Microservices have emerged as a common architecture pattern over the last decade.
In this approach, small, autonomous and loosely coupled services work together over a distributed network. Each microservice is typically delimited to a specific function and business boundary, runs in its own process, and can be managed and deployed independently of the other services.
This architecture results in greater flexibility compared to a traditional monolithic application, but at the same time requires that each individual microservice provides resilience, scalability and persistence where needed.
In this following article I would like to focus on the data management aspects of a microservice architecture and how Couchbase provides low latency, resilience and scalability for your data layer.
Simplicity with Integrated Caching & Elastic Scalability
Microservices are bound to an explicit business domain.
For example, your domain might be the Product, Campaign, Checkout or User-Profile services of an ecommerce application. The different microservices collaboratively form the application, but they are fully independent at the same same time. Often, different teams develop each service independently and with their own release cycle and CI/CD pipeline. The result is more agile and rapid development.
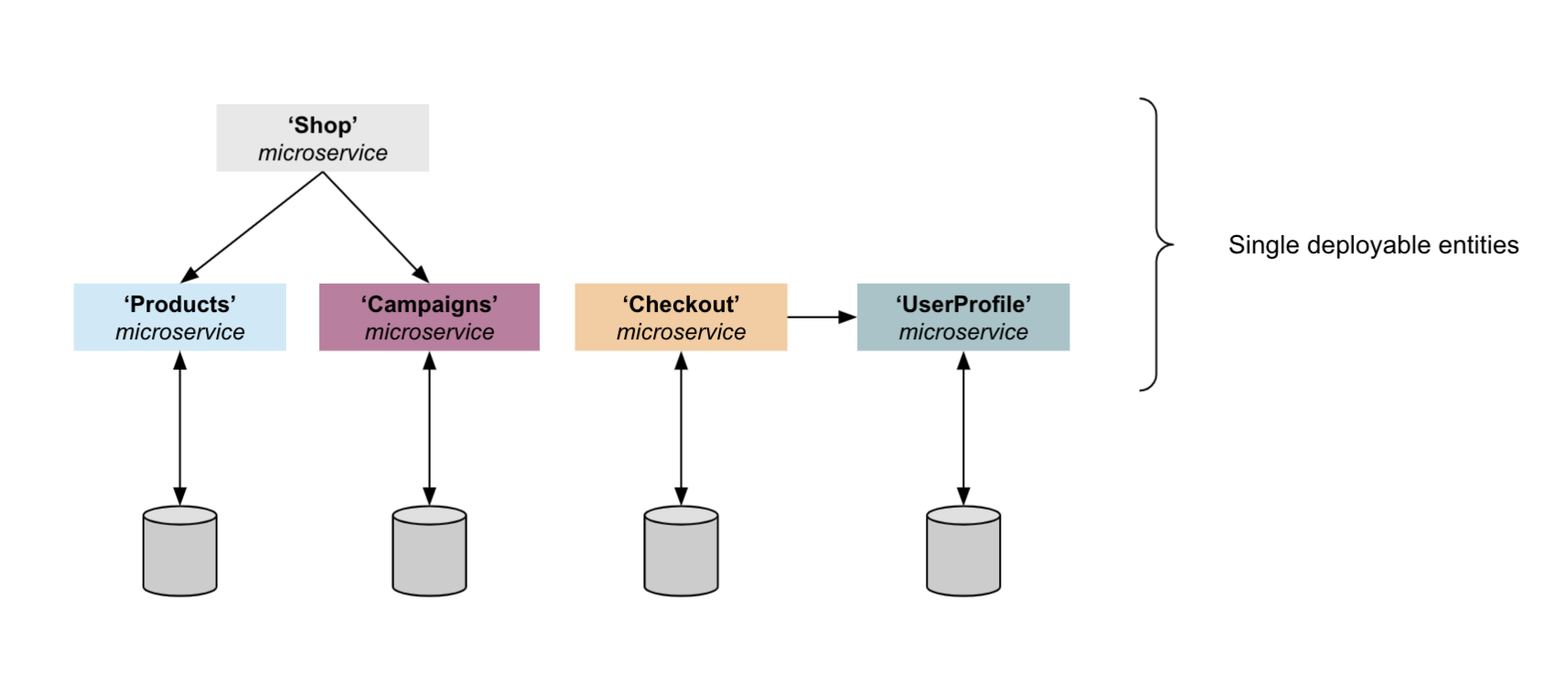
In this scenario pictured above, each microservice owns its domain data and makes this data available to the other services through APIs. During a checkout transaction, the Checkout service can resolve the corresponding customer data from the User-Profile service. This microservices architecture pattern provides great flexibility and also allows for reuse of microservices across multiple applications.
Building resilient and scalable services is crucial. For stateless microservices, this is fairly straightforward. But if data needs to be persisted, you ultimately need a resilient database architecture that scales together with the microservice to support increasing service usage.
Couchbase is built on a memory-first architecture that provides not only integrated caching for low latency access to your data, but also elastic scalability. This allows you to individually scale Couchbase services without interrupting your microservices operations.
As your data volume increases you simply add more Couchbase data nodes. If you need additional query capacity, just add additional Couchbase query nodes to your cluster.
With this level of multidimensional scaling, your different Couchbase services never need to compete over system resources. Instead, the underlying infrastructure is tailored around the service-specific needs. For instance, the Couchbase Query service uses a compute instance with lots of memory to serve as much data as possible from the integrated cache, and it uses a node with additional cores to support more queries.
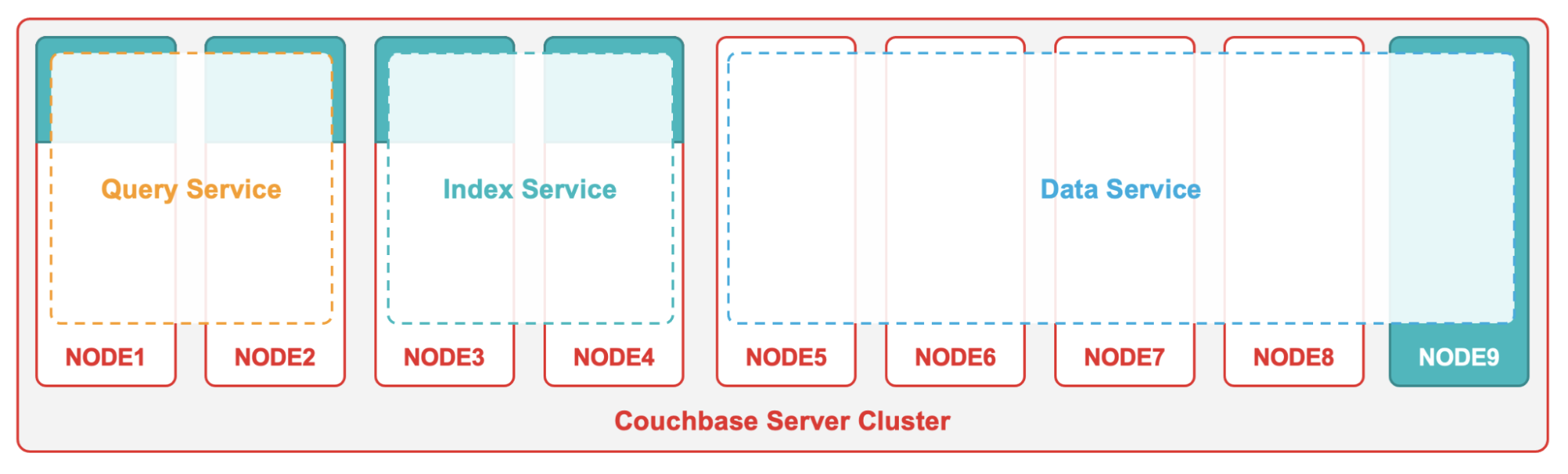
Scalability and resource isolation in Couchbase
The resilient and distributed Couchbase architecture also guarantees high availability by maintaining replica copies of your data. In case of a node failure, Couchbase automatically fails over and guarantees continued operations.
Common Patterns for Microservices in Couchbase
One of the key characteristics of microservices is their loose coupling, so that they can be developed, deployed, access-controlled and scaled on an individual basis.
Loose coupling requires that the underlying database infrastructure supports isolating the data for the individual microservices. That could be either by running individual database instances per microservice or by controlling access to the relevant parts of the data.
While traditional relational databases support isolation using database schemas, they are often difficult to scale, they lack the flexibility of a JSON data model, and most importantly, they become the single point of failure in case of an outage of your database infrastructure. This is an important aspect to consider when designing your microservice architecture, as an outage has severe consequences for all microservices sharing the same database.
Couchbase is designed for microservices. It’s a highly scalable, resilient and distributed database. It offers great flexibility and provides multiple levels of isolation to support up to one thousand microservices in the same Couchbase cluster.
Couchbase Server 7 introduces the concept of scopes and collections.
Scopes and collections are logical containers created within a bucket that organize and isolate your data. A bucket is a keyspace that allows you to configure individual memory quota, disk and I/O priority. These settings provide partial resource isolation. Buckets, Scopes and Collections provide independent deployment and lifecycle management at all levels including role-based access control, cross data center replication (XDCR), and backup/restore.

These features give your development teams greater flexibility and allow for multiple patterns of microservices. Let’s take a closer look at four of those most common patterns.
Pattern 1: Dedicated Couchbase Cluster per Microservice
Using a dedicated Couchbase cluster provides independent scaling through physical isolation. While this is a viable option, it may not be very practical when running hundreds or even thousands of microservices.
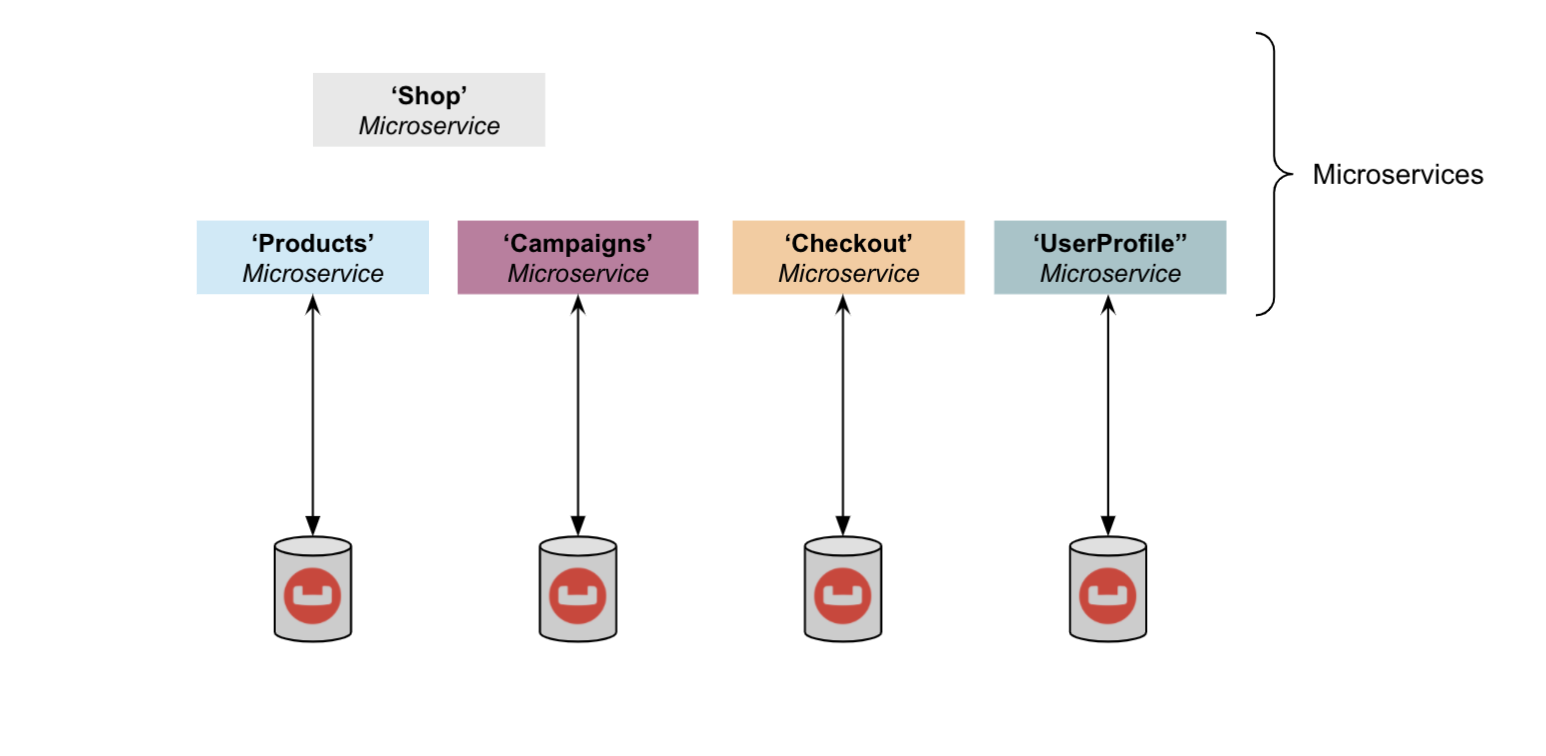
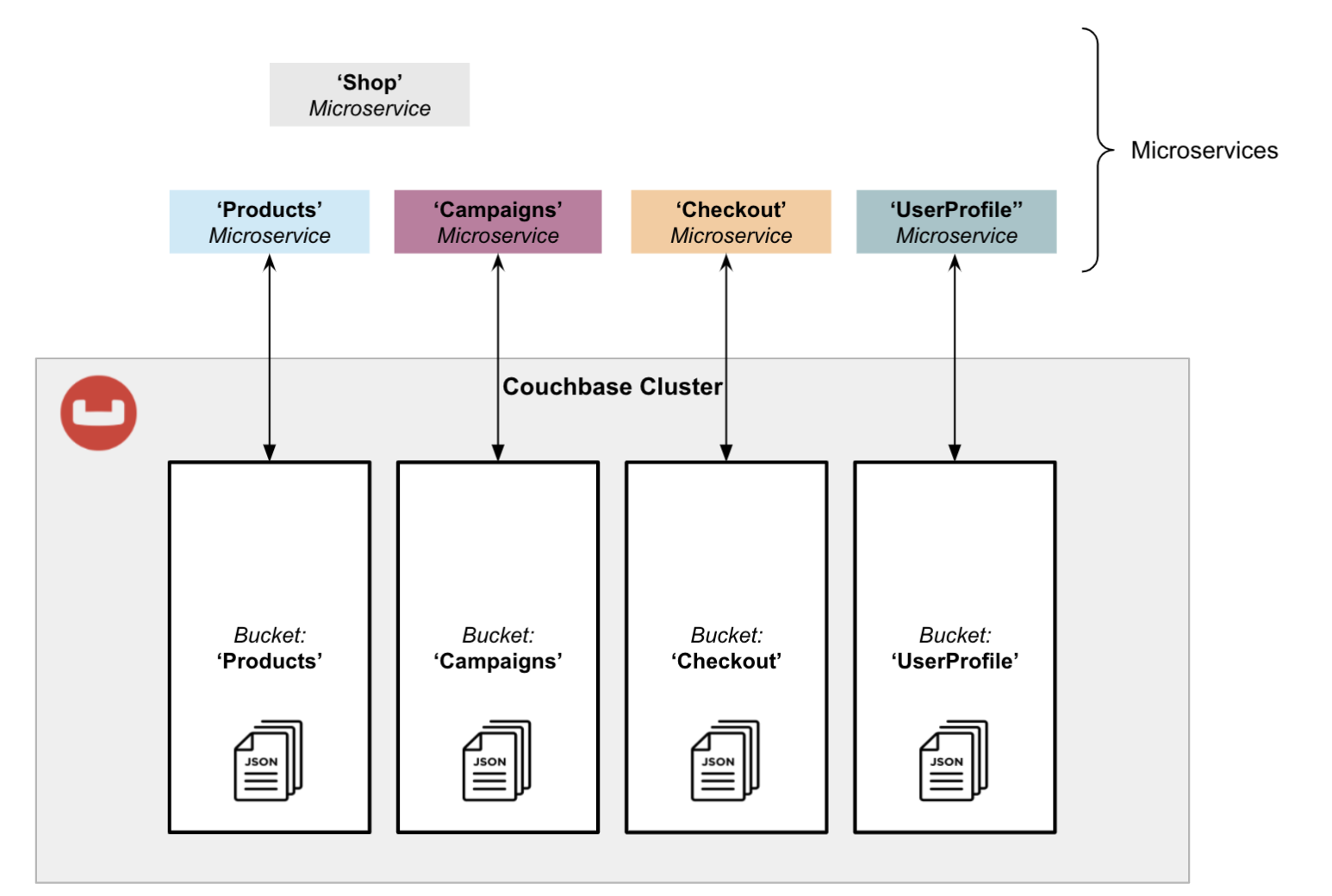
Pattern 2: Isolation Using Buckets
In this pattern, buckets are used to isolate microservices.
Compared to dedicated clusters, buckets provide partial resource isolation including memory allocation, disk I/O and replicas. However, the number of buckets per Couchbase cluster is limited, so the number of microservices supported in a single cluster cannot exceed thirty.
If you have no strict requirements to isolate the data between services, or if there are other measures to ensure that each microservice only works with its own dataset, then multiple microservices can share the same bucket. Typically, bucket sharing is accomplished by identifying the document by either the document key or an additional type attribute in the document.
In fact this pattern was commonly used prior to the introduction of scopes and collections in Couchbase 7.
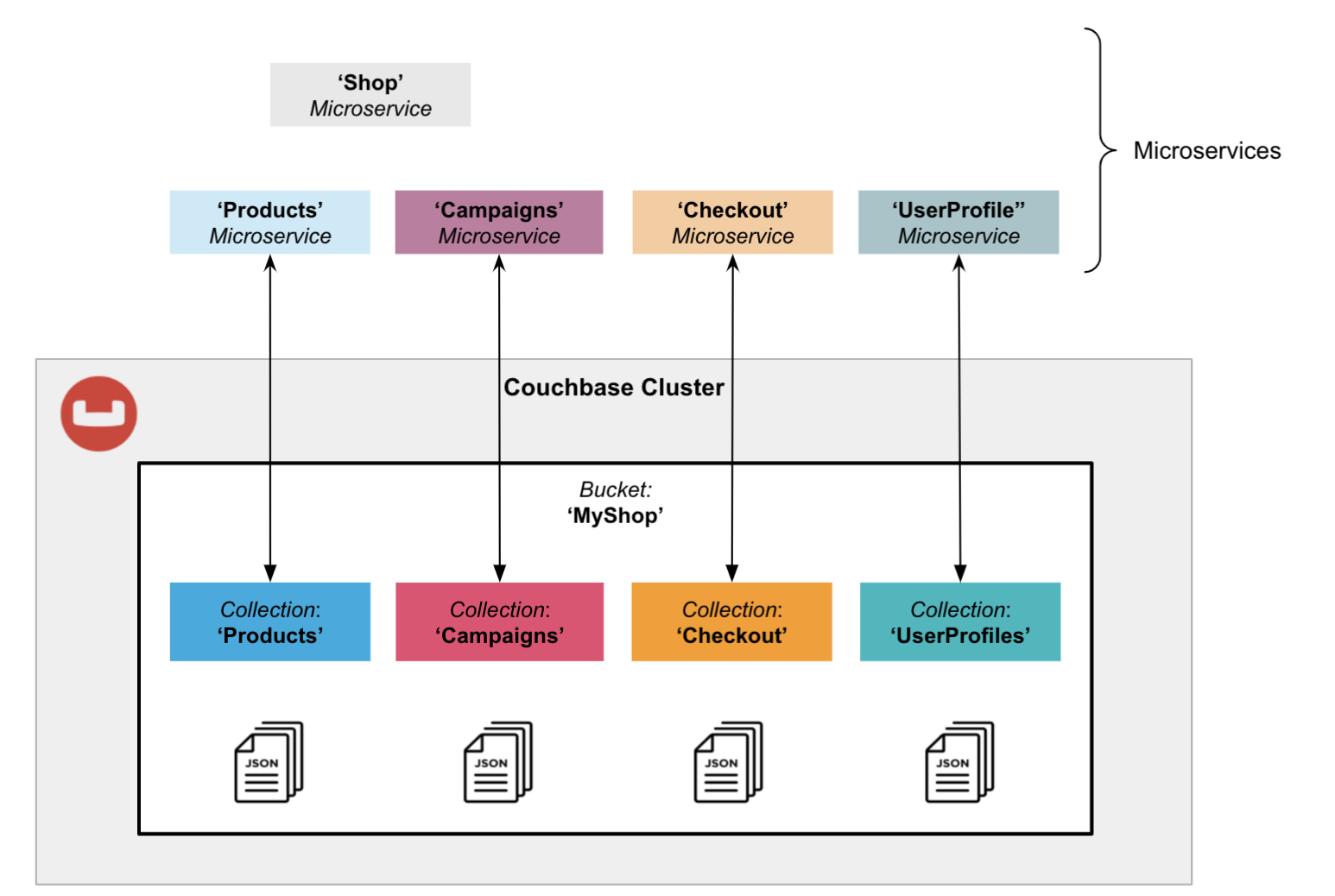
Pattern 3: Isolation Using Collections
A more powerful microservices deployment pattern is to take advantage of Collections.
While a surrounding bucket still provides resource isolation, Collections logically isolate and control access for your microservices. This enables you to run up to 1000 microservices in a single Couchbase cluster. In the illustration below, each microservice is using a dedicated Collection. Couchbase role-based access control ensures that each microservice only accesses its own dataset in the corresponding collection.
Pattern 4: Isolation Using Buckets and Collections
This microservices pattern is similar to the previous pattern, but instead of placing all collections into a single bucket, you group them into multiple buckets.
This pattern allows you to configure the bucket according to the characteristics of the included microservices and/or collections. With this approach, you achieve physical isolation such as the memory allocation and replica count for each individual bucket and its contained collections.
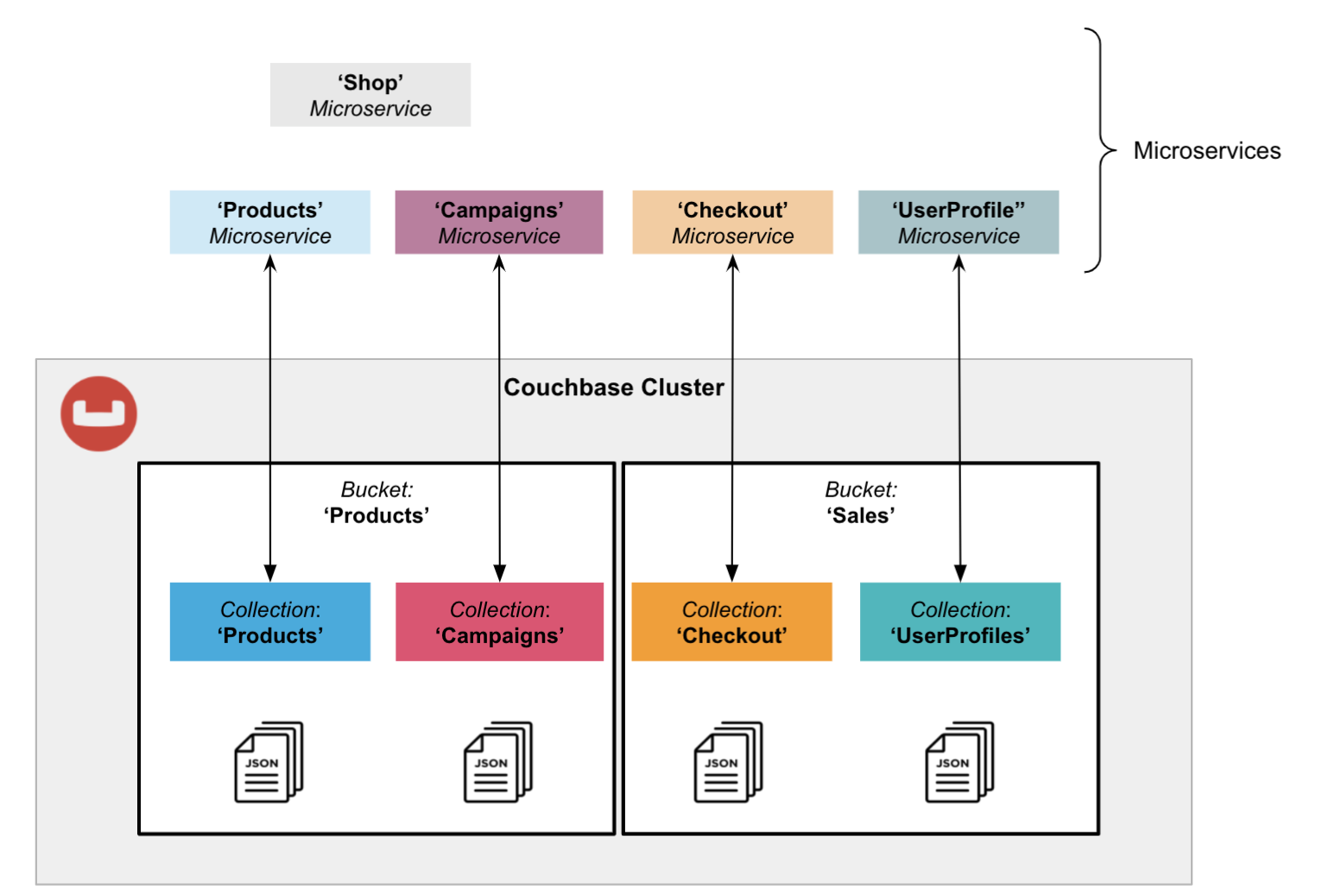
There is no single best solution to structure and isolate your data in Couchbase. But using buckets, scopes and collections, you have an infinity of options to easily meet the specific needs of your microservice architecture.
Containerized Deployments
There’s no doubt: Today’s development environments are shifting toward microservices. At the same time the industry is moving towards containerized deployments managed through Kubernetes and OpenShift.
With Couchbase, your autonomous, fully managed stateful database application runs next to your microservices on the same Kubernetes platform. This approach gives you complete isolation and reduces your DevOps workload with automatic failover and even automatic scaling of your cluster.
For more information, check out the Couchbase Autonomous Operator.
[…] https://www.couchbase.com/microservices-architecture-in-couchbase […]
[…] 4 Patterns for Microservices Architecture in Couchbase […]