
The new release of GeoCouch improves the spatial index building time a lot (up to 10x). This comes from using a new bulk insertion algorithm. The spatial index (an R-tree) is implemented as an append-only data structure — just as CouchDB’s B-trees are — which benefits from the nature of bulk insertions by allowing large blocks of the index to be appended at one time.
Old implementation
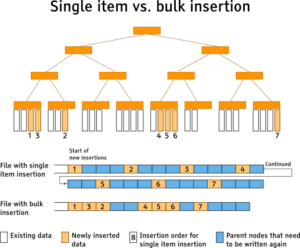
In previous versions of GeoCouch, each geometry entry was inserted one by one. This led to a huge amount of small disk operations as each addition was written to the index. Here’s a rundown of the old algorithm.
- Start at the root node
- Find the first child who’s bounding box needs the least expansion
- Traverse down R-Tree until target leaf is reached
- Insert the new node into a leaf node
- Rewrite all nodes on the path from the newly inserted node up to the root node
The first steps are the basic steps required for an insertion into any R-tree implementation. The issue with this method is that when using an append-only data structure, a high number of writes are required as all nodes from the inserted node up to the root node needs to be rewritten and appended to the index. You can find more information about the nature of append-only data structures in my Creating a new indexer tutorial
Current implementation
The spatial index is implemented in a similar fashion to views, the index is updated when a request is made to use it, rather than when a new document is inserted. The result is that once the index is accessed, the index needs to catch up with the most recently inserted document. As soon as more than one document has changed, it makes more sense to process it in bulk and reduce the on-disk modifications of the index and improve the overall update performance.
Bulk loading and bulk insertion
There is a difference between bulk loading and bulk insertion. Loading means the creation of a new data structure from scratch. While bulk insertion means that several new items are inserted into an already existing structure. GeoCouch’s implementation needs both and is primarily based on two papers. For the insertion Bulk insertion for R-trees by seeded clustering and for the bulk loading OMT: Overlap Minimizing Top-down Bulk Loading Algorithm for R-tree was implemented (with minor modifications).
The algorithm
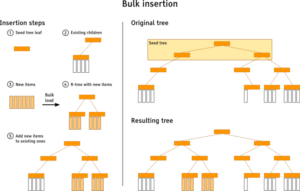
For those who don’t want to read the full description, here is a short summary of the bulk-insert algorithm. The basic idea is to create clusters out of the entire bulk update that match the currently existing index structure (i.e. the target tree). Then those clusters are bulk loaded into R-trees by being inserted verbatim into the target tree.
Let’s take a closer look at each step. The algorithm starts with loading the upper levels of the target tree into memory (at most 3, else the memory consumption is about to explode), this is the so-called seed tree. The leaves are then used to perform the clustering. Each item of the bulk insertion is incorporated into the seed tree with an algorithm similar to the normal R-tree insertion algorithm. The difference is that the new items are not written to disk, but temporarily kept in memory while the remainder of the bulk insertion process continues.
Once every item has been processed, the seed tree traversal starts. Going down in depth first manner some processing is due when a leaf node is reached. All temporarily stored items of the current node get bulk loaded into a new R-tree (the source tree) using the OMT algorithm. This tree gets appended to the original child nodes of the seed tree leaf. But there is a catch. An R-tree is always high balanced, but the height of the source tree might not fit if it is appended as is. There are basically three cases:
- Source tree fits: The tree can be inserted as is
- Source tree is too small: A new seed tree is created. Its root node is the current seed tree’s leaf node. Proceed recursively.
- Source tree is too huge: Use the child nodes instead of the root node of the source tree (recursively, go down until the height matches).
The root node of the source tree might cover most of the area the node it gets inserted to, hence some repacking is done to improve query performance. The children of all nodes that intersect the source tree node and the children of the source tree are reshuffled to minimize the area they cover (the OMT algorithm is utilised). Once this process has been completed, the repacked nodes are finally written to disk.
Parent nodes are written to disk each time a subtree is completed. The result is that the bulk index update process saves a lot of physical disk writes compared to the traditional single item insert strategy, where all parent nodes up to the root a rewritten on every insert.
Challenges of the bulk insertion
Although the basic algorithms are simple, some people might wonder why some of the code required to achieve it is quite so complex. The biggest challenge is keeping the resulting R-tree height balanced and the number of children per node below the maximum number. When you insert in bulk, there might be insertions that result in an overflow (and thus splits) and this needs to be carried out recursively to the top of the tree.
Another challenge is to track in memory the current height of the target tree, the current position within the target/seed tree and the expected height of the source tree that will be inserted. This needs to be done efficiently to prevent consuming too much memory.
Future improvements
The current bulk insertion leads to much better performance and file sizes when compared to the traditional single item insertion, through a combination of efficient rebuilding and balancing of the tree, and the reduced physical writes to disk. The implementation often needs to lookup nodes to get their bounding box, without the need of requesting any other things (like their children). Changes to the current data structure (which are the first code fragments that were written for GeoCouch) could lead to even fewer lookups.
Hi, I\’m wondering if the client API will have setBulk method or the Couchbase Server execute the bulk operation.
Thanks in advance.