
The whole web developer community is excited about Kubernetes (K8s). No wonder it is the hottest topic at the conferences and developer events that I have been to the last year.
It is not just a tool for managing containers, in fact, K8s allows you to easily add load balancing and avoids the need of a service discovery layer (you no longer need eureka for instance). K8s also automate application deployments and updates, and most importantly, let you plug/write custom controller for your infrastructure.
Fantastic, right? But managing stateless containers isn’t that complicated, after all, they are essentially ephemeral and you can kill and spin up instances as you wish without any considerable side effects.
But this is half of the story, in general, applications can’t be entirely stateless, and in most cases, we simply push the state to the layers down below. So, how do we deal with stateful applications in K8s? Luckily, since version 1.5 there is something called StatefulSets.
Stateful Containers
Kubernetes StatefulSets gives you a set of resources to deal with stateful containers, such as: volumes, stable network ids, ordinal indexes from 0 to N, etc. Volumes are one of the key features which allow us to run stateful applications on top of Kubernetes, let’s see the two main types currently supported:
Ephemeral storages volumes
The behavior of ephemeral storages is different than what you are used to in Docker, in Kubernetes the volume outlives any containers that run within the Pod and the data is preserved across container restarts. But if the Pod gets killed, the volume is automatically removed.
Persistent storage volumes
In a persistent storage, as the name suggests, the data lifetime is independent of the Pod’s lifetime. So, even when the Pod dies or is moved to another node, that data still persists until it is explicitly deleted by the user. In those kinds of volumes, the data is stored typically remotely.
We are looking forward to Kubernetes support to Local Persistent Storages as it will definitely be the best fit for running databases, but in the meantime, we use ephemeral storages by default. At this point, you might wonder why we are using ephemeral storages instead of the persistent ones. Not surprisingly, there are many reasons for that:
- Ephemeral storages are faster and cheaper than persistent, it would require more infrastructure/networking to use persistent storages as you need to send the data back and forth
- K8s 1.9 introduced Raw Block Support, which allows you to access physical disks in your VM instance to use it in your application.
- Maintain networked storage systems is not trivial
- You can always try to reboot the container first instead of killing the whole Pod:
1kubectl exec POD_NAME -c CONTAINER_NAME reboot - You can configure Couchbase to automatically replicate your data, so even if N Pods dies, no data will be lost.
- Part of K8s job is to run Pods in different racks to avoid massive failures.
However, there are a few scenarios where using Remote Persistent Storages would be worth the extra latency cost, like in massive databases for instance, when the rebalancing process takes several minutes to finish. That is why we also will add support for Remote Persistent Storages.
One of the downsides of Statefulsets is the limited management, that is why we decided to extend the Kubernetes API through the use of a Custom Resource Definition (CRD), which allows us to create a custom native resource in Kubernetes similar to a StatefulSet or a Deployment, but designed specifically for managing Couchbase instances.
Great! So, with StatefulSets/CRDs we have all the hardware operations arranged, there is just a “small” thing missing here, what about the state of the application itself? In a database, for instance, adding a new node to the cluster is not nearly enough, you would still be required to trigger some processes, such as rebalancing to move/replicate some of the data to the newly added node to make it fully operational. That is exactly why K8s Operators joined the game.
Kubernetes Operators
Kubernetes 1.7 has added an important feature called Custom Controllers. In summary, it enables developers to extend and add new functionalities, replace existing ones (like replacing kube-proxy for instance), and of course, automate administration tasks as if they were a native Kubernetes component.
An Operator is nothing more than a set of application-specific custom controllers. So, why is it a game changer? Well, controllers have direct access to Kubernetes API, which means they can monitor the cluster, change pods/services, scale up/down and call endpoints of the running applications, all according to custom rules written inside those controllers.
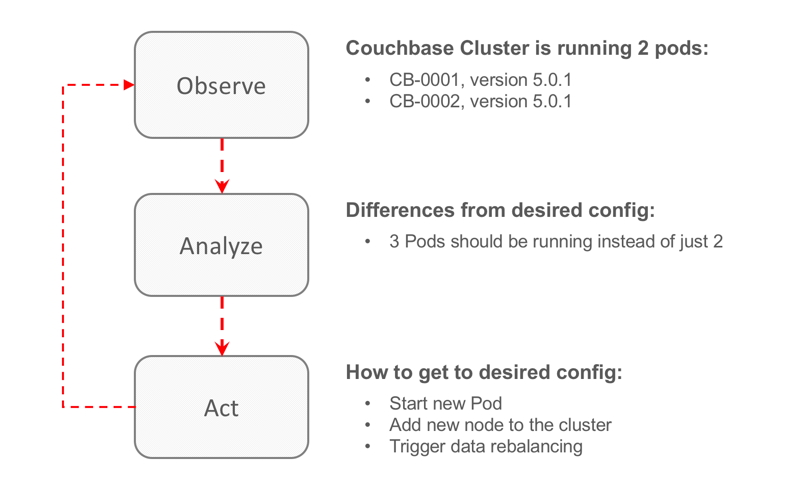
To illustrate this behavior, let’s see how Couchbase’s Operator works when a Pod gets killed:
You can find out more about operators here
As you can see in the figure above, the Operator monitors and analyzes the cluster, and based on a set of parameters, triggers a series of actions to achieve the desired state. This reconciliation process is all over the place in K8s. But not all actions are equal, in our example, we have two distinct categories:
- Infrastructure – add a new node: The operator requests via Kubernetes API to launch a new Pod running Couchbase Server.
- Domain Specific – Add node to the cluster/ Trigger data rebalancing: The operator knows how Couchbase works and calls the correct rest endpoint to add the new node to the cluster and trigger data rebalancing.
That is the real power of Operators, they allow you to write an application to fully manage another, and guess which kind stateful applications are the hardest to manage? You are right: Databases.
Developers have always expected databases to work out-of-the-box, when in fact, they historically are exactly the opposite. We even have a specific name for the person responsible for taking care of the database, our beloved DBAs.
Couchbase’s Operator was created as an effort to change this scenario and make databases easy to manage without locking you to a specific cloud vendor. Currently, it supports automated cluster provisioning, elastic scalability, auto-recovery, logging and access to the web console, but many more features are coming in the future. If you want to read more about it, please check out this article or refer to Couchbase’s official documentation here.
I also have to mention that It is the very first official operator launched for a database, and there are some small community projects already trying to build operators for MySQL, Postrgres and other databases.
The Operator’s ecosystem is growing quickly, rook for instance, lets you deploy something very similar to AWS S3. The Apache Kafka Kubernetes operator is coming soon and there are many other initiatives out there. We expect a major boost in the number of operators in the upcoming months now that all major cloud providers support K8s.
Finally, Kubernetes provides a cloud-agnostic application deployment and management. It is so powerful that it might lead us to treat cloud providers almost like a commodity, as you will be able to migrate freely between them.
In the future, choosing a cloud provider could be just a matter of which one offers the best performance/cost. The market impact of this radical shift is still unclear, but as developers, we are certainly the biggest winners.
UPDATE: Even though this article was written not so long ago, a lot of things have already changed. We have now the Couchbase Autonomous Operator 1.2, Local Persistent Storage is GA, and there is an Operator Hub to centralize all open-source operators.
If you have any questions, feel free to tweet me at @deniswsrosa
Very informative and succinct blog!