
As a field engineer, I work with customers and often see them using Couchbase features with a “thinking-out-of-the-box” approach.
One such feature that I see being used more creatively is Global Secondary Index (GSI) partitions. Let’s first discuss GSI and querying then partitioning to get up to speed.
What Is a Global Secondary Index?
According to Couchbase documentation, a Global Secondary Index (GSI) supports queries made by the Query Service on attributes within documents. Extensive filtering is supported.
Global Secondary Indexes provide the following:
-
- Advanced Scaling: GSIs can be assigned independently to selected nodes without existing workloads being affected.
- Predictable Performance: Key-based operations maintain predictable low latency, even in the presence of a large number of indexes. Index-maintenance is non-competitive with key-based operations, even when data-mutation workloads are heavy.
- Low-latency Querying: GSIs independently partition into the Index Service nodes: They do not have to follow hash partitioning of data into vBuckets. Queries using GSIs can achieve low-latency response times even when the cluster scales out since GSIs do not require a wide fan-out to all Data Service nodes.
- Independent Partitioning: The Index Service provides partition independence: Data and its indexes can have different partition keys. Each index can have its own partition key, so each can be partitioned independently to match the specific query. As new requirements arise, the application will also be able to create a new index with a new partition key, without affecting performance of existing queries.
GSI Partitioning
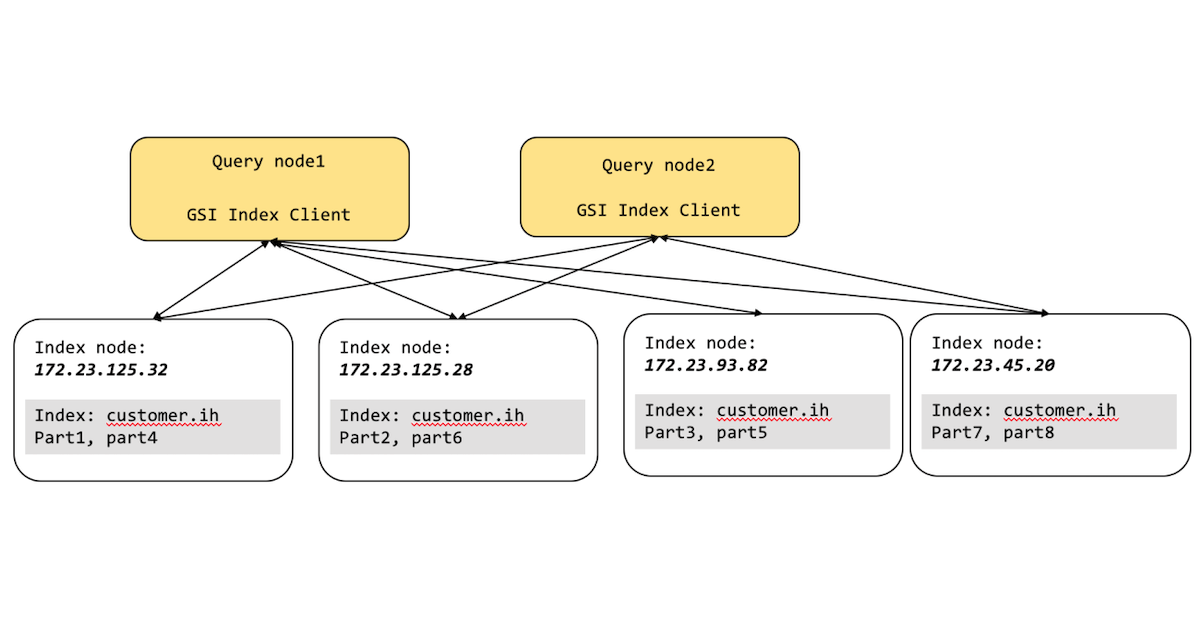
In the diagram above, the query-to-index orchestration is handled by the Query Service and Index Service seamlessly, not only for the application developer, but also for the Couchbase administrator.
Index Partitioning increases query performance by dividing and spreading a large index of documents across multiple nodes. This feature is available only in Couchbase Server Enterprise Edition. Benefits include:
-
- The ability to scale out horizontally as index size increases.
- Transparency to queries, requiring no change to existing queries.
- Reduction of query latency for large, aggregated queries; since partitions can be scanned in parallel.
- Provision of a low-latency range query, while allowing indexes to be scaled out as needed.
For detailed information, refer to Couchbase documentation on Index Partitioning.
Index partitioning provides many features that make index management easier as mentioned above, but why not use Index Partitioning for more than just partitioning?
More on Index Partitioning
In this blog post, we’ll focus on basic use cases, but PARTITION BY HASH is a very powerful feature that can be directed and quantified for index size and performance.
There are many great features of index partitioning to customize your indexes to manage storage, performance or scalability.
The simplest way to create a partitioned index is to use document key as the partition key:
|
1 2 3 4 5 6 7 8 |
CREATE INDEX idx_pe1 ON `travel-sample`(country, airline, id) PARTITION BY HASH(META().id); SELECT airline, id FROM `travel-sample` WHERE country="United States" ORDER BY airline; |
With meta().id as the partition key, the index keys will be evenly distributed among all the partitions. Every query will gather the qualifying index keys from all the partitions.
Choosing Partition Keys for Range Query
An application also has the option to choose the partition key that can minimize latency on range query for partitioned index.
For example, say a query has an equality predicate based on the field sourceairport and destinationairport. If the index is also partitioned by the index keys on sourceairport and destinationairport, then the query will only need to read a single partition for the given pair of sourceairport and destinationairport.
In this case, the application can maintain low query latency, while allowing the partitioned index to scale out as needed.
The partition keys do not have to be the leading index keys in order to select qualifying partitions. As long as the leading index keys are provided along with the partition keys in the predicate, the query can still select the qualifying partitions for the index scan. The following example will scan a single partition with a given pair of sourceairport and destinationairport.
Creating a partitioned index with partition keys matching query equality predicate:
|
1 2 3 4 5 6 7 |
# Lookup all airlines with non-stop flights from SFO to JFK CREATE INDEX idx_pe2 ON `travel-sample` (sourceairport, destinationairport,stops, airline, id) PARTITION BY HASH (sourceairport, destinationairport); SELECT airline, id FROM `travel-sample` WHERE sourceairport="SFO" AND destinationairport="JFK" AND stops == 0 ORDER BY airline; |
Number of Partitions
The number of index partitions is fixed when the index is created.
By default, each index will have eight partitions. The administrator can override the number of partitions at index creation time.
Partition Placement
When a partitioned index is created, the partitions are delineated across available index nodes. During placement of the new index, the indexer will assume each partition has an equal size, and it will place the partitions according to availability of resources on each node.
For example, if an indexer node has more available free memory than the other nodes, it will assign more partitions to this indexer node. If the index has a replica, then the replica partition will not be placed onto the same node.
Alternatively, users can specify the node list to restrict the set of nodes available for placement, by using a command similar to the following example:
Creating a partitioned index on specific ports of a node:
|
1 |
CREATE INDEX idx_pe12 ON `travel-sample`(airline, sourceairport, destinationairport) PARTITION BY KEY(airline) WITH {"nodes":["127.0.0.1:9001", "127.0.0.1:9002"]}; |
Since there are cases where indexes could be larger than the node can store, the original intent of index partitioning was to scale “large” indexes across multiple partitions, i.e., nodes, in a cluster.
But some customers see GSI partitions in a different way.
One case I’m seeing more frequently is using partitioning as workload distribution across nodes. The indexes themselves are not large but spreading all indexed partitions across multiple nodes takes advantage of the architecture of partitioning, where indexes can be scanned in parallel! This will evenly distribute the index scanning across all the partitions/nodes instead of just a single one.
Some customers even collocate services together such as Data, Index and Query and see no degradation of performance versus isolating services like Index/Query to separate nodes. One caveat to this approach is to make sure there’s enough CPU, memory and disk space for all these services to run along with the operating system itself.
Data and Index services are memory-bound and quotas are defined through the cluster settings. The Query service isn’t memory-bound but will use memory. The Couchbase administrator would need to be aware of available memory and the quotas for the Data and Index services as well as reserving enough free memory for the Query service and OS.
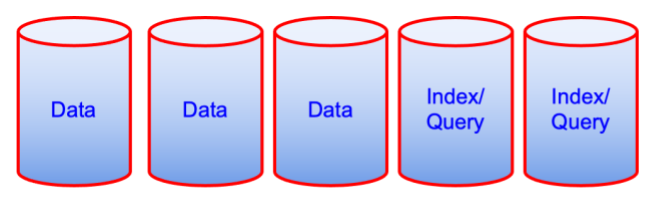
Before
After
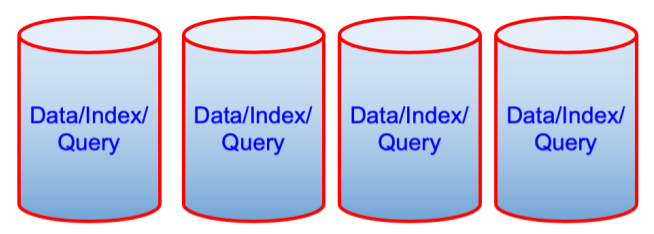
The pair of diagrams above might seem counterintuitive from a performance point of view but from cost-of-ownership, it’s one less machine. Sometimes that is a driving factor.
What are other strategies for partitioning? Typically queries are driven by latency and throughput but also SLAs and the particularities of your use case. For instance, some customers run a query once or twice a day for reporting. Does this need to be high performance? Not really. What’s the best strategy for this type of query?
Let’s say there are 20 queries with different WHERE clauses, maybe a query to find out how many invoices are generated at a given location per day. Is it wise to create 20 different indexes for each location for the invoice query? What if there are other queries that will use the same data as a whole (a.k.a. redundant data)? Perhaps some of the data is country-specific, where 10 of the locations are in the same country.
If this was a query run frequently or a critical part of the application like product displays, then a dedicated index might be appropriate. But in this case, perhaps one large index is more storage- and resource-efficient. Thus, index partitions would be more appropriate.
Command and Query Responsibility Segregation (CQRS)
Another more performant use of partitions are write-heavy workloads where writes dominate operations. One pattern is CQRS (Command and Query Responsibility Segregation).
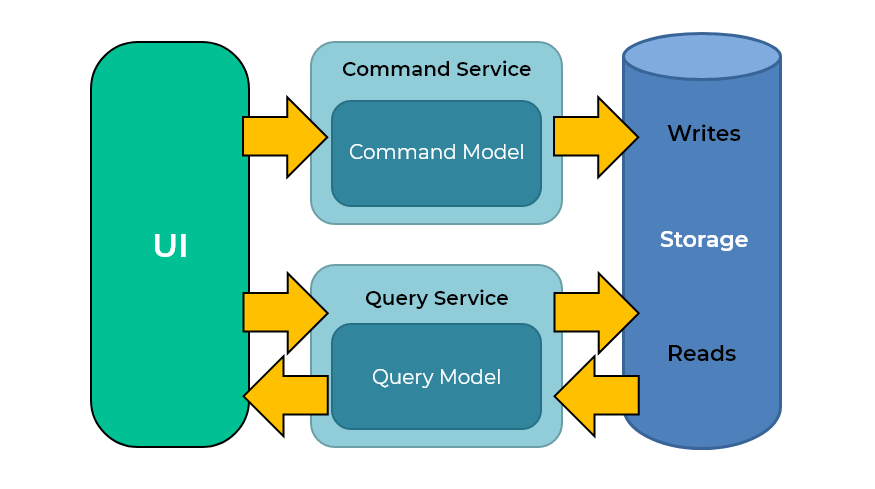
This is where many documents are written to a database and require quick querying. These typically are application events like user interaction with the application, clickthroughs, etc. These events are written in high volume and queried often. With index partitioning, the balancing of writing the document keys to the index are not isolated to one node but distributed across the index nodes. CQRS is a good use case for index partitions.
Conclusion
We have covered just a few uses of Global Secondary Index partitioning. It’s one of the more underrated and underused features of GSI that could be tuned for specific use cases.
Find out more about Global Secondary Indexes (GSIs) in the Couchbase Documentation.