
In Couchbase, latency and throughput are significantly impacted by data replication.
There are different kinds of data replication models, mainly master-slave (Couchbase, MongoDB, Espresso), master-master (BDR for PostgreSQL, GoldenGate for Oracle) and masterless (Dynamo, Cassandra). This article only discusses the master-slave replication in Key-Value (KV) stores.
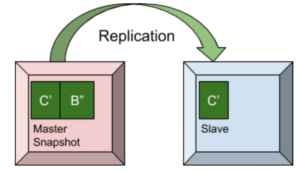
In the master-slave replication model, there is one master for a single data partition and one or more replicas, which are essentially slaves and follow the data in the master partition. The client applications send the key-values to the master and subsequently the key-values are sent over to the replicas from the master.
This article begins with a few concepts like ordering, monotonically increasing sequence numbers, snapshots, MVCC using append only writes and compaction. Then the article explains how master-slave replication can be done with (1) Delta Snapshots or with (2) Point-in-time snapshots, the trade-offs between them and when it is best to use one over the other. Finally, the article briefly discusses how Couchbase, a popular Big Data platform, uses these for data replication.
Partitioning the data, assigning the partitions to the physical nodes, detecting and handling node failures, reconciling diverging branches of data and many more are important to power up a distributed KV store. This article does not discuss any of those, but only discusses master-slave replication of a single data partition — including, specifically, Couchbase and replication.
Background
Naive Replication
One way to replicate data is to get a full copy of the source whenever we want a copy. While this is very simple to implement, it is not of great use in OLTP databases or on KV stores with real time workload where source data keeps getting new updates, as the replica copies cannot get those updates in real time.
Resumability, sending only the changes (delta), is an important feature for any replication protocol that often has to deal with large amounts of data. But that comes at a cost of additional complexity of the need for ordering and snapshots which we discuss in the following sections.
Ordering with Sequence Numbers
Order is important because it allows applications to reason about causality of data or in other words allows applications to know if an operation occurred before or after another operation. In KV stores, order is used to identify the latest value for a given key in the store and also signify the order in which the keys are received by the store. Monotonically increasing sequence numbers are one way to get ‘order’ on the key-values in the store. Every key-value pair in the store has a unique sequence number associated with it and that sequence monotonically increases as the store receives new key-values.
| OPERATION | KEY | VALUE | SEQUENCE NUMBER |
| INSERT | K1 | V1 | SEQ1 |
| INSERT | K2 | V2 | SEQ2 |
| UPDATE | K1 | V1’ | SEQ3 |
| INSERT | K3 | V3 | SEQ4 |
In the above example K2-V2 is received by the store after K1-V1; K1-V1’ is received by the store after K2-V2 and so on. Hence SEQ4 > SEQ3 > SEQ2 > SEQ1. If the store is append only, with the help of SEQ3 > SEQ1 we can identify that the (latest) value of K1 is V1’ and not V1.
The use of monotonically increasing sequence numbers is mainly in point-in-time snapshots which we discuss later.
Snapshots
In the most basic sense, a snapshot (a full snapshot) is an immutable view of the KV store at an instance. This is also a consistent view of the KV store at that instance.
We define a “Delta Snapshot” as an immutable copy of the key-value pairs received by the KV store in a duration of time. We call it delta snapshot because the snapshot does not contain all the key-values in the store and contains only the key-values that are received after an immediately preceding delta snapshot is formed, until the point when the current snapshot is created. Successive delta snapshots give a consistent view of the KV store up to a particular point, that is, till the point when the last snapshot is created.
MVCC using Append Only Writes
Multi version concurrency control (MVCC) is a concurrency control method used in KV stores to enable concurrent readers and writers. Simplest way to handle concurrency would be to use read-write locks. But in distributed KV stores handling huge amount of data, MVCC has proven extremely useful over locking. MVCC helps achieve higher throughputs and lower latencies for reads and writes.
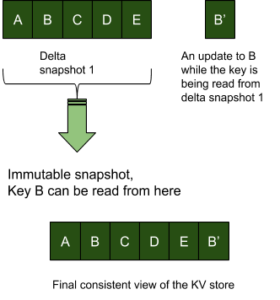
MVCC is achieved using snapshots and append only writes on the KV store. In the example below let’s say ‘key B’ is updated by a writer while there are readers on the delta snapshot 1. Concurrency control with locking would require that the mutating entity wait until the replication of the entire snapshot is complete. However with an append-only MVCC approach, the write to key B can continue to happen even as the current snapshot is being read.
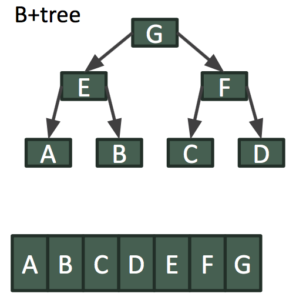
For more advanced readers, MVCC can also be done when the KV store uses more complicated data structures to store data. The example below shows how MVCC can be achieved in an append only B+Tree. Let’s say ‘key B’ is updated by a writer while there are readers on the current delta snapshot.
With an append-only MVCC approach, write to ‘key B’ and the associated branch in the B+Tree can continue to happen even as the current snapshot is being read as shown below.
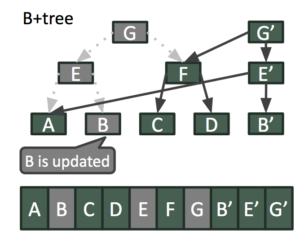
The two overlapping snapshots represented by the B+Tree roots of G and G’ represent consistent views of the KV store at two instances of time.
Compaction
Since snapshots are immutable, the updates to the keys are only appended to the end of the KV store, and hence the memory usage of the store will eventually become much more than the memory needed for the active key-values. Hence the KV store needs to periodically merge the older snapshots and get rid of the duplicate/stale key-values in a background task called compaction. Compaction reduces the memory used by the KV store.
Triggers for compaction can be on a memory threshold or a fixed time interval or combination of both.
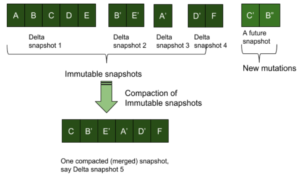
Delta Snapshots
KV stores can be replicated by sending over a sequence of successive delta snapshots. As explained above, in an append-only writes approach, new key-values and updates are only appended to the store. After receiving a batch of items, an immutable snapshot is created and is ready to be sent over to the replica nodes. Key-values received by the store after this snapshot is created are further appended to the store and will be part of the next snapshot. The replication clients then pick up these immutable delta snapshots one after another and get a view of the store that is consistent with the source. Note, this does not need sequence numbers for every KV pair, but will need to identify the order of the delta snapshots.
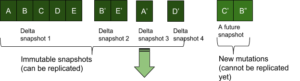
One drawback of this approach is that the source side of the KV store can compact the several immutable delta snapshots into one snapshot. Now if the compaction happens before a replication client has received the last compacted snapshot then the client will have to receive the fully compacted snapshot from the beginning of the snapshot. Say there are 5 immutable delta snapshots snp1, snp2, snp3, snp4 and client has received upto snp3; then compaction runs and the 4 snapshots on the source side are all compacted into one single snapshot snp1’. Now the client cannot resume from snp3, it will have to rollback the snapshots it received before (upto snp3) and will have to receive snp1’ fully.
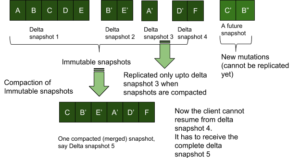
We can do an optimization by having a sequence number (monotonically increasing) on every key-value pair and then just send over network the sequence numbers that are greater than the snap_end of snp3. However, the KV store will still have to read from the beginning of snp1’ to reach the snap_end of snp3.
Another drawback of the approach is that the latest key-value pairs cannot be replicated until they are formed into an immutable delta snapshot. This increases the latency of the keys being sent to the replicas.
Delta snapshots are good replicating fairly large batch of items — that is, high on throughput, but also high on latency.
Point-in-time Snapshots
Point-in-time snapshots are the snapshots that are created on the fly. That is, while new data and updates are being written onto the KV store, the store creates the snapshot if a replication client requests data. This implies that to receive the latest key-values the replicas need not wait for a snapshot to be created on the source.
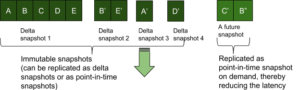
Point-in-time snapshots can be created very quickly (low latency) on an append only KV store and are best suited for in-memory, steady state replication of items. By steady state we mean all replication clients have almost caught with the source.
This model requires that every key-value pair has a monotonically increasing sequence number on it. A point-in-time snapshot is defined by the tuple {start_seqno, end_seqno}.
Say the source has key-value pairs from sequence number 0 to 100 and a replication client R1 makes a request for the copy of data. Key-value pairs from sequence number 0 to 100 are sent as a snapshot (point-in-time snapshot) to R1 and a cursor C1 that corresponds to the client R1 is marked on the store. At a later time, say the store has appended 20 more KV pairs and has the highest sequence number of 120. If another client R2 requests for data, key-value pairs from sequence number 0 to 120 are sent as a snapshot to R2 and a cursor C2 that corresponds to the client R2 is marked on the store. When more data is appended to the store, say until sequence number of 150, the client R1 can get upto 150 in a successive point-in-time snapshot from 101 to 150 and the client R2 in a successive point-in-time snapshot from 121 to 150. Note that cursors C1 and C2 are important to start over quickly from where the clients R1 and R2 had left before. As the cursors move, the key-value pairs with sequence number less than the sequence number where any cursor is marked can be compacted without any read-write contention or removed from memory (in case of in-memory data replication on a persistent KV store).
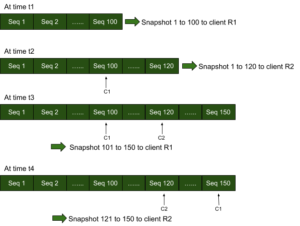
Point-in-time snapshots are good for steady state replication as the replication clients get their own snapshots that are created on demand and hence avoid any wait for a snapshot to be created. Hence clients can catching up with the source very fast with the latest key-value pairs shipped over as soon as possible. Further clients need not start over if a compaction runs in between its successive snapshots and also the source need not keep around delta snapshots for all clients to read it.
Slow clients and lagging (deferred) clients do not work well with point-in-time snapshots. As we cannot compact without read-write contention or eject from memory the key-value pairs with sequence number less than the sequence number of the cursor with the least sequence number, one slow client can slow down point-in-time snapshot creation speed for all other clients and also increase the memory usage.
Point-in-time snapshots are good replicating latest items quickly — that is, low on latency, but also low on throughput.
Using both Delta and Point-in-time Snapshots
Both high throughput and low latency can be achieved by dynamically switching between delta snapshot mode or point-in-time snapshot mode as needed during the replication of a partition.
When a replication client connects to a source, it initially gets delta snapshots at a high throughput so that it catches up with the source soon and hence reaches the steady state. Then the replication switches over to point-in-time snapshot mode and thereby the client keeps getting the latest items at a very low latency. If for some reason a client becomes slow, the replication falls back to incremental delta snapshot mode to reduce any unhealthy memory usage increase. And once the slow client catches up with the source and reaches the steady state again, the replication switches over to point-in-time snapshot mode.
Other Design Considerations
Purging Deletes
In append-only mode, deletes are always appended at the end of the store. In replication using snapshots, appending deletes are essential to reflect a key being deleted across all replicas. However we cannot keep deletes forever as they are an overhead to the storage memory. So eventually deletes have to be purged.
But purging deletes can have effects on slow replication clients and can sometimes break incremental replication especially on clients that have not caught up to the snapshot where a delete has been purged. Such clients might have to rebuild all the snapshots from beginning to get a copy that is consistent with the source.
Branching
Hard failures can lead to different data branches across replicas. These branches can be reconciled and all replicas can have the same consistent copies eventually. There are protocols and algorithms to do this and they very well intersect with the snapshotting world. However we keep those out of scope of this article. This article only discusses replication and snapshotting schemes when there are no hard failures.
Deduplication
Deduplication is removal of duplicate versions of the same key in a snapshot and retention of only the final version of the key in that snapshot. Main purpose of deduplication is to reduce memory usage.
Deduplication is done in delta snapshots during compaction. In point-in-time snapshots, deduplication can be done during compaction and also while items are being appended. Doing deduplication along with point-in-time snapshots creates additional complexity like not being able to write when a point-in-time snapshot is being read and non-resumability when the source of a client changes in cases of failure. As mentioned before, discussion of such failure scenarios is beyond the scope of this article.
Usage in Couchbase
In Couchbase, latency and throughput benefit from replication that dynamically chooses delta snapshots from disk or point-in-time snapshots from memory. The delta snapshots from disk also use monotonically increasing sequence numbers to resume from where the clients had left off to reduce the network traffic.
Couchbase also does deduplication, detection and handling node failures, reconciliation of diverging branches of data, providing with data clients that are more sophisticated than just replication clients (indexing, full text search), caching, partitioning and many more are important to provide a highly available, highly performant and a memory-first data platform.
Conclusion
In master-slave replication, ‘Delta Snapshots’ are good for replicating a batch of items and hence give high throughput. ‘Point-in-time Snapshots’ are good for steady state replication thereby providing low latency. By using one or the other as the situation demands we can get a master-slave replication that is both high on throughput and low on latency.
Author

Sundar Sridharan, Senior Software Engineer