
Getting the Couchbase server to run on your PC or Mac involves a few simple steps to download the software and spin up a cluster with all the Couchbase services that you need (https://docs.couchbase.com/server/6.0/getting-started/start-here.html). Sample buckets are available with the software for you to begin using the product in a matter of minutes.
If you need to migrate your relational database to Couchbase, there are connectors available (https://docs.couchbase.com/server/6.0/connectors/intro.html) that would enable you to achieve the goal. However if you are familiar with both RDBMS and Couchbase database tools, you could leverage your database data exporting tool, then use Couchbase cbimport to load the data into a Couchbase bucket.
With either approach, you will still need to make a few decisions, because of the differences between the databases:
- RDBMS tables vs. Couchbase buckets.
- Database primary keys and bucket document keys.
- Last but not least, how to transform your relational database schema to a Couchbase JSON document database.
In this blog, I will discuss these differences, and outline the different strategies that you could consider to transform your relational database schema to the Couchbase NoSQL database. While the migration technique can be generalized for many RDBMS, the actual process of querying the source database leverages its specific REST APIs. For this reason, I will use Oracle and its sample HR schema as the source data, and leverage its REST Data Services for the data extraction.
What tools do you need
The migration techniques in this blog leverage the basic services of the Oracle database and the Couchbase N1QL Query language. You do not need anything else.
How to use these migration techniques
The provided N1QL scripts address the first two issues of document type and document key. For the transformation of the relational schema to Couchbase JSON database, the scripts cover these three scenarios:
- Direct mapping from table to document type. No transformation is involved.
- Denormalization of parent into child object.
- Denormalization of child objects into the parent as an array field.
The above scenarios, with the document type and document key solutions, should cover the majority of the use case to transform a relational schema to a JSON document database.
The prerequisites
- Access to an Oracle Database Server with the HR sample schema.
- Access to a Couchbase Database, where you need to create a bucket cbhr as the target for the Oracle HR schema migration.
The steps
- Enable your Oracle schema for REST Data Services access.
- Set up a Couchbase server and configure the bucket to receive the Oracle HR data.
- Decide on the data model transformation techniques for your migration requirement.
- Edit and execute the N1QL script to migrate the data.
Oracle Database with the HR schema
The Oracle HR schema is available in your Oracle installation. Please follow the Oracle documentation to deploy the schema. https://docs.oracle.com/cd/E11882_01/server.112/e10831/installation.htm#COMSC001
Enable Oracle schema for REST services
By default, the Oracle REST data service is not enabled on schema. You will need to enable this for the HR schema.
Login as the user who will issue the REST calls. For this example, login as hr, and run the following script.
|
1 2 3 4 5 6 7 8 |
BEGIN ORDS.ENABLE_SCHEMA( p_enabled => TRUE , p_schema => 'HR' , p_url_mapping_type => 'BASE_PATH' , p_url_mapping_pattern => 'hr' , p_auto_rest_auth => FALSE); commit; END; |
Reference: https://blogs.oracle.com/oraclemagazine/get-your-rest-post-your-sql
Verify that you can query your Oracle with a REST call. http://<your-oracle-server>:8080/ords/hrrest/employees/
Note: By default, Oracle REST Enabled SQL service is turned off. To configure REST Enabled SQL service settings, see Configuring REST Enabled SQL Service Settings.
Prepare your Couchbase server
There are two steps that you need to complete in the setup of the Couchbase server.
- Create a bucket with the name
cbhr. The size of the bucket will depend on the volume of the data that you plan to migrate. - Ensure that you enable the CURL() Function Access in the Couchbase Server setting.

3. You will also need to create a primary index on the cbhr bucket to allow the N1QL to query the bucket as part of the migration.
|
1 |
CREATE PRIMARY INDEX `#primary` ON `cbhr` |
Data Model transformation
Migration from Relational to NoSQL is a big step, and this blog does not cover the pros and cons of each of these databases. However, because of the differences on how the data is stored, you will need to make a decision on how you want to manage these changes. The N1QL scripts in this blogs will transform the Oracle HR schema into the the following Couchbase JSON data model, using the following strategies:
- Regions, Countries, Locations are direct and indirect parent entities of Departments. So we could denormalize the parent/grandparent/great grand parent into the Department entity. This will reduce the need for JOINs when these information are needed in the query. Furthermore, other associated entities such as Employees and Job_History only have a reference the department_id. For this reason, it would make sense to denormalize the information about the region, country, and location of a department into then ‘department’ object in the Couchbase JSON model.
- The entity Jobs includes the information about pay scale. This could be sensitive data. For this reason, we will use a direct migration of this object without any transformation.
- The Employees entity includes other associated information, such as job_id and department_id, which are important attributes for an employee. It would make sense to denormalize the Job title and Department name into ’employee’ object.
- The Job_History entity is really a child object of the Employees entity. Therefore it would make sense to include the job history of the employee into the ’employee’ object.
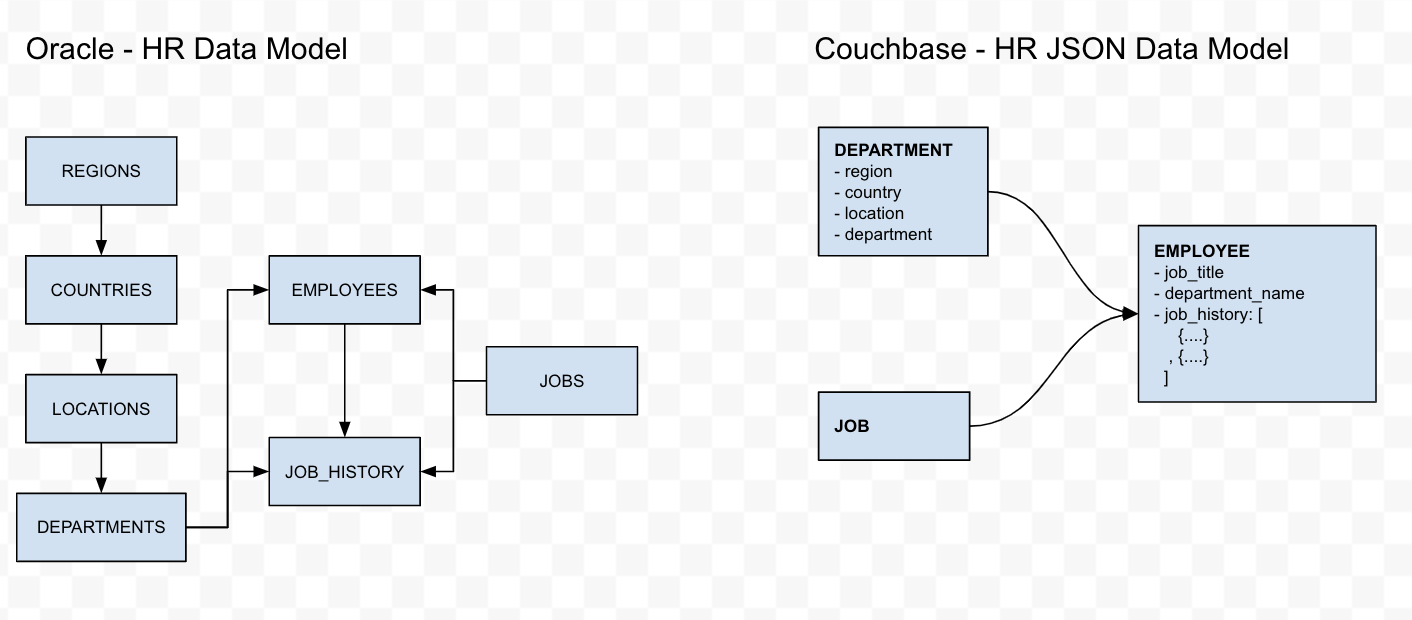
Table vs Document Type
In Couchbase the concept of table does not apply. All documents can be stored in a single bucket with the use of a type field to differentiate document type. This is possible because there is no schema restriction between different documents in Couchbase NoSQL database.
The included script takes care of this by including a doc_type field with the value of the source table name.
|
1 |
SELECT 'employee' doc_type ... FROM hr.employees... |
Primary key mapping
An Oracle table would normally have a primary key, and you can see this in the HR schema. Couchbase documents also need a primary key. However, because all the Oracle table data will reside in a single Couchbase bucket, we need a way to differentiate between the key values of these document types in Couchbase.
The included script takes care of this by constructing the doc_key using the Oracle HR table name and its primary key value.
|
1 |
SELECT 'employee:' ||e.employee_id doc_key FROM hr.employees ... |
Relational to Couchbase JSON document
There is no hard and fast rule as to how you should transform your relational schema to NoSQL. You could migrate all the tables into a Couchbase bucket, each with its own doc_type field.
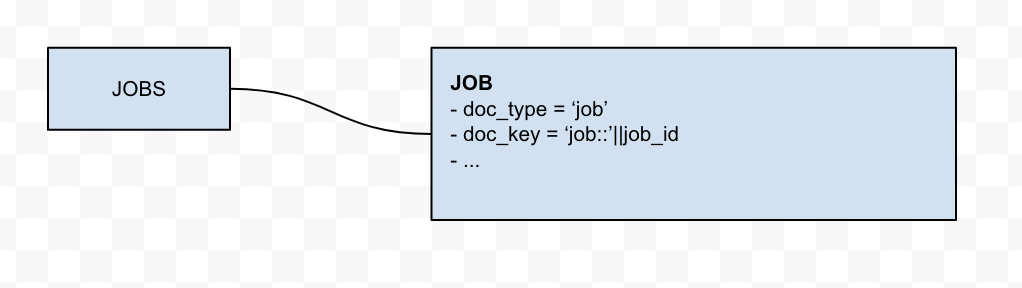
Direct table to document
This is the simplest case, where only the doc_type and doc_key are added the Couchbase document. The relational object does not require any transformation during the migration process.
|
1 2 3 4 5 6 7 8 9 |
UPSERT INTO cbhr (key ndoc.doc_key,value ndoc) SELECT ndoc.doc_key, ndoc FROM CURL("http://<your_server_ip>:8080/ords/hr/_/sql", { "request":"POST","header":"Content-Type: application/sql" , "data":"SELECT 'job' doc_type, 'job:'||j.job_id doc_key, j.* FROM jobs j" , "user":'HR:oracle'} ) r UNNEST r.items[0].resultSet.items as ndoc |
Notes:
- UPSERT is used so that the query can be re-run without affecting the result in the Couchbase bucket.
- The N1QL CURL command calls a REST endpoint in the Oracle Rest Data Services, with a query to be processed by the Oracle server.
- The N1QL CURL returns a JSON document with the query result set in the array field r.items[0].resultSet.items.
- The N1QL query uses the UNNEST command to flatten the r.items[0].resultSet.items array, returning each Oracle record as a separate JSON document.
- N1QL UPSERT inserts each document into the Couchbase cbhr bucket.
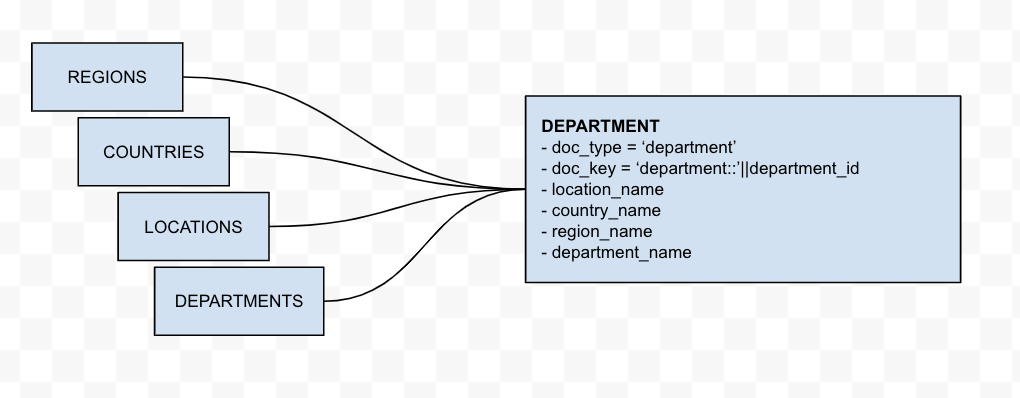
Denormalization
This transformation combines several Oracle tables into a single object. In this example, the tables Regions, Countries, and Locations have a direct parent-child relationship, which allows for the parent fields to be added to the child object. The final result is a single Department object that includes its location, country, and region. This transformation is a single step process.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
UPSERT INTO cbhr (KEY doc_key, VALUE ndoc) SELECT ndoc.doc_key , ndoc FROM CURL( "<your_database_server_ip>:8080/ords/hr/_/sql" , { "request":"POST","header":"Content-Type: application/sql" , "data": "SELECT 'department' doc_type, 'department:' ||d.department_id doc_key, d.department_id, d.department_name, d.manager_id , l.* , c.country_name, r.* FROM departments d INNER JOIN locations l ON d.location_id=l.location_id INNER JOIN countries c ON l.country_id = c.country_id INNER JOIN REGIONS r ON c.region_id = r.region_id" ,"user":'HR:oracle'} ) res UNNEST res.items[0].resultSet.items as ndoc |
Notes:
- UPSERT is used so that the query can be re-run without affecting the result in the Couchbase bucket.
- The N1QL CURL command calls a REST endpoint in the Oracle Rest Data Services, with a query to be processed by the Oracle server.
- The N1QL CURL returns a JSON document with the query result set in the array field r.items[0].resultSet.items.
- The N1QL query uses the UNNEST command to flatten the r.items[0].resultSet.items array, returning each Oracle record as a separate JSON document.
- N1QL UPSERT inserts each document into the Couchbase cbhr bucket.
Denormalization – Adding child records as an array field to the parent object
One of the key features of a NoSQL database is the use of arrays. The Couchbase NoSQL database stores documents in JSON format, in which a field can be an array. For this exercise, we will add the JOB_HISTORY table into the parent EMPLOYEES table. This effectively adds a new job_history array field to the EMPLOYEE document.
This transformation is a two step process. The first step is to migrate the employee data. The second step merges the employee data, which is already in the Couchbase cbhr bucket, with the Oracle query of job_history.
The parent document
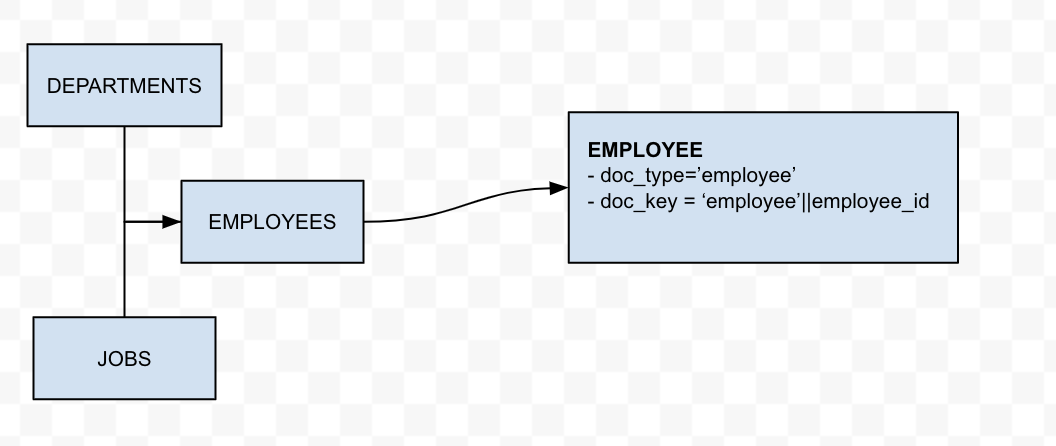
|
1 2 3 4 5 6 7 8 9 10 11 |
UPSERT INTO cbhr (key ndoc.doc_key,value ndoc) SELECT ndoc.doc_key, ndoc FROM CURL("http://192.168.1.117:8080/ords/hr/_/sql", { "request":"POST","header":"Content-Type: application/sql" , "data":"SELECT 'employee' doc_type, 'employee:' ||e.employee_id doc_key, e.* , j.job_title, d.department_name FROM employees e INNER JOIN jobs j ON e.job_id = j.job_id INNER JOIN departments d ON e.department_id = d.department_id" , "user":'HR:oracle' }) r UNNEST r.items[0].resultSet.items as ndoc |
The child records as an array field in the parent document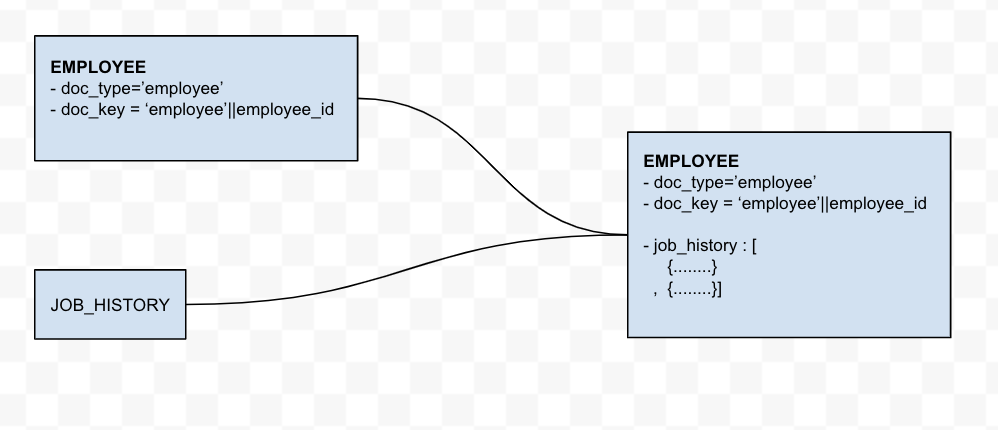
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
MERGE INTO cbhr e USING ( SELECT ndoc.employee_id, ARRAY_AGG(ndoc) all_jobs FROM CURL( "http://<your_database_server>:8080/ords/hr/_/sql" , {"request":"POST","header":"Content-Type: application/sql" , "data": "SELECT h.employee_id, h.start_date,h.end_date, h.job_id, j.job_title, h.department_id FROM job_history h INNER JOIN jobs j ON h.job_id=j.job_id" , "user":'HR:oracle' } ) res UNNEST res.items[0].resultSet.items as ndoc GROUP BY ndoc.employee_id ) source ON KEY 'employee:'||to_string(source.employee_id) WHEN MATCHED THEN UPDATE SET e.job_history = source.all_jobs |
Notes:
- The N1QL query uses the MERGE command to combine documents from the cbhr bucket whose doc_type is employee with the result of the SELECT from the CURL REST read of the Oracle job_history.
- The query uses the N1QL ARRAY_AGG to group all the jobs by employee_id.
- The MERGE uses ’employee:’||to_string(source.employee_id) as the key to match the two result sets.
Limitations
Note that there is a limitation of how much data N1QL CURL() can retrieve. Currently the maximum size is set at 64MB, which cannot be modified. This is not a lot if you plan to migrate large Oracle tables. That said, Oracle does have support for OFFSET and FETCH NEXT, which would allow you to break down the migration process into smaller chunks.
Furthermore the main reasons of this blog is to highlight what you need to consider when migrating relational schema into a Couchbase JSON document database, and how N1QL can help to transform your relational schema directly in the migration process.
Please drop me a comment below if you have questions or feedback.
Hi Binh , This is good and very helpful but knowing the limitations of CURL in sizing I would be interested to know how to handle Big volume of data migration task as batch load from Oracle to Couchbase when 10 different joins exist in OLAP model. Please help sharing your thoughts on that. Trying to replicate the process of using Oracle ORDS but with OFFSET and FETCH not sure how to handle this .
thanks
Debashis,
Thanks for your interest in the blog. To leverage the Oracle “OFFSET and FETCH {FIRST |NEXT} ..” clause, you would want to use a scripting language, i.e. Python and the Couchbase SDK. Here you will iterate through the Oracle record set. Please refer to this forum post https://www.couchbase.com/forums/t/oracle-to-couchbase/22044 for suggestions on how this could be achieved this programmatically.
thanks,
-binh