A RoSe by any other case would smell as sweet. William Shakespeare
You must have learned capitalization rules in your grammar school, but the real-world search is not so sensitive to capitalization. Charles de Gaulle uses lower case for the middle “de”, Tony La Russa uses upper case for “La” – there may be etymological reasons for it, but it’s unlikely for your customer service agent to remember. Databases have a variety of sensitivities. SQL, by default, is case insensitive to identifiers and keywords, but case sensitive to data. JSON is case sensitive to both field names and data. So is N1QL. JSON can have the following. N1QL will select-join-project each field and value as a distinct field and value.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT {"City": "San Francisco", "city": "san francisco", "citY": "saN fanciscO"} [ { "$1": { "City": "San Francisco", "citY": "saN fanciscO", "city": "san francisco" } } ] |
In this article, we’ll discuss dealing with data case sensitivity. Your field references are still case sensitive. If you use the wrong case for the field name, N1QL assumes this is a missing field and assigns MISSING value to that field.
Let’s consider a simple predicate in N1QL to lookup all permutations of cases.
|
1 |
WHERE name in [“joe”, “joE”, “jOe”, “Joe”, “JoE”, “JOe”, “JOE”] |
This requires seven different lookups into the index. “John” requires more index lookups and “Fitzerald” requires even more. There is a standard way to do this. Simply create an index by lowering the case of the field and the literal.
|
1 |
WHERE LOWER(name) = “joe” |
This lookup can be made faster by creating the index with the right expression.
|
1 |
CREATE INDEX i1 ON customer(LOWER(name)); |
Ensure that your query is picking up the right index and pushes the predicate to the index scan. And that’s the idea. Queries that have predicates pushed to the index scan run much faster than the queries that won’t. This is true for predicates and true aggregate pushdown as well.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
EXPLAIN SELECT * FROM `customer` WHERE LOWER(name) = "joe"; { "#operator": "IndexScan3", "index": "i1", "index_id": "c117bdf583c2e276", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"joe\"", "inclusion": 3, "low": "\"joe\"" } ] } ], |
Case insensitivity in a composite index scenario.
|
1 2 3 4 5 |
WHERE LOWER(name) = “joe” AND zip = 94821 AND salary > 500 AND join_date <= “2017-01-01” AND LOWER(county) LIKE “san%” |
|
1 2 3 4 5 |
CREATE INDEX i2 ON customer(LOWER(name), zip, LOWER(county), join_date, salary) |
Case insensitivity in Array functions.
String functions like SPLIT(), SUFFIXES(), many of the array functions and object functions do return arrays. So how do you use them in a case insensitive way?
We follow the same principle as before. Create an expression to lower case the values first before you process them via these functions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT SPLIT("Good Morning, Joe") as splitresult; "splitresult": [ "Good", "Morning,", "Joe" ] SELECT SPLIT(LOWER(“Good Morning, Joe”)); "splitresult": [ "good", "morning,", "joe" ] |
Now, what you really want is to filter based on a value within the string.
|
1 |
WHERE LOWER(xyz) LIKE “%good%”; |
This is probably the worst predicate in SQL — in terms of performance.
|
1 2 |
SELECT * FROM customer WHERE x IN SPLIT(LOWER(xyz)) SATISFIES x = “good” END |
Now, what index would you create for this? ADVISE comes in handy.
|
1 2 |
CREATE INDEX adv_DISTINCT_split_lower_xyz ON `customer` (DISTINCT ARRAY `x` FOR x in split(lower((`xyz`))) END) |
As usual, verify your explain.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "#operator": "DistinctScan", "scan": { "#operator": "IndexScan3", "index": "adv_DISTINCT_split_lower_xyz", "index_id": "552ab6c643616fbc", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"good\"", "inclusion": 3, "low": "\"good\"" } ] } ], |
If you’d like to UNNEST and have a simple WHERE clause, use this query. Always verify your explain to ensure the predicates are pushed to index scan.
|
1 2 3 |
SELECT * FROM customer UNNEST SPLIT(LOWER(xyz)) AS x WHERE x = "good" |
Using Tokens
TOKENS() function makes it simple to get the lower case by taking that option as an argument. See the article More Than LIKE: Efficient JSON Searching With N1QL for details and examples
Complex expressions.
|
1 2 3 4 |
SELECT * FROM customer WHERE lower(fname) || lower(mname) || lower(lname) = “JoeMSmith” |
How could we optimize this? Index Advisor to the rescue. Again.
|
1 2 |
CREATE INDEX adv_lower_fname_concat_lower_mname_concat_lower_lname ON `customer`(lower((`fname`))||lower((`mname`))||lower((`lname`))) |
Explain to confirm the plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "#operator": "IndexScan3", "index": "adv_lower_fname_concat_lower_mname_concat_lower_lname", "index_id": "aaa14cbdf14e9cd8", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"JoeMSmith\"", "inclusion": 3, "low": "\"JoeMSmith\"" } ] } ], "using": "gsi" }, |
Bringing in the Big Guns: Full-Text Search
As you’ve realized, this is a text processing and querying problem. FTS can scan, store, search text in various ways. Case insensitive search is one of them. Let’s see the plan for a simple search query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
select * from customer where search (name, "joe") "~children": [ { "#operator": "PrimaryScan3", "index": "#primary", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "using": "gsi" }, { "#operator": "Fetch", "keyspace": "customer", "namespace": "default" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "search((`customer`.`name`), \"joe\")" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "self", "star": true } ] } ] } } ] } |
This is NOT the plan you want…This is using a primary scan!
After creating the text index on the bucket customer, things are much better:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
select * from customer where search (name, "joe") { "#operator": "Sequence", "~children": [ { "#operator": "IndexFtsSearch", "index": "trname", "index_id": "3bdb61e5010e8838", "keyspace": "customer", "namespace": "default", "search_info": { "field": "\"`name`\"", "outname": "out", "query": "\"joe\"" }, "using": "fts" }, |
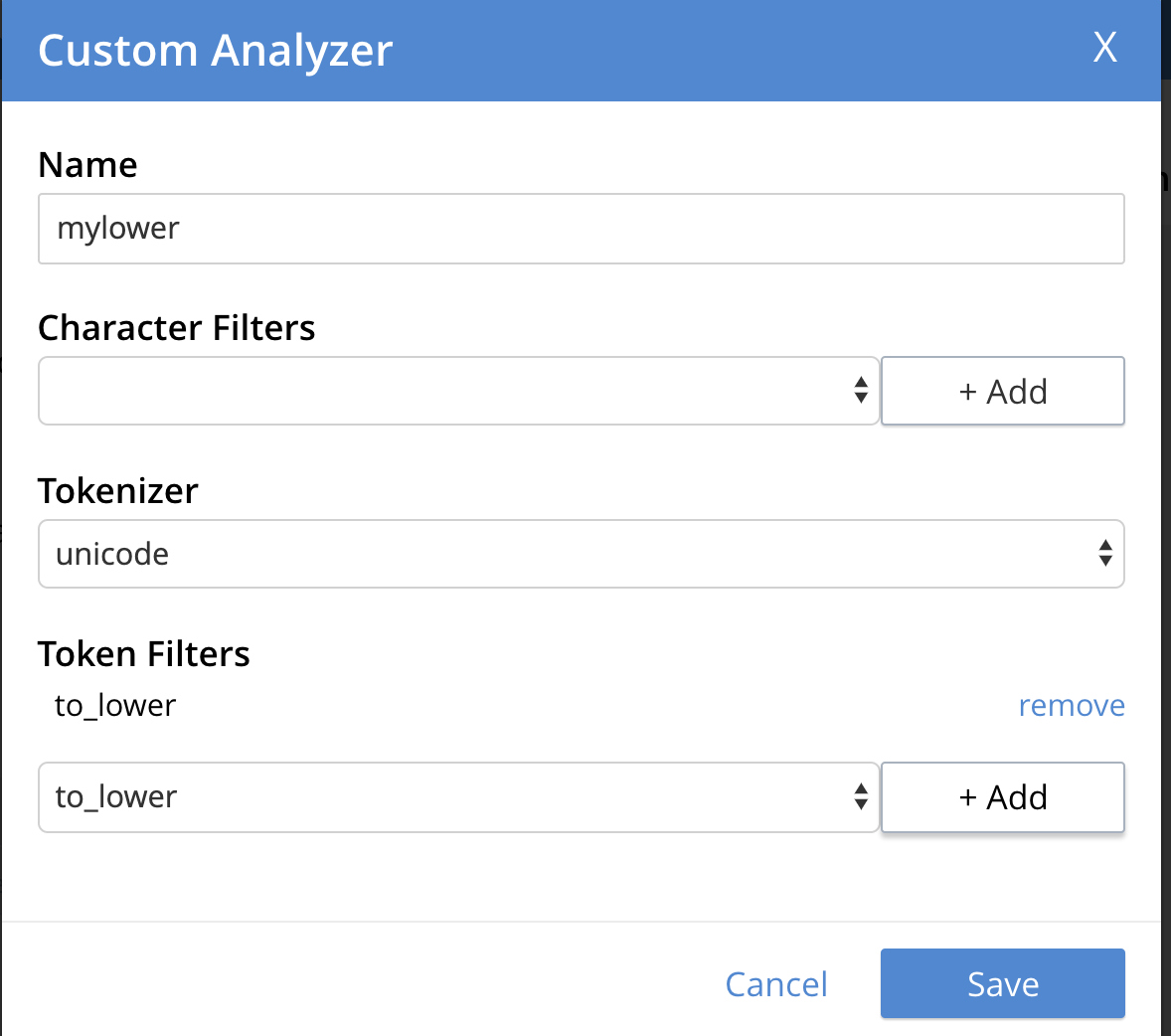
The default standard analyzer lowers all the tokens and therefore you’ll find all the “joe”s : JOE, joe, Joe, JOe, etc. You can define a custom analyzer and provide specific instruction to lowercase the tokens. Here’s an example.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"mapping": { "analysis": { "analyzers": { "mylower": { "token_filters": [ "to_lower" ], "tokenizer": "unicode", "type": "custom" } } }, |
Here’s how you add it in the UI. See fine blog 8 Ways to Customize Couchbase Full-Text Search Indexes for details on various ways to customize the FTS index.