
My family hears me talk about JSON databases rather frequently.
Naturally, I had to explain that Jason is not the owner of my company! Instead, many modern databases use JSON as a data format. They usually leave the room at this point, tired of indulging my enthusiasm for the Couchbase JSON database.
What Is a JSON Database?
A JSON database is arguably the most popular category in the NoSQL family of databases. NoSQL database management differs from traditional relational databases that struggle to store data outside of columns and rows. Instead, they flexibly adapt to a wide variety of data types, changing application requirements and data models. In an era where physical storage limits are no longer a bottleneck, JSON databases deliver superior scale and performance.
This flexibility made JSON databases the preeminent storage structure for NoSQL systems that support multi-model or multi-modal processing. Their popularity is due mainly to the simplicity and flexibility of the JSON database document structure.
First introduced in 2006, JSON stands for “JavaScript Object Notation” and offers a less verbose data format than the popular XML (eXtensible Markup Language). Today the JSON data format is powering enterprise systems around the globe despite its humble roots in enabling JavaScript programming and simple web-based applications. JSON databases like Couchbase or MongoDB take advantage of the standard’s simple syntax, providing data structures readable by both humans and machines.
Let’s look at some of the advantages of a database that stores data in JSON format. While we do, consider how you might be able to leverage its functionality in future applications.
JSON Databases Have More Storage Flexibility
NoSQL is a database category adapted to specific use cases that focus on storage structure, scaling design and query/indexing methods. There is also a focus on concurrency, high availability and real-time data persistence guarantees.
For example, some databases optimize key-value data storage for retrieval speed – aiming to run as fast as possible. They often run primarily in memory, avoiding the time-consuming burden of reading data from spinning hard drives.
Of course, memory is volatile and power failures can erase data stored in memory. Key-value database engines offer a means for writing data to persistent storage to reduce data loss. However, key-value stores may be too simplistic for some use cases.
In addition, other data structures, such as graph databases, may be too abstract for other use cases. Graph database structures can be fast, as they usually support in-memory processing to expedite relationship traversal speeds. However, to do this requires a natively built data architecture with fancy design names like “index-free adjacency.” These structures associate each piece of data with a set of relationship ID numbers stored physically on a disk.
Graph data models were most helpful when memory and disk space were scarce. But it created challenges when scaling a graph structure across multiple database nodes. For example, where do you logically break your relationships in the underlying data?
NoSQL JSON databases handle documents as individual data file objects without using structured tables. A row count or table size does not constrain the number of documents stored in a JSON database. Instead, storage availability is the only limit to data volume. Thankfully, a cluster can easily expand storage.
Partitioning Data
This cluster-based approach allows the database to add more nodes to create a larger data platform as needed. Developers also call this process “scaling out” the cluster. Partitioning data across nodes allows distributed storage and processing where no single node is doing all the work.
The underlying database partitions the data to maintain this balance using a pool of storage services in a shared-nothing architecture. The system balances and replicates data to keep it available if a node becomes unusable.
Processing Data Models
A cluster can also have a mix of node types – data storage, processing, and serving data – using different access models. A JSON database makes it possible to store data as JSON and provide it to applications in other forms.
For example, JSON databases can operate as an in-memory key-value store for applications that just need quick and easy access. Or, indexing and querying can make JSON data appear as a table. Also, developers can use data structure SDKs to serve up atomic attributes as key-value pairs.
JSON Databases Offer Flexible Schemas
JSON document databases store their data in files using a specific notation designed to eliminate the rigidity of relational database schemas. They can more rapidly meet new data structure requirements derived after the initial database schema design and application release.
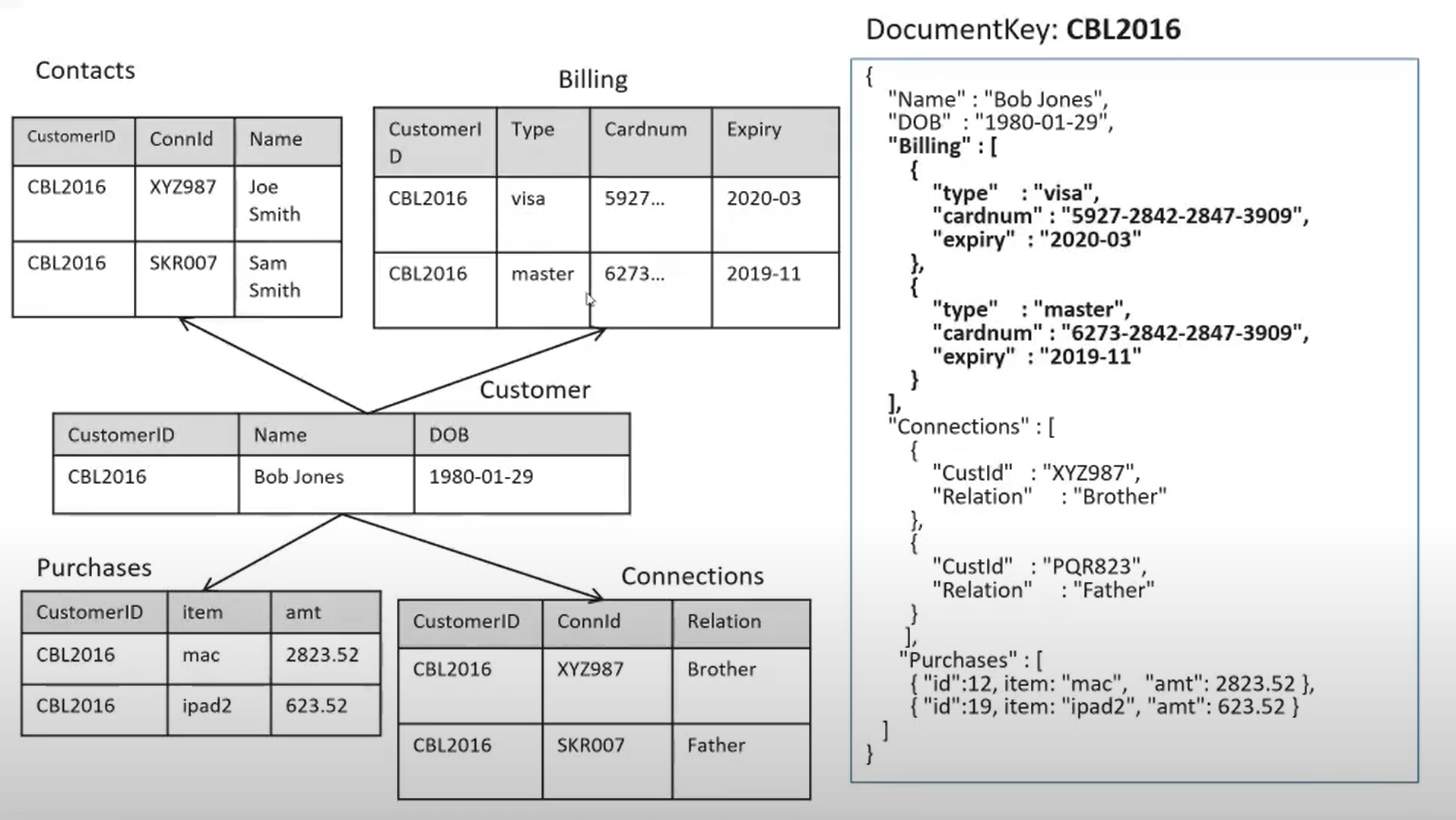
Comparison of a multi-table relational data model to a simplified JSON document.
In the 80s and 90s, application maintenance and delivery cycles often took years to complete. And one of the most time-consuming and dreaded exercises was introducing new database schema changes underneath an application.
Now, developers can add new attributes to a document, essentially extending the schema of that document. With the power of JSON databases, developers control the schema, not the DBA.
For example, when building a document that describes a person, the developer can add and modify attributes as needed. The developer can extend a document that only stored a first and last name to include a home address. Schema flexibility is why developers like JSON databases and Couchbase customer surveys prove that.
JSON databases have a modern advantage as cloud-based infrastructures have commoditized physical storage costs (and RAM to a lesser extent). So ultimate compactness is not as critical as it used to be. Additionally, organizing documents in a JSON database is much more intuitive than relational and other structures.
JSON Data Is Easy to Read
Data in a JSON database is easy to read and write for both people and machines due to its simplicity.
Like JavaScript, documents contain sets of key names associated with attributes or objects. Using white space can make documents more readable for humans.
|
1 2 3 |
<document id>: { <key>: <object>, <key>: <object>, ... } hotel_1: { "name": "Grande Hotel de Paris", "City": "Porto" } |
Various fundamental data types are available to be mixed and matched: text, numeric, lists, and key-value maps. Objects can also hold other objects in a hierarchical form.
|
1 2 3 4 5 6 7 8 9 10 11 |
hotel_1: { "name": "Le Grande Hotel", "url": "https://www.guestreservations.com/grande-hotel-de-paris/booking", "RoomCount": 120, "Amenities": ["Pets Ok", "Pool", {"Parking": ["Valet", "Self"]}], "Address": { "Street": "Rua da Fabrica", "StreetNum": "27/29", "City": "Porto", "Country": "Portugal" } } |
JSON databases require no official schema validation. Applications can use/add/modify the sets of keys and objects as needed. This flexibility removes the need for a DBA to manage application schemas and accelerates “continuous delivery” of microservices.
JSON Schemas Map to SQL Structures
Even though we highlight the optional nature of schemas with the JSON database, we can still apply any needed structure. In a relational table context, JSON document key names can be treated as column names. It becomes a little more complicated when there are hierarchical objects in the document, but functions can help flatten the data (more on that another time).
By mapping the JSON attributes to column names, the general syntax of SQL can be applied. JSON databases can automate this mapping due to SQL’s simple syntax structure, opening a world of possibilities. Developers already know how to use SQL and can use it to accelerate development. It also reduces the need for DBAs and architects to jump in.
JSON Databases Support a Variety of Index Types
JSON databases can also generate column indexes that accelerate SQL data queries. Developers identify the columns their applications will be using, and the backend system automatically maintains the indexes. A variety of indexes can be applied, including primary indexes, global secondary indexes (GSI), and even full-text search indexes.
JSON Data is Easy to Search
Full-text search engine applications are also natural for JSON databases and are made possible through another type of index.
Developers identify which attributes to index and use the programming language SDK to send a search request to the database. The JSON response includes data matches, match statistics, and other metadata that developers use to optimize client applications.
JSON Databases Take Care of Themselves
We’ve now looked at how versatile and powerful JSON databases can be. It’s most important to remember that the database service automatically manages all the configured indexing, partitioning, replication and data access features.
Application developers benefit significantly from this power, focusing on building solutions instead of managing clusters. When adding new documents, the system notices and adjusts, updating indexed data accordingly without user intervention.
Monitoring dashboards provide web interfaces to performance metrics and help show when more nodes or memory may be beneficial. Users can easily add new nodes to a cluster while balancing and replicating data is done automatically behind the scenes. A JSON database can switch off the broken node when there are failures, adjust the data distribution, and notify administrators.
Next Steps
Developers expect data infrastructures to always be there for their applications. With JSON databases like Couchbase, you get flexibility and high performance out of the box.
Learn more about NoSQL JSON databases and Couchbase: