
As an application architect, eventually, you’d have to choose the database or database as a service (DBaaS) to power your newest application or a micro-service. Selecting one of the databases among relational databases was easier. The use cases were roughly divided into OLTP and OLAP (decision support). The workload differences between OLTP and OLAP were well known. OLTP workloads consist of short transactions on few random rows, expecting millisecond responses on pre-compiled queries; OLAP workloads consist of data loads, long-running queries scanning millions of rows of a fact table of a star/snowflake schema. Each had the performance benchmark and TCO well defined, measured and audited via TPC benchmarks. You can make use of these numbers, approximate your workload, understand the needs and capabilities match on other fronts like administration.
Then, there are No-SQL databases. NoSQL databases were invented to handle the web scale performance of operational applications. It had to be elastic to handle the scale and tolerate nodes going down (aka partition tolerance). That sparked the innovation to create databases on a variety of data models and use cases. There are databases for JSON, graphs, time-series and more. From Azure databases to ZODB, from Couchbase to Cassandra. MongoDB to TiDB, spatial to JSON databases — so many different kinds of databases. In fact, NoSQL-databases.org lists 225 databases and DBaaS as of November, 2018.
E-Commerce applications need to generate the sales report, shopping cart applications need to report outstanding shopping carts, etc. Every application makes progress on the workflow on behalf of its user or customer. These operational queries can be simple key-value operations, short-range queries or complex search queries in NoSQL. This workload is the bread and butter of most businesses.
The solutions for the high-volume transaction and high-volume analysis is seemingly contradictory. The lookup operations or queries (e.g. searching for flights) requires very efficient lookup, quick data flow back to the application. Milliseconds matter.
“By the way, most workloads are mixed workloads” — Larry Ellison, Founder & CTO of Oracle.
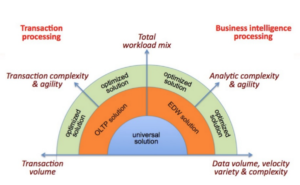
Source: BI Research
Recognizing the need to address mixed workloads, OLTP databases have added features for complex queries (e.g. hash joins, window functions), NoSQL databases have added SQL. SQL databases have added JSON. We may be reaching the state of the paradox of choice!
Until we have a universal solution, we’d need to evaluate and stitch different products and services to provide the solution to support the business workload and business outcome. E.g. You could run SQL Server for the OLTP and Teradata for OLAP. Use Couchbase for an e-commerce application and Hadoop for machine learning. First, you’ll have to drill down the workload to understand the operations within a workload.
So, what’s a workload?
The article What’s your definition of the workload? gives examples database workload from various angles. Application designers may define by the application SLAs at a given concurrency. DBAs may define the workload by the CPU, memory usage, I/O throughput, etc. The advice is to understand the resource usage and tie them to higher level entities like the queries, users, and applications.
TPC-C describes the benchmark workload and measurement in the following way: The most frequent transaction consists of entering a new order which, on average, is comprised of ten different items. Each warehouse tries to maintain stock for the 100,000 items in the Company’s catalog and fill orders from that stock. However, in reality, one warehouse will probably not have all the parts required to fill every order. Therefore, TPC-C requires that close to ten percent of all orders must be supplied by another warehouse of the Company. Another frequent transaction consists in recording a payment received from a customer. Less frequently, operators will request the status of a previously placed order, process a batch of ten orders for delivery, or query the system for potential supply shortages by examining the level of stock at the local warehouse. A total of five types of transactions, then, are used to model this business activity. The performance metric reported by TPC-C measures the number of orders that can be fully processed per minute and is expressed in tpm-C.
For modern applications, as an architect, you’ll have to understand all of the application operations, patterns, and their SLAs. Application performance isn’t measured by a simple benchmark, but its ability to perform at the business scale over a long period of time. Adding the period of time factor means, you’ll have to consider the scale, SLA and cost of the infrastructure on a slow summer day and the day 100 million customers on your site trying to add their favorite toy to the shopping cart and buy it.
- What are the application requests to the database?
- Simple operations to get and set data (e.g.new customer, new order)
- Search requests (search for products, orders, etc)
- Pagination requests (list a customer orders, sorted by date)
- Reporting workload.
- Queries from business intelligence tools.
- As the number of concurrent users increase, which of these operations need to scale?
- What’s the trigger point in the workload to add or remove database nodes?
- What’s the failover strategy?
Comparing NoSQL Databases:
Relational databases (aka SQL databases) had the same relational model, roughly same data types, implemented similar SQL. The difference was in performance, which could be measured by TPC benchmarks, ease of administration, which was more subjective.
Variety is the name of the game for No-SQL databases. There are specialized databases for key-value, JSON, wide-column, graph, timeseries and spatial and more. These represent different data models and various operations that can be done effectively in this model. Each of them their own APIs, query languages, performance characteristics, scaling capabilities.
If you showed the pending orders for a user in the app before, you still need to do that with the new database. You may change how you achieve the same result, but not the result itself. This gets us back to the workload. You’ll have to understand the full application workload and the database workload it generates. Then do the performance, scaling measurement and scaling. The simple use cases, YCSB benchmark will help, but for complex use cases, YCSB-JSON can be used. This exercise will require you to translate the workload into respective database operations and measure them. Measure them for each of the critical operations as well as system characteristics like elasticity, replication speed, and failover.
The critical lesson while evaluating databases for your workload is:
The business and application requirements on the database won’t change just because you can use a new kind of database.
To summarize, the workload is described by the modified Pink Floyd lyric. (With apologies to Roger Waters).
Database Workload
All that you cache
And all that you flush
All that you shard
All you hash
All that you scale
All that you fail
All you test
All you save
All that you share
And all that you store
And all that you transact
Begin, commit or rollback
All you create
And all you do
And all that you undo
And all that you redo
And all that you delete
And every node you add (every node you add)
And all that you search
And every key you index
And all that is planned
And all that is run
And all that’s to change
And everything under the (data)base is in tune
But the base is running on the cloud