
High Performance Consistency
When using Couchbase as your system of record we provide a best in class indexing experience using our global secondary indexes and workload isolation through dedicated indexing nodes. We’ve improved that experience even further in Couchbase 4.5 with two important new features:
- Exclusive in memory secondary indexes using a new storage engine memdb
- High performance consistency (code named “AT_PLUS”) allowing you, the developer, finer granularity control of the consistency model for writes and reads.
In this blog we’ll go in depth on what high performance consistency entails, and provide some resources to help get you started.
Some Background – How Querying Global Secondary Indexes Work
Global secondary indexes in couchbase have the following characteristics:
- They’re scoped to a single index node, and are not automatically partitioned. At first this might seem like a limitiation. Actually, it’s an intentional design choice we’ve made to keep performance in alignment with what you’ve come to expect from Couchbase.
- They’re user definable using our sql variant (N1QL) and incredibly flexible. We can even index arrays within json documents.
- There are two different storage engines available:
- Forestdb, our default storage engine in couchbase. By default forestdb indexes are updated cyclicly, every 200ms.
- Memdb, (Memory Optimized Indexes) are our blazingly fast in memory only option for secondary indexes. By default memdb indexes are updated cyclicly, every 20ms.
When you issue a N1QL query, using Couchbase 4.5 you now have three options for controlling the consistency of your query:
Default
Default, or “unbounded” are queries where the projection (result set) includes whatever data is in, or refered to, in the current state of the index. This is the fastest query experience. Consistency is not bound to your query in any way. This is great for most use cases. There are use cases where you need a more immediate consistency experience. Let’s say in a user profile, you update the profile with a recent purchase. Now, you need to immediately query that same user for a full list of purchases. If the indexer hasn’t indexed that change you made to the user profile, the query result set won’t include that recent purchase.
Request plus
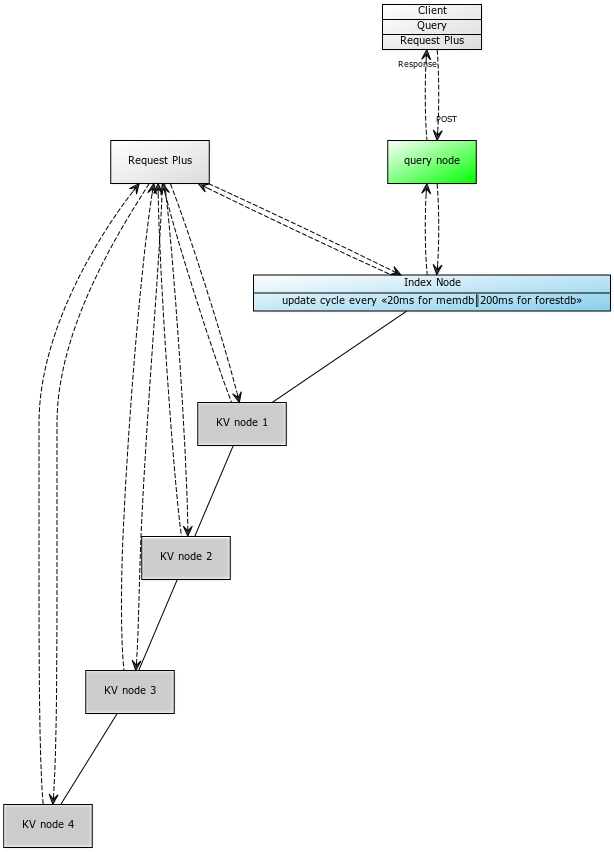
Request plus are queries where the projection includes all updates bounded from the point in time you issued the query. The indexer needs to ensure that the index within your projection is bounded to include all udpates across all partitions in the cluster at the point in time the query “request” was made. This fits our scenario above where a user profile is updated to include a recent purchase, and then immediately query that document to see a consistent list of purchased items. While this type of query is very useful in certain situations, it’s expensive to require the index on the cluster to include all updates at the point the query was issued. This is best explained in the diagram below. Note how the indexer must ensure the index is current with all partions on every node of the cluster:
High Performance Consistency
High Performance Consistency or “AT Plus” are queries where the projection includes updates bound to specific mutation sequence id’s. Each time a mutation operation is performed from one of our SDK’s, a mutation id sequence can be obtained specific to that mutation. When it comes time to query that same data, these mutation sequences can be passed in as a parameter to the query node. While this sounds complicated, it’s really not–we provide really easy to use abstractions in the form of mutation tokens to handle the heavy lifting for you. In order for AT_PLUS to work, mutation tokens must be enabled on the Bucket instance and the actual MutationTokens (found within Documents returned as a result of mutation operations) are passed to the N1QL Query object. In order for the SDK to include a MutationToken in the returned Document after a mutation, the feature must first be negotiated with the server. It is available since Couchbase Server 4.0, and can be activated in the SDK’s CouchbaseEnvironment. In java, this looks like:
|
1 2 3 4 5 |
CouchbaseEnvironment env = DefaultCouchbaseEnvironment.builder() .mutationTokensEnabled(true) //other tuning goes here .build(); Cluster cluster = CouchbaseCluster.create(env, "127.0.0.1"); |
Once this is done, the Document returned from every key/value mutation operation you perform will now also contain a MutationToken. It is important to note that the returned Document object is different than the one passed in as an argument. You must use this return value in order to get the to get AT_PLUS consistency, by passing it to the consistentWith() method of the N1qlParams builder. The params may then be passed to the N1qlQuery builder itself, such as this java example:
|
1 2 3 4 5 6 |
JsonDocument originalDoc = JsonDocument.create("key"); JsonDocument docWithToken = bucket.upsert(originalDoc); //don't use originalDoc (it won't have a token), use docWithToken! N1qlParams atPlus = N1qlParams.build().consistentWith(docWithToken); N1qlQuery query = N1qlQuery.simple("SELECT * FROM default WHERE updatedCriteria = 1", atPlus); |
This is incredibly efficient. You get to specify to the indexer the exact mutations you want your index to be consistent with. Let’s look at the same architecture from the “request plus example”. If the documents we were after were all located on partitions on node 1 using “at plus” the picture looks very different:

Through our internal performance benchmarking using “at plus” can result in a 10x improvement or better for average latency, as well as dramatically reduced cpu/memory usage across the cluster.
Next Steps
A great way to experience this feature, along with several other new features is to try Couchbase 4.5 for yourself. It can be donwloaded free from our downloads page. A comprehensive overview of what’s included in this release can be found in Don Pinto’s “Whats New in Couchbase 4.5” blog.