
Index partitioning is a new feature available in Couchbase Server 5.5.
Check out the Couchbase Server 5.5 Developer Build announcement and download the release for free right now.
In this post, I’m going to cover:
- Why you might want to use index partitioning
- An example of how to do it
- Partition elimination
- Some caveats to be careful with
Index partitioning
When developing your application, you may want to take advantage of Couchbase Server’s ease of scaling to give more resources to indexing. With multi-dimensional scaling (MDS), one option is that you can add multiple high-end machines to the cluster with index capabilities as you need them.
To take advantage of multiple nodes with index services, you would have to create index replicas. This is still possible, and if this is working for you, it’s not going away.
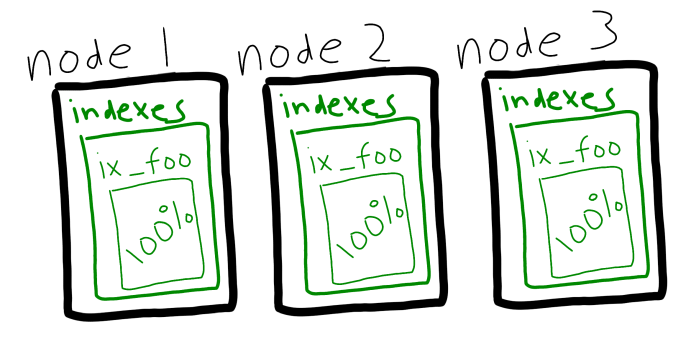
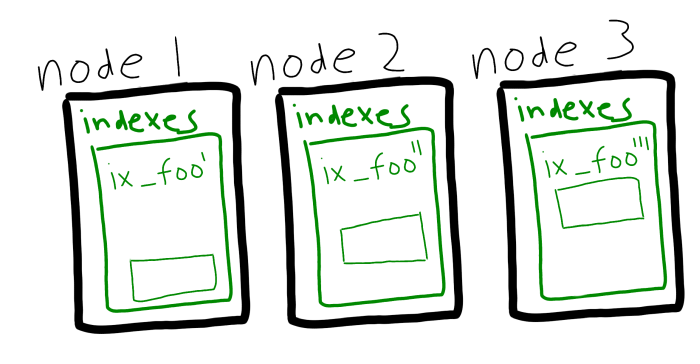
Couchbase Server 5.5 is introducing another way to spread the index load around: index partitioning. Instead of replicating an index, you can now split up the index amongst the nodes with hashing.
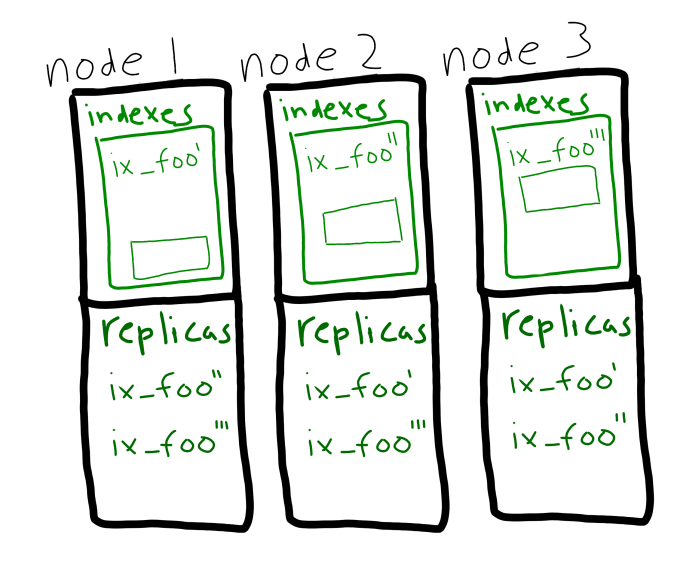
And, you can use partitioning and replicas together in concert. Index partition replicas will be used automatically, and with no interruption if a node goes down.
The primary benefits to index partitioning:
- The index scan load is now balanced amongst all the index nodes. This leads to a more even distribution of work and better performance.
- A query that uses aggregation (e.g.
SUM+GROUP BY) can be run in parallel on each partition.
How to use index partitioning
The syntax for creating an index partition is PARTITION BY HASH(<field>). For example, if I wanted to create a compound index on the “travel-sample” bucket for fields airline, flight, source_airport, and destination_airport:
|
1 |
CREATE INDEX ix_route ON `travel-sample` (airline, flight, source_airport, destination_airport) PARTITION BY HASH(airline); |
When you create this index, it will show as “partitioned” in the Couchbase Console.

Partition elimination
Partition elimination is one of the benefits of using index partitioning. This is a feature that is unique in the NoSQL market to Couchbase.
Let’s say you have a partition on the airline field, as above. Next, write a query that uses that index and specifies the airline value:
|
1 2 3 4 |
SELECT t.* FROM `travel-sample` t WHERE airline IN ["UA", "AA"] AND source_airport = "SFO" |
Then, the indexing service will only scan the matching partitions (“UA” and “AA”). This leads to a faster range query response, and the same latency as a non-partitioned index, regardless of cluster size. More on this later.
Index partitioning caveats
You may have noticed that “airline” was used in the above CREATE INDEX command. When using index partitioning, you must specify one (or more) fields to give to the hash to use for partitioning. This hash will determine how to divide up the index.
The simplest thing you can do is use the document key in the hash:
|
1 2 |
CREATE INDEX ix_route2 ON `travel-sample` (airline, flight, source_airport, destination_airport) PARTITION BY HASH(META().Id); |
But unlike Couchbase’s key-value engine, you can use whatever fields you like. But you must keep in mind that these fields should be considered immutable. That is, you shouldn’t change the value of the fields. So, if you have a field with a value that does not typically change (many Couchbase users create a “type” field, for instance), that would be a good candidate for partitioning.
If you choose to index on an “immutable” field, be warned that this may also cause some skewing of the partition (using META().Id will minimize the amount of skew). If you partition on the “type” field, where 10% of documents have a type of “order” and 90% of documents have a type of “invoice”, then the partition is likely to look similar. Index partitioning uses an optimization algorithm to balance RAM, CPU and data size during rebalancing, but skewing is still going to be a possibility.
So why wouldn’t you use META().Id to reduce skewing? Recall the partition elimination section above. If your queries fall along the same lines as your index partitions, then you are minimizing the “scatter+gather” operations having to check all partitions, and you can further reduce latency.
One more caveat: index partitioning is an Enterprise Edition only feature.
Summary
Index partitioning allows you to more easily and automatically scale out your indexing capabilities. If you are using a lot of N1QL queries in your project, then this will come in very handy and make your job much easier.
If you have any questions about index partitioning or anything else with indexing, please check out the Couchbase Server Forums or the N1QL forums if you have questions about creating indexes and queries. Be sure to download the Couchbase Server 5.5 release today, and try it out. We’d love to hear your feedback.
You can reach me by leaving a comment below or finding me on Twitter @mgroves.