
How can you analyze all data? That is to say, how can you analyze all data as of this moment?
Hadoop is the de facto standard for storing and analyzing a lot of data, a lot, but how is it stored? How is it analyzed? First, it’s imported, as a batch. Next, it’s processed, as a batch. The key word? Batch. While a batch of data is being imported or processed, data continues to be generated. If data is imported once a day, data in Hadoop is incomplete. It’s missing a day of data. If processing requires an hour, the results are incomplete. The input was missing an hour of data.
What if analysis must include data generated in the last minute?
Lambda Architecture, defined by Nathan Marz, creator of Storm — a stream processor.
What if data is processed a continuous stream of data? When data is generated, it’s processed, before it’s stored. Now, analysis can include data generated in last second, the last minute, or the last hour by processing the incoming data, not all data.
If you can combine processed data in Hadoop with processed data from a stream processor, you can analyze all data generated as of this moment.
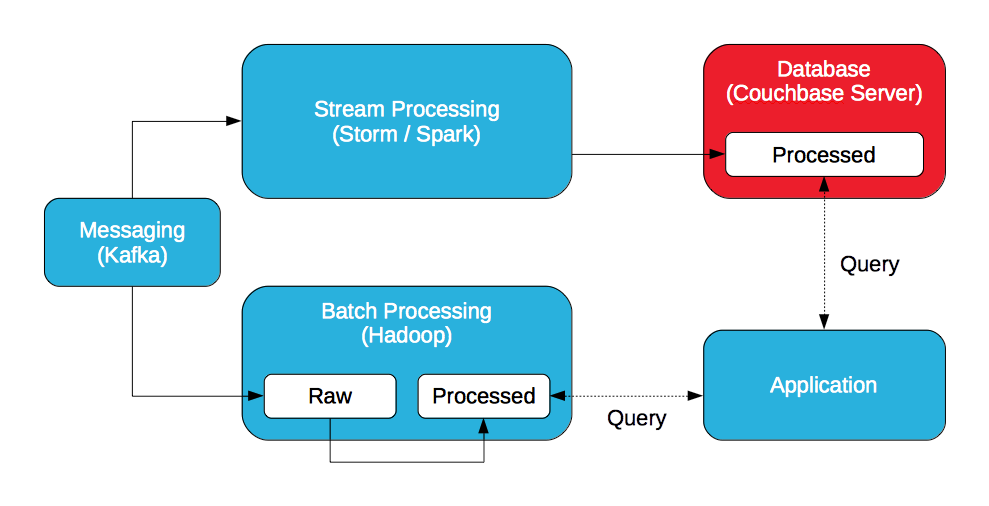
Messaging
A distributed messaging system (Kafka, JMS, or AMQP) is ideal for ingesting data at high throughput, low latency.
Stream Processing (Speed Layer)
A distributed stream processing system (Storm, Spark Streaming) is ideal for analyzing incoming data in real-time. While Storm processes individual data, Spark Streaming processes mini-batches of data.
Hadoop (Batch Layer)
Hadoop stores batches of raw data and processing them with MapReduce / Pig or Spark.
Database
A distributed database is ideal for storing processed data generated by the stream processor. A stream processor stores neither the raw data nor the processed data. It does not store data. The database must be able to meet the high throughput, low latency requirements of the stream processor so it does not become the bottleneck.
Application (Serving Layer)
An application queries the processed data in both Hadoop and the database to create a complete view of the results. The application may query Couchbase Server with SQL (via N1QL) and / or views, and Hadoop with Hive or Impala / Drill.
If the idea is to query processed data, batch and streaming, why not store all processed data in the database so it's the serving layer?
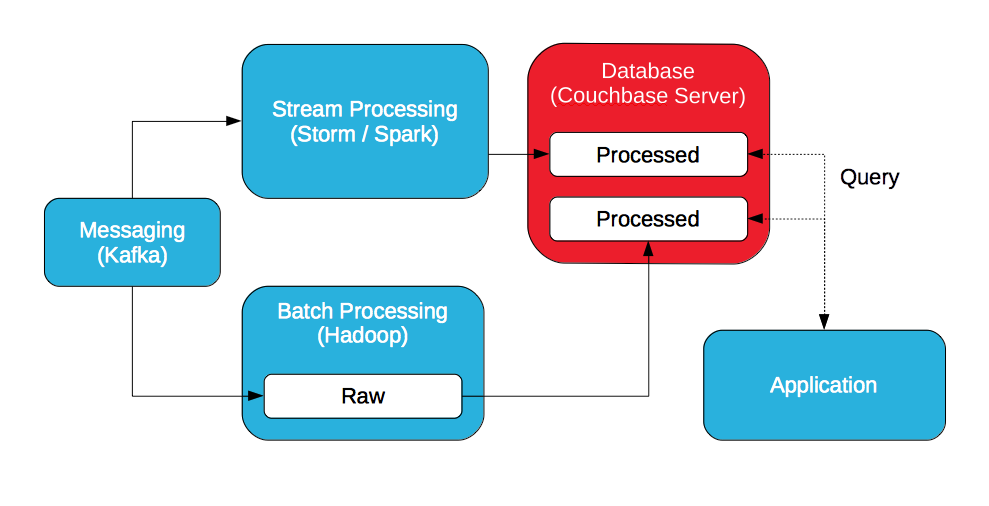
There are two options: store processed data in Hadoop and export it to the database or store the processed data in the database. The data can be exported from Hadoop to Couchbase Server with a plugin for Sqoop.
With Couchbase Server, processed data can be accessed with a key/value API or queried with SQL (via N1QL). In addition, processed data can be further processed and queried with views. Views are implemented with map/reduce to sort, filter, and aggregate data but leverage incremental updates.
Notes
Hadoop is required. While it's possible to deploy Spark without Hadoop, distributions from Cloudera, Hortonworks, and MapR include it. Hadoop stores a lot raw data, Spark processes it, and data locality is important. In addition, Hadoop is more than Spark. It includes MapReduce and Pig. It includes Hive. Cloudera Enterprise includes Impala, Hortonworks Data Platform includes Tez, and MapR includes Drill.
Despite what a NoSQL vendor may imply, I'm looking at you DataStax, both Hadoop and NoSQL are required. A NoSQL database can't replace Hadoop by integrating with Spark.
Shane – It\’s an interesting topic that you\’re looking at from a CouchBase (data ingestion) PoV. The other side of this is the App layer; the presentation & business use of the data being streamed. I\’ve worked with many Clients who have said they want zero-latency Dashboards & Analytics, but then get frustrated because the granularity of the information being displayed is too low. The example I\’ve used with Clients is the \’Stock market ticker\’. It tells you trade-by-trade what a company\’s stock is doing, but it tells you nothing about the overall performance of the market, or the long term performance of the company.
I\’m commenting, not critiquing the Blog article.
In my experience, as Information Architects, we should be very judicious, we have to communicate the business pro\’s & con\’s of streaming data into Apps. IMO, companies need a historical baseline as a component of a data infrastructure. Historical, possibly aggregated & streaming data in order for good predictive Analytics.
Thank you.
That\’s a relevant thought. However, granularity is configurable. For example, a stream processor could evaluate all trades to identify how well the market, not a stock, is performing in real time. Applications leveraging Couchbase Server views can further sort, filter, and aggregate data for near real-time access via dashboards. Perhaps to aggregate by industry or sector. Though like you said, it\’s worth combining historical data with streaming data for a complete picture.