- Solutions
-
-
Adaptive Applications

Get AI-ready with hyper-personalized apps!
Next level customer experiences require adaptive applications
Learn more
-
-
- Developers
-
-
Developer Playground
-
-
- Resources
-
-
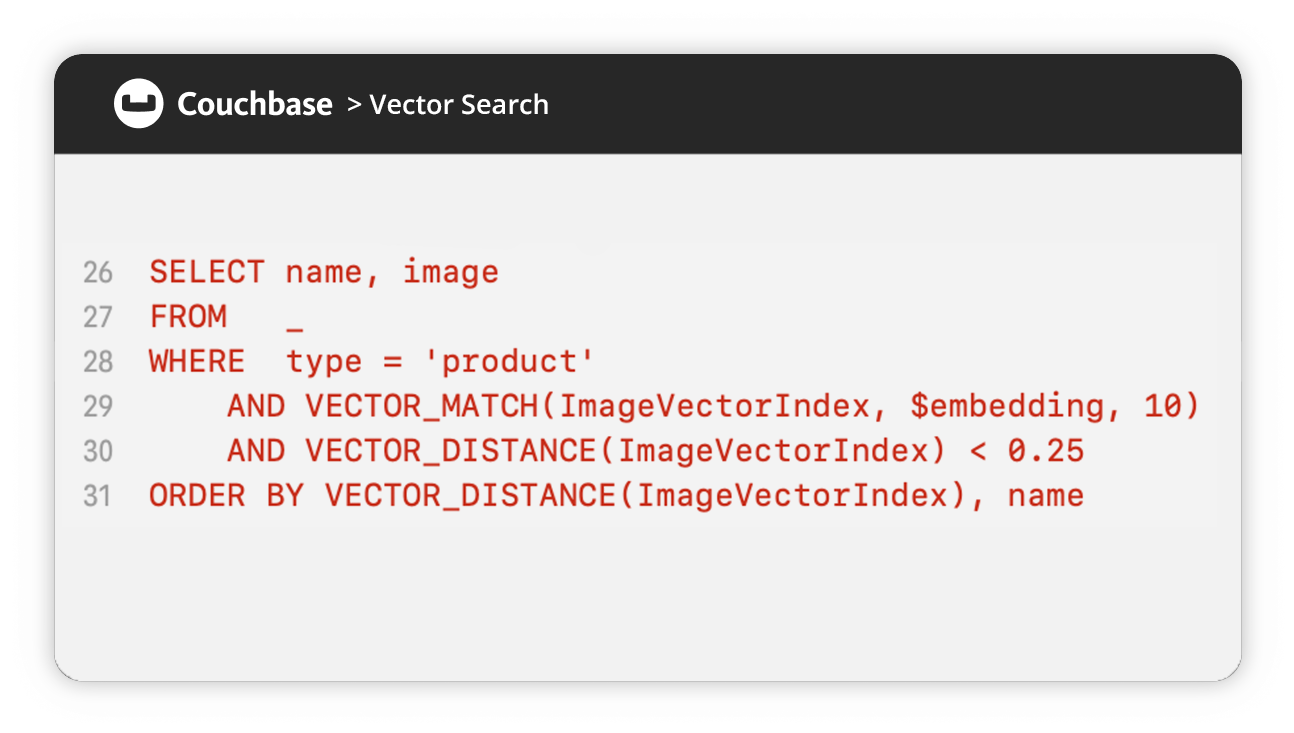
Vector Search
What's Vector Search and why is it important?
Get a quick overview of vectors, vector search, use cases, and key features.
Watch
-
-

What makes Couchbase Server different?
Built as an original multipurpose NoSQL database, Couchbase Server delivers unparalleled performance at any scale, run on-prem or in the cloud. Developers get the benefits of flexible JSON documents and object models, with SQL and key-value access, and hybrid vector and text search all built in – to build features faster. Our AI-powered coding assistant will help you get started. For architects and application owners, our sophisticated in-memory, active-active architecture delivers low latency around the globe – for high speed, no downtime, and happy users.
Enterprises choose Couchbase for its speed, NoSQL versatility, and the ease of SQL++
Fast
The first reason customers choose Couchbase is performance due to its memory-first design and caching architecture.

Affordable
Couchbase does more work for your money due to its scalable, tunable-workload design that optimizes resources as your application grows.
Versatile
Couchbase powers feature-rich and GenAI apps because it handles many data access patterns at once without creating architectural complexity.

Easy as SQL
Use Capella iQ, our AI-powered co-pilot, to write powerful SQL quires including joins and distributed ACID transactions.
Server key capabilities
Couchbase is a distributed, transactional, multipurpose database for AI-powered applications. It does the work of multiple purpose-built databases, including vector and time-series. It caches data for speed, supports SQL for JSON, and scales linearly. It replicates and synchronizes to mobile apps, and helps simplify data architectures without sacrificing application features.

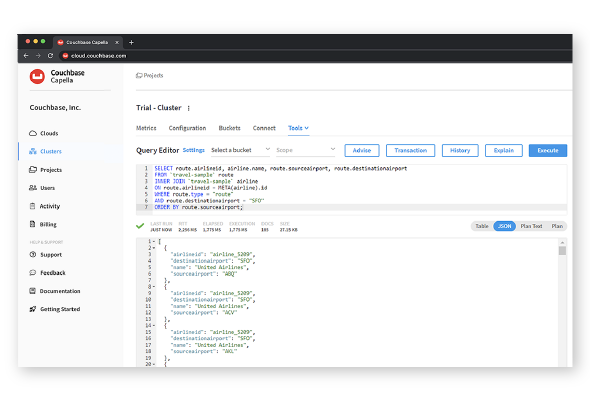
Queries
Build powerful SQL for querying, transacting, and manipulating JSON data with iQ, our AI-powered co-pilot.

Vector and text search
Build better user experiences with smarter, GenAI applications. Add powerful similarity search and natural language conversations to your apps.

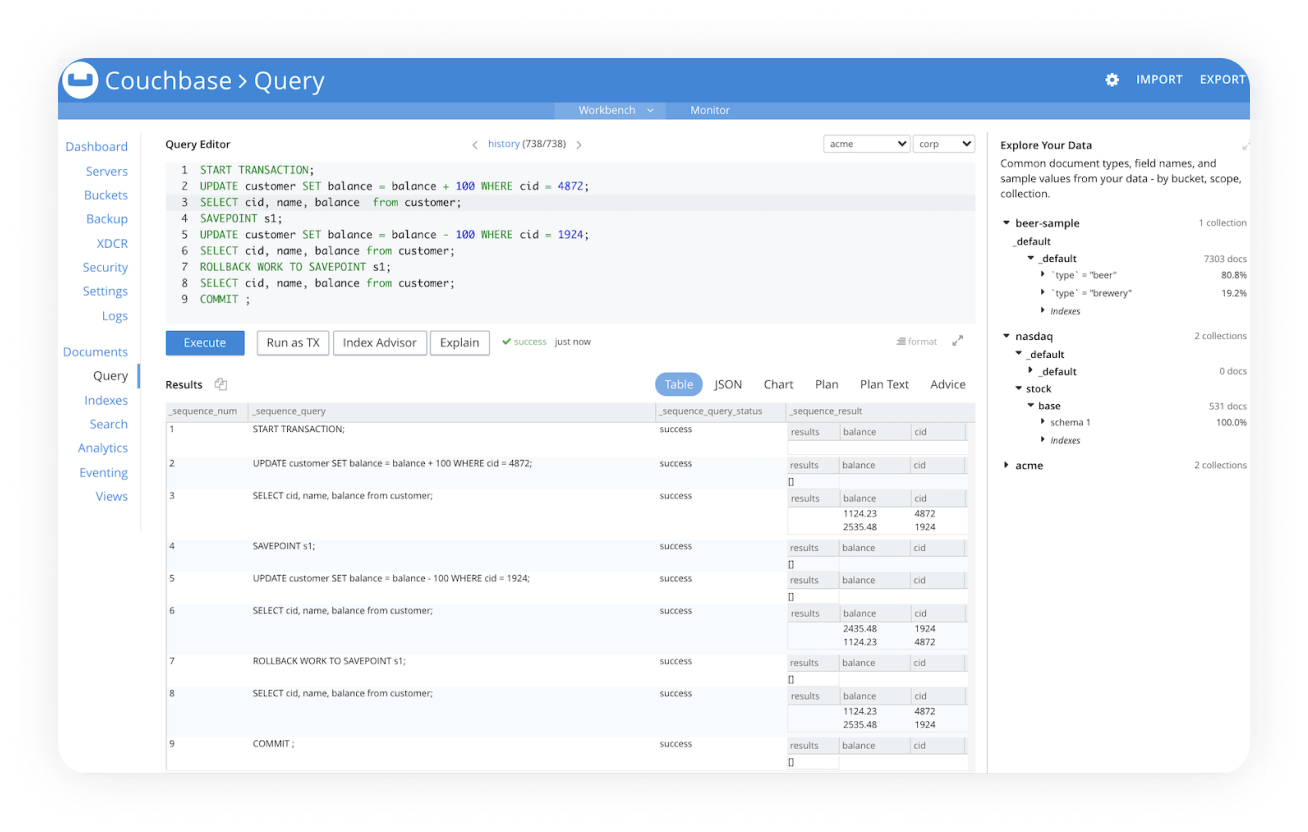
Distributed, multi-document ACID transactions
When transactional guarantees are required, Couchbase holds the patent for distributed ACID transactions for JSON.

Eventing
Couchbase eventing enables user-defined functions in JavaScript or Python to fire in real time when data changes happen.

Analytics
It's no longer impossible to perform analytics on active application data. You just need a SQL++ analytics engine with workload isolation.

Active-active global replication
Ensure high availability everywhere with global cross data center replication (XDCR) that scales across clouds and locations.


Fast: Unparalleled performance at scale
Deliver consistent, fast experiences at scale, powered by caching and our memory-first, active-active architecture. High-performance indexes underpin exceptional data access performance even with complex joins, predicates, and aggregations. And, with efficient, high-density key-value storage that holds terabytes per node, Couchbase significantly reduces the complexity of your clusters and the costs of your deployment.
Versatility of JSON: Unmatched agility and flexibility
Support rapidly changing application requirements with the flexibility of JSON. It can support multiple data access patterns at once, including programmatic key-value, SQL++ query, time-series arrays, vector arrays, graph relationships, metadata, analytics, and text or geographic search. This enables robust functionality within the application without creating unnecessary complexity in the data architecture.
Easy as SQL: Start with Capella iQ
SQL++ is SQL for JSON that supports joins, ACID transactions, user-defined functions, and more. Our iQ co-pilot helps you write SQL on Day 1. Couchbase also supports dynamic schema constructs that map to RDBMS, including buckets, scopes, collections, and documents.

Future-proof: Manage Couchbase your way
Deploy Couchbase Server in any cloud, at any scale. To reduce operational overhead, you can self-manage your deployment, use Kubernetes automation, or choose the fully managed Couchbase Capella™ DBaaS.

What customers are saying


“We said, 'Wouldn't it be nice to have a data store where we could go from the Java object to the database and back without lots of overhead?' Well, this is it.”


“Couchbase is a highly scalable, distributed data store that plays a critical role in LinkedIn’s caching systems.”


“What we value a lot is that Couchbase was able to embrace with us our vision to the cloud, and the fact that we wanted to operate data stores directly on PaaS.”


“The most important thing is the multi-dimensional scaling. Having a few nodes for a specific use case is very powerful.”

Containerized Couchbase

Couchbase architecture under the hood

Altoros benchmark: Couchbase Capella vs. MongoDB, DynamoDB and Redis
Start building
Check out our developer portal to explore NoSQL, browse resources, and take Couchbase for a spin in our playground.
Try Capella
Get hands-on with Couchbase in just a few clicks. Capella DBaaS is the easiest and fastest way to get started.
Try Capella iQ
Use our generative AI-powered coding assistant to create sample data, refine it, and build queries on the datasets.