
I'm excited to announce Multi-Dimensional Scaling.
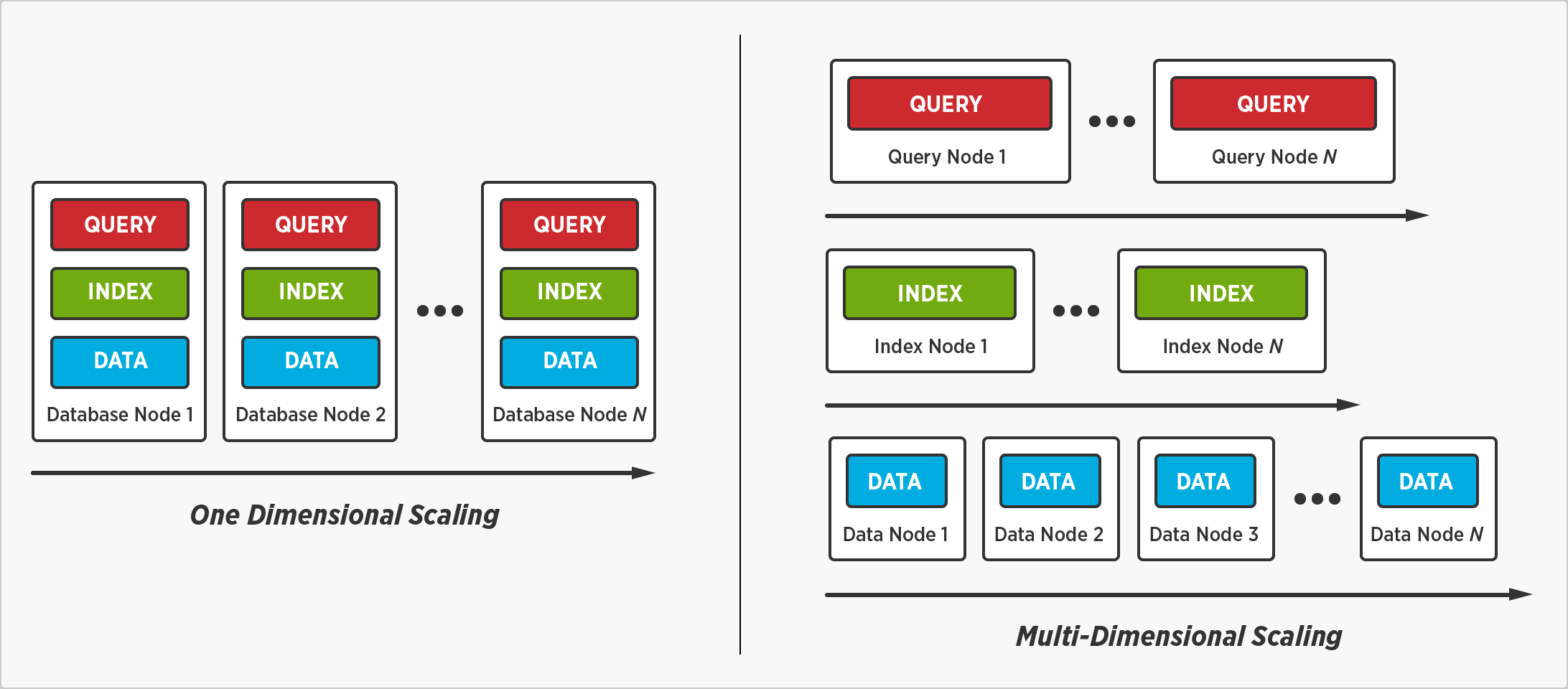
We've reimagined and redefined the way enterprises scale a distributed database with Multi-Dimensional Scaling. It's the option to separate, isolate, and scale individual database services – query, index, and data – to improve performance and resource utilization.
Distribute Data, not Query Execution and Indexes
Multi-Dimensional Scaling enables us to distribute data without distributing query execution and indexes. A query will complete faster when it't not executed on every node, and an index will be searched faster when it’s not stored on every node.
Optimize Hardware for the Service, not the Database
Multi-Dimensional Scaling enables us to support multiple hardware profiles by running different services on different nodes. As a result, every single node doesn't require the fastest processor, the fastest solid state drive, and the most memory.
- While query nodes require a faster processor, index and data nodes do not.
- While index ndoes require a faster solid state drive, query nodes do not.
- While data nodes require more memory, query and index nodes do not.
Eliminate Resource Contention
Multi-Dimensional Scaling enables us to eliminate resource contention by running different services on different nodes. When queries are executed on separate nodes, there’s no CPU contention between queries and reads or writes. When indexes are stored on dedi nodes, there’s no disk IO contention between indexes and reads or writes.
Multi-Dimensional Scaling improves performance by:
- Storing data and indexes on separate nodes – no disk IO contention
- Storing data and executing queries on separate nodes – no CPU contention
- Executing a query without distributing it to every node – no network overhead
- Storing an index without distributing it to every node – no network overhead
Multi-Dimensional Scaling improves resource utilization by:
- Configuring query service nodes with fast processors, no SSDs, and less memory
- Configuring index service nodes with fast SSDs and less memory.
- Configuring data service nodes with more memory and an HDD or SSD.
Concepts
Elastic Services enable independent scaling of the data, index, and query services. The data service can be scaled without scaling the query or index services.
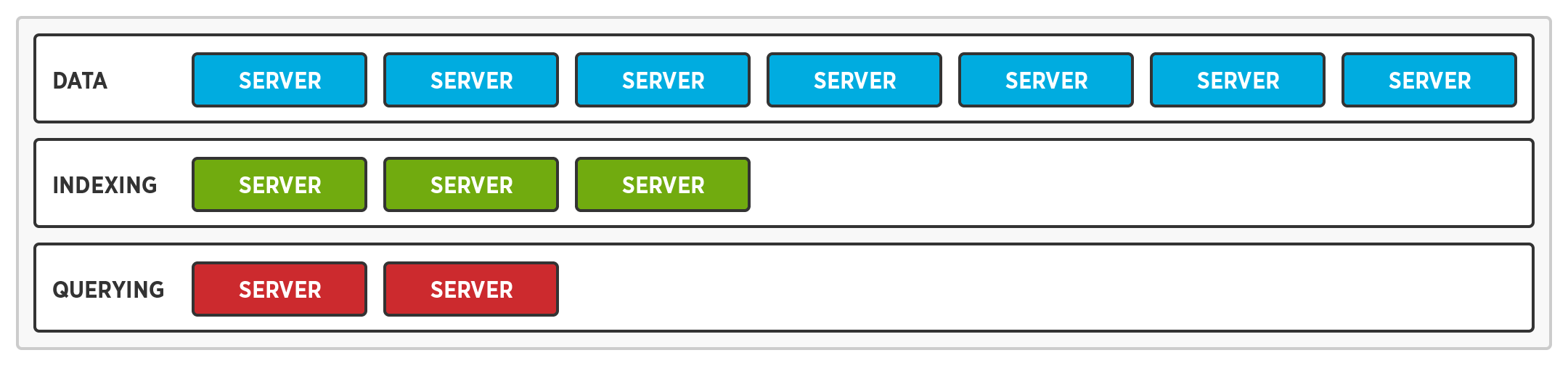
Service Optimization allows the hardware for a node to be optimized based on the service it’s running. After all, the hardware requirements for the query, index, and data services are different.
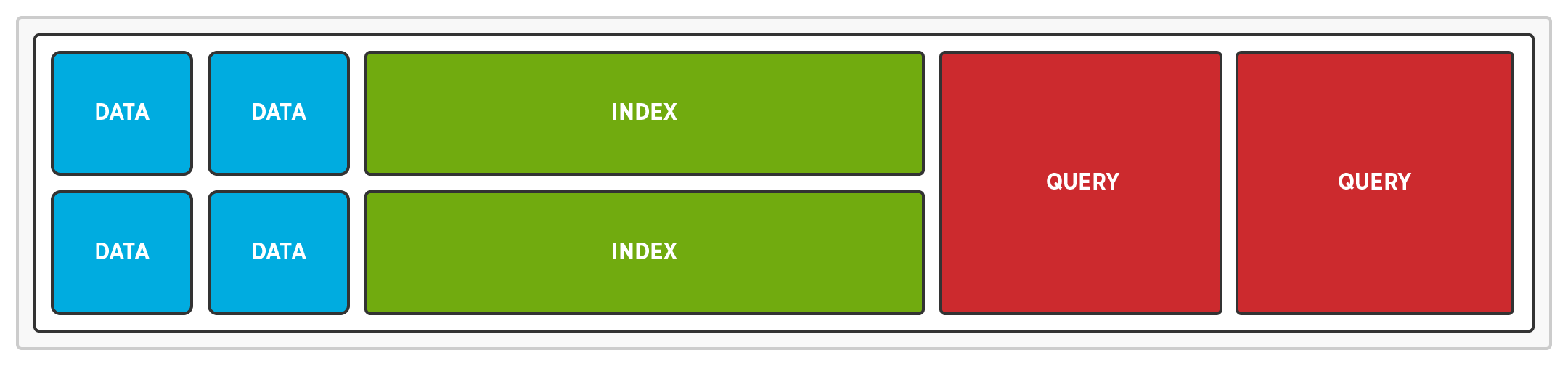
Service Isolation ensures the query, index, and data services do not suffer from resource contention. It isolates query, index, and data services to prevent queries and indexes from slowing down reads and writes.

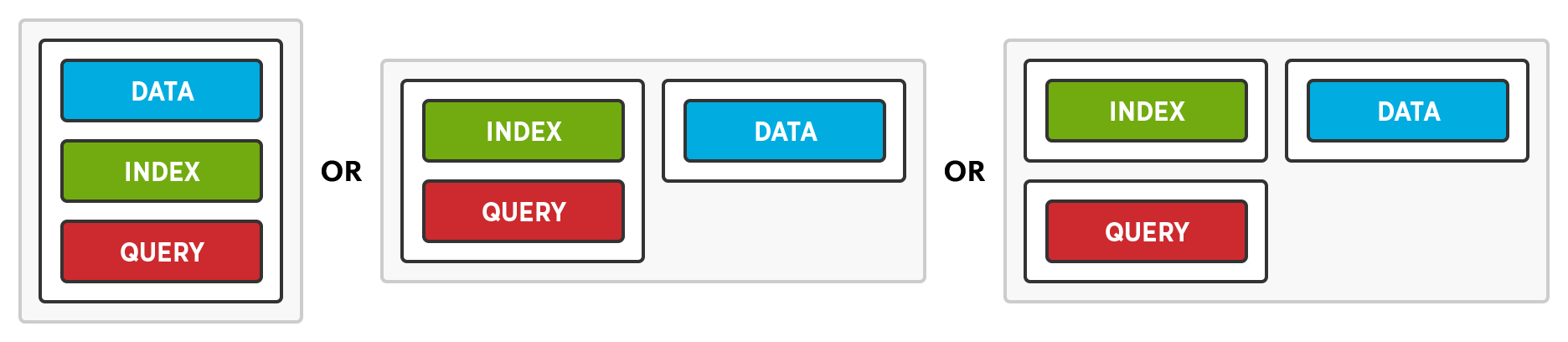
Flexible Deployment enables administrators to decide whether or not to leverage Multi-Dimensional Scaling. When a node is added, administrators can enable all of the services, some of the services, or just one of the services.
Learn more about Multi-Dimensional Scaling and find out what's coming in Couchbase Server 4.0 here.
Discuss on Hacker News
You guys ever thought about data-locality? Sharding by a custom-column
like \”user_id\”, this way all the data will be in 1 node and
complex-queries will be faster since no data will be transferred between
nodes.
Or even sharding by a subset of the primary-key (like regex sharding done by redislabs)
Thanks for the mention – I\’m glad you like the regex sharding feature, we\’re quite proud of it :)
Would that not limit queries to a single field – the custom column? You could shard by user city and query users by city, but what if you want to query users by age too? What if your query joins users and purchases?
If you want you query to hit a specific node/shard you have to include the \”user_id\” and add other clauses.
If you want to query by another attribute (get all users where age) then you\’ll hit every node.
The problem with your way, is that you store index in a separate node (so you\’ll ALWAYS have cross-node traffic for even basic queries \”select column from user where whatever_filter (column is not indexed))\”.
In your case, each query will hit every index node, however fast they may be they will crumble after some time since every node will have to respond to every query even if all data is in memory theres only so much cpu each server has.
THE only way to have REAL scalable (you can\’t build applications with JUST kv-access, you can build only some features) is to go the automatic-range-partitioning way (like hbase,hypertable,).
Other way (easier to do, less features) is to make sharding by a custom column.
That\’s the benefit of MDS. We will not hit every node. I can create an index for city. The entire index will be stored on one of the index nodes. A query node will send a request to this index node. It will return all matching user ids (city=Chicago). The query node will then get those users (and only from the nodes that contain them). It doesn\’t have to send a request to every node.
And if the index grows larger than 1 node ?
I think we\’d consider breaking up an index and storing it on multiple index nodes. However, I can\’t help but wonder how many indexes will require terabytes of disk space seeing as they\’ll be compressed with Snappy.
Suppose you want to index every object in your table(you usually do). Now, every insert/update/delete has to go to that 1 index-node.
The most frequent way is to colocate data+index in the same node.
Sort of, indexes will be updated asynchronously by default. They will not slow down writes regardless of how many there are. That being said, a query can be submitted with an option to force an index update first. A couple of the problems with co-locating data and indexes are network overhead and joins. It\’s the most frequent way because a) it\’s easy and b) other vendors have been willing to exclude joins. As a reminder, we\’re talking about secondary indexes, not the primary index.