
In the previous blog post, we talked about why full-text search is a better solution at scale to implement a well-designed search in your application. In this second part, we are going to deep-dive on the Inverted Index and explore how analyzers, tokenizers, and filters might shape the result of your searches.
Full-text search is all about searching on the text; therefore, it does not matter if you are indexing and searching logs, genes in a DNA, your own data structure, and of course, language. They will all essentially work nearly the same way.
To give you an example of how to you can use FTS even when you have your own custom structure, let’s leverage the fact that Apple finally bought Shazam and build an imaginary Shazam-like app. However, instead of listening to a small fragment of music like Shazam does, we will ask for the user to whistle it.
Wait… why do I need Full-text Search for it?
As the user might wrongly whistle some parts of the song, we will need to split it in “small blocks of melody” and then try to match them against our library. Assuming that our library will have thousands or even millions of songs (Apple and Spotify libraries have over 30 million songs), a simple LIKE “%melody%” stands no chance of bringing results in a reasonable amount of time.
An inverted index seems to be the right tool for the job as we can easily find all songs that contain a given block of melody. If you are not familiar with this concept yet, please check out my previous blog post about it.
The Parsons Code
The first thing we need to do is convert our songs library to text. We can achieve that by using the Parsons code, which is a notation used to identify a piece of music according to movements of the pitch up and down:
- * = first tone as reference,
- u = “up”, for when the note is higher than the previous note,
- d = “down”, for when the note is lower than the previous note,
- r = “repeat”, for when the note has the same pitch as the previous note.
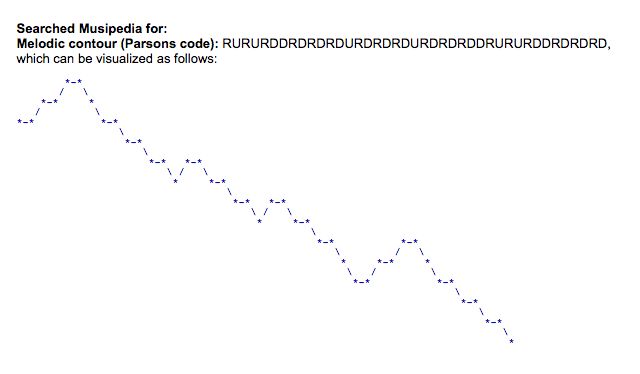
Using parsons code, a song like “Twinkle Twinkle Little Star” will be converted to *rururddrdrdrdurdrdrdurdrdrddrururddrdrdrd.
Here is the whole song:
and here is it’s visualization using Parsons code:
Analyzers
In order to create our inverted index, we need to prepare our text first, like breaking it in smaller parts, converting it to lower case, removing irrelevant words, etc. The preparation/analysis phase usually runs during the index creation and before the query is executed. This way, we can guarantee that both the target text and the term being matched went through the exact same transformations.
The code responsible for this transformation is called Analyzer, and roughly speaking, we group analyzers in two main categories: tokenizers and filters.
Tokenizers
When we are dealing with language, the standard tokenizer will split a text in words. The tokenization strategy will slightly change according to the idiom, as we should also consider characters other than just white spaces, like l’amour in French or “I’m” in English.
In Couchbase FTS, the standard tokenizer works out-of-the-box most of the time, but we also provide tokenizers for HTML and a few other data structures. Therefore, it’s always worth to check that you are using me most appropriate one.
Ideally, in our Shazam-like app, we should create a custom n-gram tokenizer, but to keep things simple, let’s try to leverage the default one. To do that, we will need to slightly change the Parsons code by inserting a white space after every 5 letters. The reason for it is because I’m assuming that if the user can whistle at least 5 notes correctly in a row, I will consider that a “block of melody” and try to match it against our inverted index.
As such, our “Twinkle Twinkle Little Star” will be stored as *rurur ddrdr drdur drdrd urdrd rddru rurdd rdrdr d.
Filters
Couchbase FTS also comes with a variety of filters, the three most popular ones are potentially the to_lower, stop_tokens, and stemmer:
- to_lower: Converts all characters to lower case. For example, HTML becomes html.
- stop_tokens: Removes from the stream tokens considered unnecessary for a Full-Text Search: for example, and, is, and the.
- Stemmer: Uses libstemmerto reduce tokens to word-stems. For example, words like fishing, fished, and fisher are reduced to fish.
Ideally, you should have multiple indexes for the same data, where each index uses a composition of filters focused on highlighting a specific characteristic. We will discuss more about it in the upcoming articles.
For our Shazam-like app, filters might not be necessary, but if we want to improve our results, we could also add some sort of custom stop_tokens or custom character filter.
For instance, in most pop songs, the singer might shout for a few seconds an “Ahhhhhhh” or “Ohhhhhh”. Using Parsons Code, it will be translated to a series of r (“repeat”, for when the note has the same pitch as the previous note). So, our stop_tokens/custom character filter might remove any sequence of ten | twenty “r”.
Ex: *rururddrdrdrdurdrdrdurdrdrddrururddrdrdrdrrrrrrrrrr becomes *rururddrdrdrdurdrdrdurdrdrddrururddrdrdrd
This way, the song will be identified by its core melody instead of trying to find it by a sequence of repeated notes, which would potentially return wrong results.
Querying the data
Now that we have our songs library properly indexed, all we need to do is to record the user’s whistle, convert it to Parsons Code, and finally query the database. FTS will automatically transform our query term using the same tokenizers and analyzers we used to index the data.
For now, let’s just assume that the query will simply bring results ordered by the total matches.
Ex:
A query like rurur ddrdr will potentially bring the “Twinkle Twinkle Little Star” song as we have 4 matches in it:
*rururddrdrdrdurdrdrdurdrdrddrururddrdrdrd
Where is the demo?
We are going to build another type of application during this blog series, but if you are interested in trying a real application that implements something similar to what I have described here, check out Midemi.
Conclusion
The goal of this article was to show the importance of tokenizers and filters even when we are dealing with other types of structures. I highly recommend reading the official documentation about it to understand what is the best use-case for each one of them.
If you already have a good knowledge of FTS, you might have noticed some potential problems with our Shazam-like app: As the user usually won’t start whistling the song since its beginning, we might tokenize the whistle from a different point rather than where we have tokenized the original song. As we are grouping the song in tokens of 5 notes, the chances of tokenizing both the music and the term query in the correct point are 1 in 5.
Ex:
“Twinkle Twinkle Little Star“: rururddrdrdrdurdrdrdurdrdrddrururddrdrdrd
Tokenized “Twinkle Twinkle Little Star“: rurur ddrdr drdur drdrd urdrd rddru rurdd rdrdr d
User’s whistle: rdrdrdurdrdrdurdrd (a random part in the middle of the song)
Tokenized User’s whistle: rdrdr durdr drdur drd
In the example above, we had 2 matches (rdrdr and drdur) by chance, but as they are out of order, the score of this song will be seriously compromised, which can lead to unexpected results.
Full-Text Search Series
- Why you should avoid LIKE % – Part 2
- Fuzzy Matching – Part 3
We will see how to solve this problem and a few others in the next articles of this series. In the meantime if you have any questions, just tweet me at @deniswsrosa