
This week our Community Writing blog post comes from Nick Cadenhead

Nick originally trained as a software engineer, he has spent the past 15 years using his technical expertise to provide specialist consulting services on key accounts. Currently Senior Consultant at 9th BIT Consulting, Nick is responsible for supporting the sales team in the development of new accounts, and the nurturing of current customers and partners by providing pre- and post-sales support including professional services
Nick’s areas of expertise lie in Middleware Integration, Business Rules Management and Business Intelligence (BI), specifically centred around presentations and demonstrations, the delivery of proof of concepts and pilots, as well as technical support. He enjoys strategic relationship building and uses his broad technical knowledge to help customers get the most out of their investment. For some time, I have been working with the Couchbase NoSQL database solution and it’s been an interesting journey so far.
Historically, I’m not a database guy so I’ve not worked much with databases in terms of designing, building and maintaining them as a full time job. However, I do know the basics. This position has allowed me to get into the “mindset” of NoSQL database concepts like no structures, no transactions, denormalizing of data and more without having much conflicting situations with the paradigms of the structured world of SQL and relational databases.
During my sales engineering activities supporting Couchbase proof of concepts (POC) engagements, there is always a requirement to ingest data in a Couchbase bucket (think of a bucket as a relational database) in order to demonstrate and highlight the features and capabilities of Couchbase. Usually data ingestion requires some code to be written to ingest data into Couchbase. Couchbase provides quite of few SDKs (Java, .Net, Node JS and more) for developers to enable their applications to use Couchbase.
So this got me thinking. Why can’t there be a standard way or tool for that matter to ingest data into Couchbase instead of writing code all the time? Don’t get me wrong. There’s nothing wrong with writing code!
Then I came across Streamsets.
Streamsets is an open source platform for the ingestion of streaming and batch data into big data stores. It features a graphical web-based console for configuring data “pipes” to handle data flows from origins to destinations, monitoring runtime dataflow metrics and automates the handling of data drift.
Data pipes are constructed in the web-based console via a drag and drop process. Pipes connect to origins (sources) and ingest data into destinations (targets). Between origins and destinations are processor steps which are essentially data transformation steps for doing field masking, field evaluating, looking up data in a database or external cloud services such as Salesforce.com, doing expressions on fields to route data, evaluate/manipulate data using JavaScript, Groovy and many more.
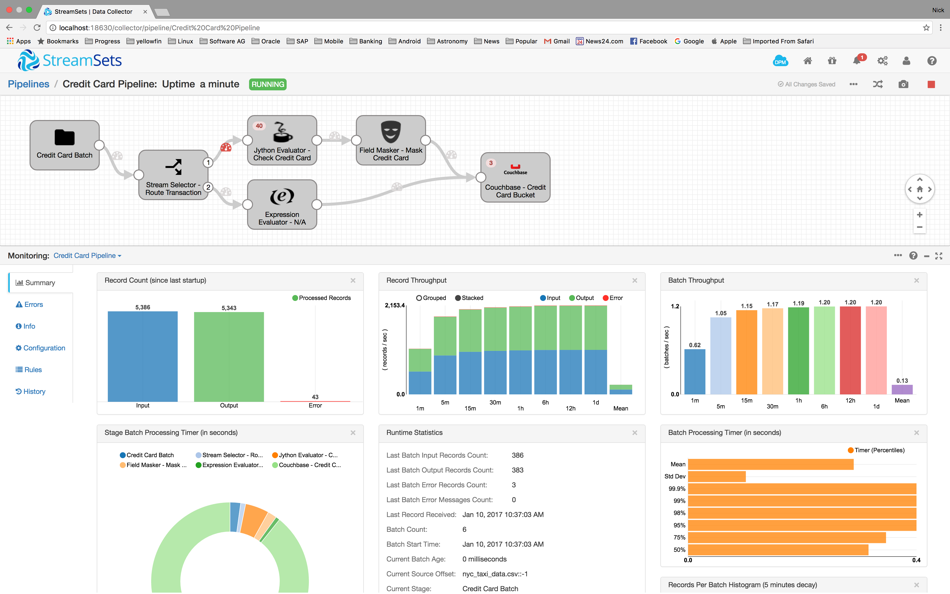
Figure 1: A Streamset pipeline ingesting data into a Couchbase Bucket
Thus Streamsets is a great option for my data ingestions needs. It’s open source and available to download immediately. There are a large number of technologies supported for data ingestion ranging from databases to flat files, logs, HTTP services and big data platforms like Hadoop, MongoDB and cloud platforms like Salesforce.com. But there was one problem. Couchbase is not on the list of technology data connectors available for Streamsets. No problem! I decided to write my own data connector for Couchbase.
Leveraging the Data Connector Java-based API available for the open community to extend the integration capabilities of Streamsets, together with the online documentation and guides, I was able to implement a data connector very quickly for Couchbase. The initial build of the connector is very simple; just ingest JSON data into a Couchbase bucket. Overtime the connector will be expanded to query a Couchbase bucket, better ingestion capabilities and more. For now, it serves my needs.
One of the added benefits with Streamsets is data pipeline analytics. The analytics features in the Streamsets console gives users an insight into how data is flowing from origins to destinations. The standard visualizations in the Streamsets console gives detailed analysis on the performance of the data pipeline. The analysis of the pipeline showed me very quickly how my data was being ingested into the Couchbase Buckets and highlighted any errors which occurred throughout the stages of the data pipeline. So by using data pipelines in Streamsets, they allow me to ingest data very quickly into Couchbase without writing much or no code at all.
The data connector is open and can be found at the following Git Hub link: