
Index builds and updates just got a big performance upgrade with the introduction of Scopes and Collections in Couchbase 7.
The Couchbase Server 7.0 release introduces the separation of Bucket data into logical Scopes and Collections on top of the JSON document database. This separation lets you organize your data into different schemas and tables – concepts most RDBMS users are already familiar with. In addition, Scopes and Collections enable finer role-based access control to the data you’ve stored in Couchbase.
Note: The introduction of Scopes and Collections doesn’t mean that data of a specific type has to be separated and stored in its own Collection. It’s actually the opposite: a Collection is first and foremost a collection of JSON documents, and as such, you retain all the flexibility of a schema-less database. Or, rather, you create the schema your application demands.
With these Index Service optimizations, you might decide to migrate from the Bucket model to the new Collections model – or you might already have a well-configured Couchbase cluster. In this article, I’ll show you a few ways that the Index Service has been optimized to help you decide what’s best for your deployment. Let’s dive in.
The Index Pipeline for the Bucket Model
The diagram below shows the index build pipeline under the Couchbase Bucket model.
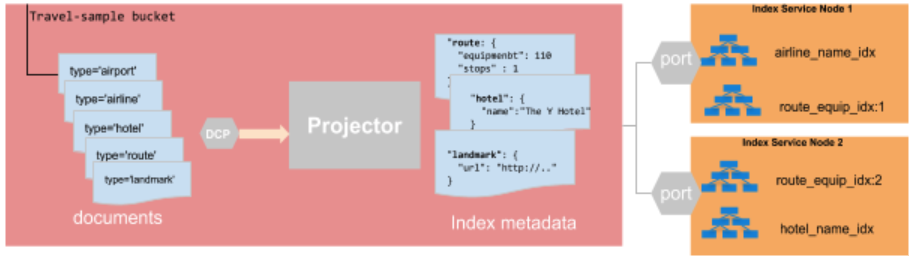
- The projector process in the Data Service is solely responsible for streaming the Bucket data to the Indexing Service.
- The projector uses a single Database Change Protocol (DCP) stream to evaluate all mutations to determine if a document should be streamed to the Index Service, based on the index metadata.
- The projector streams only the specific columns that the Index Service maintains for its indexes.
If it wasn’t clear in the above diagram, the projector has to consider all Bucket mutations for all of the indexes in the cluster.
The Index Pipeline for the Collection Model
In the new Collection model of Couchbase 7.0, DCP streaming between the Data and Index Service is at the Collection level. While this change implies more DCP streams, it actually benefits downstream processing when the projector decides which Index Service it will send the mutations to.
There is a small difference on how this works for the initial index build vs. the index updates. First, let’s look at the initial index build process under the new Collections model.
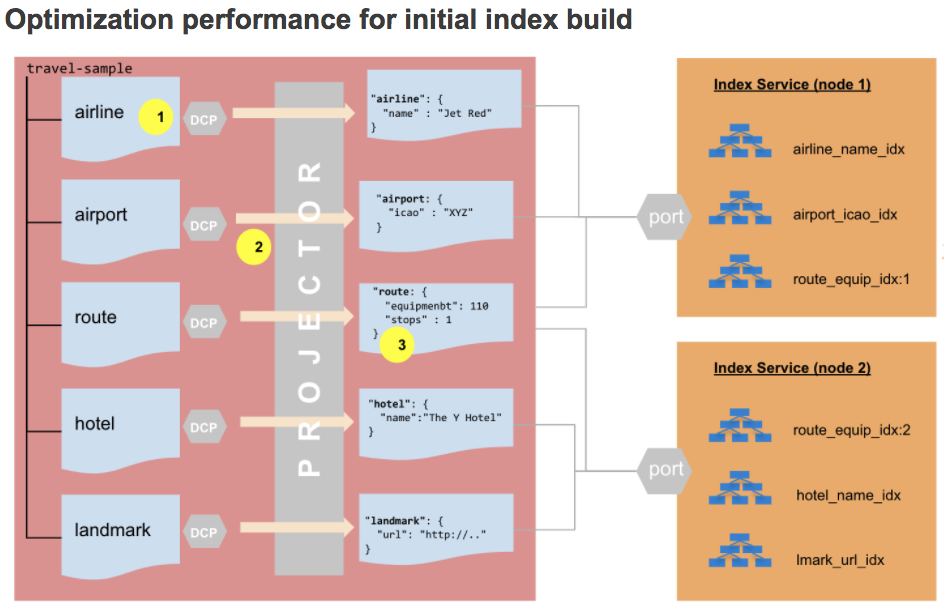
- Indexes are created on a per-Collection basis.
- A DCP stream is created for each Collection during the initial index build, resulting in a smaller workload for the projector.
- The projector no longer needs to evaluate the index
WHEREclause to determine if a mutation qualifies for the index.
Now let’s take a look at the new index update process in Couchbase 7.0:
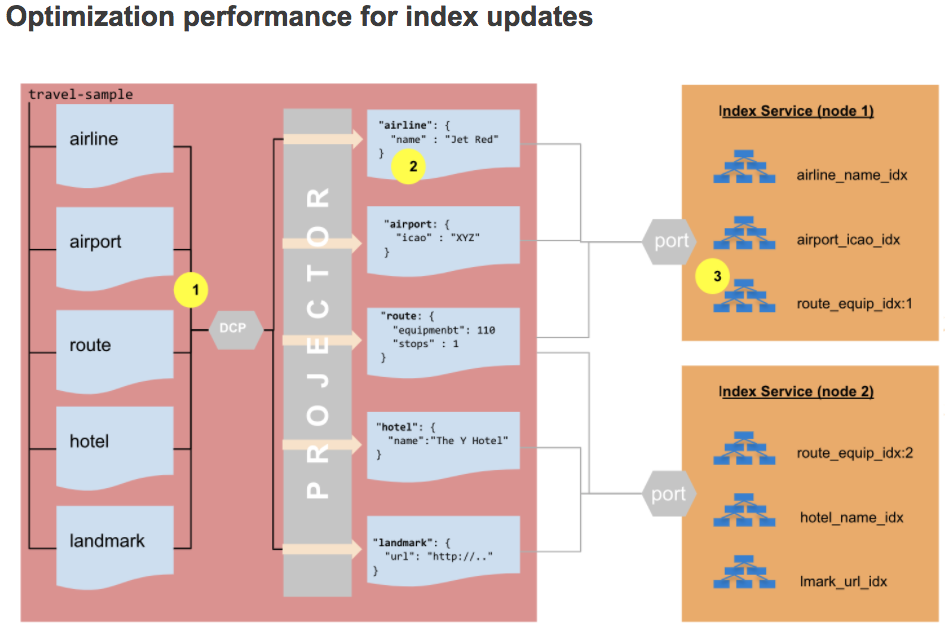
- The DCP stream data is now prefixed with
collection idso the projector knows which index to send the change to. - The projector no longer needs to evaluate the index
WHEREclause. - The index ingestion check is limited to indexes defined on the updated document’s Collection, instead of all indexes in the Bucket. This limitation results in significant savings in terms of CPU and disk I/O
Conclusion
From a configuration standpoint, the introduction of Couchbase Collections doesn’t require you to change anything for the Index Service. However, you do need to specify the Collection name – instead of just the Bucket name – when creating indexes on a specific Collection.
The 7.0 release implemented these changes to give you the advantage of working with smaller datasets instead of handling mutations across an entire Bucket. This small-data benefit permeates all the stages of the Index Service – from the projector through the indexer to the downstream storage layer.
If you want to learn more about the Couchbase Server 7.0 release, check out What’s New and/or the 7.0 release notes.
Give the new Index Service a test drive with your dataset:
Try out Couchbase 7.0 today
Try out Couchbase 7.0 today
Very good blog post, love it!