
While I was at JDays in Göteborg, I attended a presentation about Apache Zeppelin. It’s a web-based notebook that enables interactive data analytics. It already supports many interpreters like Spark, Markdown, Angular, Elastic and more. It really is well integrated with Spark. And Couchbase has a Spark Connector. And because the people behind Zeppelin knew Spark users would want to use their own dependencies, they made it really easy. Easy as in you don’t have to write a plugin. But you do have to have the latest version.
Build Apache Zeppelin
Latest version as in built from latest sources(Ok admitedly it’s not ‘that’ easy…). Fairly simple to build though, clone the repo, ensure you have the right dependencies(git, jdk, npm, libfontconfig, maven) and then inside the repo type mvn clean package -DskipTests -Pbuild-distr. This will build the whole thing, now would be a good time to get a coffee (or maybe play with the new fulltext search in Couchbase 4.5 if you haven’t already).
At the end you should have the distribution built form source under ./zeppelin-distribution/target/zeppelin-0.6.0-incubating-SNAPSHOT/zeppelin-0.6.0-incubating-SNAPSHOT/. Now to run it simply type ./zeppelin-distribution/target/zeppelin-0.6.0-incubating-SNAPSHOT/zeppelin-0.6.0-incubating-SNAPSHOT/bin/zeppelin-daemon.sh start. If you go to http://localhost:8080/ you should see something like this:
Adding the Couchbase Spark Connector dependency
Now the goal is to add the right dependency to the Spark interpreter. An interpreter is the piece of code to transform the content of a pad into something else. So go over the Interpreter tab. Here you should see the list of available interpreters. You should be able to edit the Spark interpreter by simply clicking on edit.
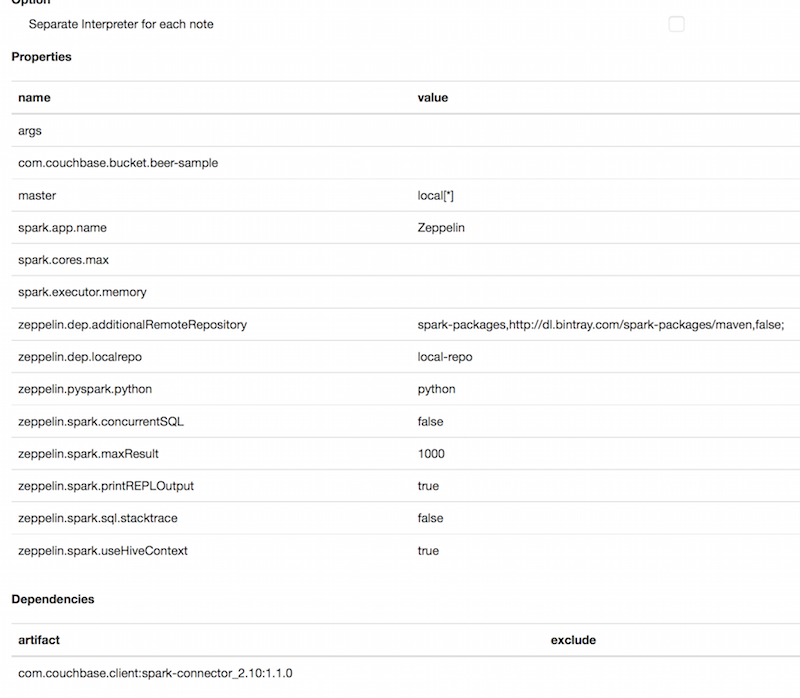
At this point there is two things to do. First mandatory step is to add the dependency to the Couchbase Spark Connector. Second is adding a property to access the beer-sample bucket.
Under Properties, add com.couchbase.bucket.beer-sample as name and something as value. It seems there is a bug right now that forbid you to add a new empty property. You can edit it later.
Under Dependencies, add com.couchbase.client:spark-connector_2.10:1.1.0 under artifact. Don’t forget to click on the + buttons.
Start Writing Spark Pads
We are in a state where we can start reading or writing data from Couchbase. I always import the beer-sample, for some reason. So what we can do is start reading from there. We can easily create a DataFrame for all the beer documents. By default the read.couchbase method will read from the default bucket. So to make sure we read from the beer-sample we create a simple option Map containing the k/v pair bucket/beer-sample. Also, to make sure we only get Beer and not brewery, we can add a filter on the type field. These are the two first lines you need to write in the pad to get a DataFrame containing all the beer documents. Then if you want to use it with Spark SQL, all you have to do is create a tempTable from that DataFrame.
To do this, click on Notebook and Create New Note. Than you should see an empty pad where you can start writing some Scala code. You can also copy/paste the following(but remember copy/pasting is bad).
|
1 2 3 4 5 6 7 |
import org.apache.spark.sql.sources.EqualTo import com.couchbase.spark.sql._ val options = Map("bucket" -> "beer-sample") val dataFrame = sqlc.read.couchbase(schemaFilter = EqualTo("type", "beer"), options) dataFrame.registerTempTable("beer") |
If you run this paragraph, it will add another pad to follow up. By default the interpreter is %spark. If you want to use another interpreter, start the pad with its name. Here I want to run Spark SQL queries. So I’ll start the pad with %sql. Instead of interpreting Scala Spark code as before, it interprets straight Spark SQL queries.
|
1 2 3 4 5 6 7 |
%sql select abv, count(1) value from beer group by abv order by abv |
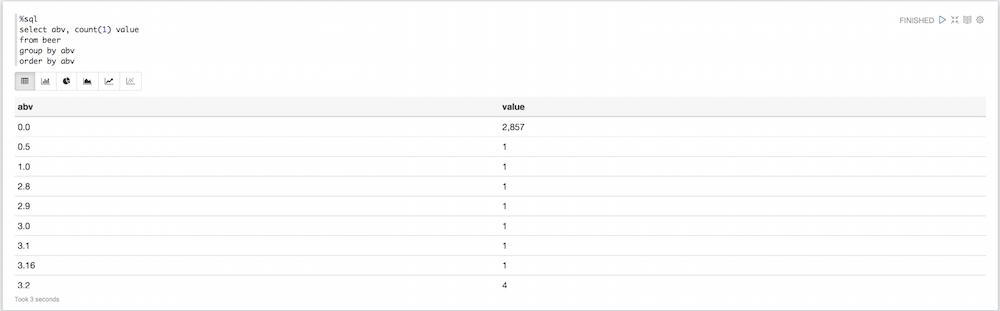
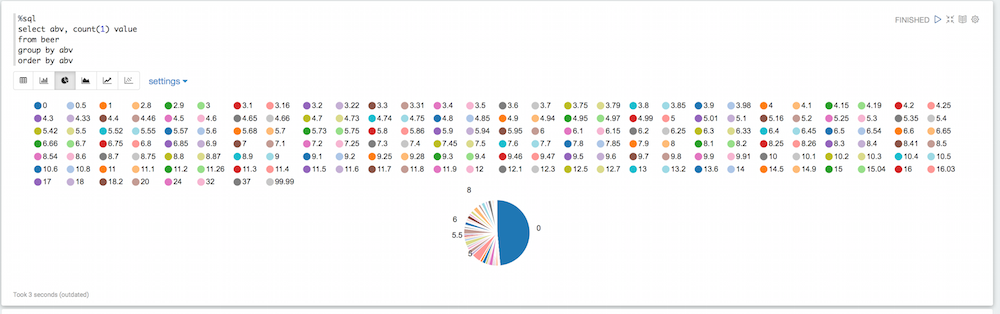
If you look at the piechart, you’ll see there are a lot of values here that are not necessarily useful. Some beer have a default 0 value for abv, some have a ridiculously high abv. We can filter all of that:
|
1 2 3 4 5 6 7 |
%sql select abv, count(1) value from beer where abv > 0 and abv < 15 group by abv order by abv |
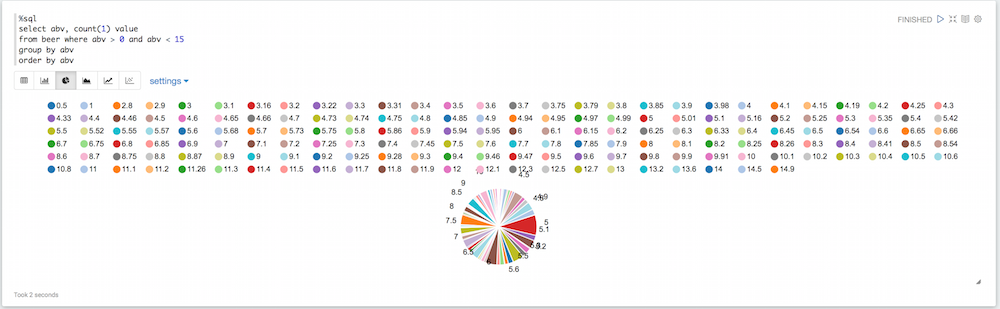
Slightly better but we still have a lot of different abv values so we can round this up like this:
|
1 2 3 4 5 6 7 |
%sql select round(abv,0) roundABV, count(1) value from beer where abv > 0 and abv < 15 group by abv order by abv |
This is starting to be easier to read. Let’s group them by category and remove the empty categories at the same time:
|
1 2 3 4 5 6 7 |
%sql select category, round(abv,0) roundABV, count(1) value from beer where abv > 0 and abv < 15 and category != "" group by abv, category order by abv |
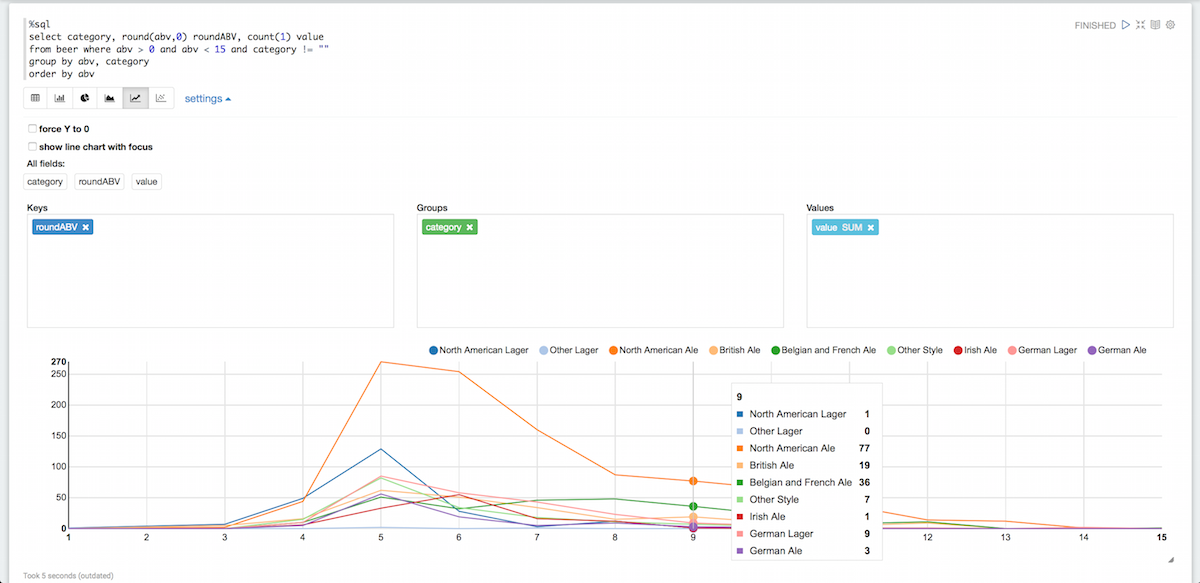
There are of course many other things you can do with Zeppelin but this should be enough to get you started with Couchabse. If you want to know more about Zeppelin, you can check out their documentation here, they also have some good videos.