’s great news for you because you’ll find people who’ve made the switch before in the Couchbase forums.
If you have any questions, comments, or if you find anything inaccurate, please leave a comment or reach out to me on Twitter.