
Tuning the search query performance is a very important aspect of Full-Text Search as it helps business-critical applications in meeting the SLA requirements of latency and throughput. Without much preamble, let me share a few useful recommendations for troubleshooting your search performance. All of these suggestions are agnostic of any hardware configurations, cluster topologies, and are applicable to most generic search use cases.
Search As Few Fields As Possible
This is particularly applicable to certain types of composite queries where the user tries to search a common search query text across multiple indexed fields.
Let us delve into a sample query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
"query": { "conjuncts": [ { "field": "UserName", "match": "searchText", "fuzziness": 1 }, { "field": "Department.Name", "match": "searchText", "fuzziness": 1 }, { "field": "SecondName", "match": "searchText", "fuzziness": 1 }, { "field": "ConsumerName", "match": "searchText" "fuzziness": 1 } ]} |
If we notice – there are 4 match query clauses in the conjunct composite query all of which have the same search text. This is highly inefficient, as in the background the search system has to graze a lot of data indexed across different fields for the same search text. This overhead is worsened by the multitude of runtime query structures created and garbage collected across fields.
FTS has a feature to support this in a very efficient way. It lets the users index multiple source document fields against a generic configurable field. Once the user does this during the index definition time, then they could execute searches against that single common field.
To avail of this feature, the user needs to enable the _all option against all those multiple fields in the field mapping during the indexing.
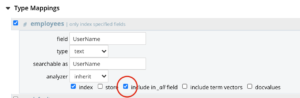
With this, all these field contents will also get indexed against the default _all field in the index. This has an additional storage aspect for the index size.
Now the user should be able to issue queries without explicitly specifying the target field. And whenever target fields are not specified in the query, Full-Text Search will search it against the default common field _all.
So with the above optimization, the earlier query would become a simpler one like below,
|
1 2 3 4 5 6 7 8 |
"query": { "conjuncts": [ { "match": "searchText" “fuzziness” : 1, } ] } |
This search query performance ought to be much lighter and faster compared to the original query.
Note: This is applicable if there is no score boosting used in the original query for the child clauses.
Specify prefix_length For Fuzzy Match Queries
Users choose fuzzy match queries for helping against any potential spelling mistakes within the search texts. With the fuzziness factor, they would still get the intended document hits from the search system. But fuzzy users need to keep in mind that fuzzy queries are extremely resource-consuming queries.
How – In a sufficiently large FTS index, there will be many candidate tokens that are at a given fuzziness/edit distance from the query text. So essentially a single fuzzy query will become a disjunct/OR query for all the candidate tokens present in the index. This results in a high internal fan out of the rudimentary search operations which is resource cumbersome.
Let’s check out a simpler example for the query fan-out here.
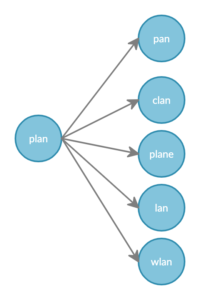
A match fuzzy query with a fuzziness of 1 for the query text “plan” would result in total 6 terms getting searched underneath as in this example. (given that only those 5 terms are present in the indexed content which are at the asked edit distance or fuzziness of 1)
One important optimization idea while guarding against any potential misspellings is that – most spelling mistakes happen towards the end, not towards the beginning of the text. Users can leverage this fact and utilize the prefix_length option in fuzzy queries. Once the prefix_length is given, then the fuzziness will only be considered for the text after the given prefix_length.
Usually, a prefix_length of 2 or 3 ought to be good. But certainly, this is an application or use case-specific one.
Example:
|
1 2 3 4 5 6 7 |
{ "match": "beautiful", => "autiful" is only considered for fuzziness "field": "reviews.content", "analyzer": "standard", "fuzziness": 1, "prefix_length": 2 } |
This drastically reduces the scope/number of the tokens searched in the index for a given fuzzy query. And the search query performance can be significantly improved by specifying a prefix_length for the fuzziness.
Skip Scoring When Text Relevancy Doesn’t Matter
Many times it is observed that users are using Full-Text Search for the exact match queries with a bit of fuzziness or other search specific capabilities like geo. Text relevancy score doesn’t matter when the user is looking for exact or more targeted searches with many predicates.
In similar situations where the user isn’t interested in the default tf-idf scoring, then they could optimize the query performance by skipping the scoring altogether. Users may skip the scoring by passing a “score”: “none” option in the search request.
Example:
|
1 2 3 4 5 6 |
{ "query": {}, "score": "none", "size": 10, "from": 0 } |
This improves the search query performance significantly in many cases, especially for composite queries with many child search clauses.
This feature is available since the Couchbase server release – 6.6.1
Keyset Pagination For Deeper Page Searches
As you might know, the pagination of search results can be done using the from and size parameters in the search request. But as the search gets into deeper pages it becomes highly resource taxing. The primary reason being the search results are by default sorted by their tf-idf scores, and Full-Text Search has heap memory requirements proportional to the requested page’s offset and size. ie from+size for maintaining this ranking.
To safeguard against any arbitrary higher memory requirements, we have a configurable limit bleveMaxResultWindow (10000 default) on the maximum allowable page offsets. But bumping this limit to higher levels isn’t a scalable solution.
To circumvent this problem, we have introduced the concept of key set pagination in FTS.
Instead of providing from as a number of search results to skip, the user will provide the sort value of a previously seen search result (usually, the last result shown on the current page). The idea is that to show the next page of the results, we just want the top N results of that sort after the last result from the previous page.
This solution requires a few preconditions be met:
- The search request must specify a sort order.
- The sort order must impose a total order on the results. Without this, any results which share the same sort value might be left out when handling the page navigation boundaries. A common solution to this is to always include the document ID as the final sort criteria. For example, if you want to sort by [“name”, “-age”], instead of sort by [“name”, “-age”, “_id”].
Example:
User searches for description:light and sorts by [“name”, “_id”]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "query": { "query": "description:light" }, "sort": [ "name", "_id" ], "search_after": [ "Anchor Summer Beer", "anchor_brewing-anchor_summer_beer" ] } |
There is a similar parameter named search_before to navigate to the previous page of results. Instead of providing the sort value from the last result, the application provides the sort value from the first result of the current page. In all other ways, this behaves the same.
With search_after/search_before paginations, the heap memory requirement of deeper page searches is made proportional to the requested page size alone. So it reduces the heap memory requirement of deeper page searches significantly down from the offset+from values.
This feature is available since the Couchbase server release – 6.6.1
Avoid Duplicate Search Clauses In Composite Queries
We know that this indeed sounds like a naive suggestion. But a few times, it is observed that the customer applications while converting the end-user search queries into an FTS backend search request end up having many duplicate child search clauses in their composite queries.
Example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
"disjuncts": [ { "field": "merchantID", "match": "9447611071-0" }, { "field": "merchantID", "match": "9447611071-0" }, { "field": "merchantID", "match": "9447611071-0" }, { "field": "merchantID", "match": "9447611071-0" } ] |
This would result in a lot of redundant work in the Full-Text Search server backend due to the duplicated query contents.
Users need to be aware that the Search service won’t perform any deduplication of the given queries. It respects and executes the complete query request in the backend. Hence the users need to exercise due diligence in ensuring that optimum queries are formed before hitting the Search service.
Please watch out this space for more search query performance tuning and index management tips for Full-Text Search service.
Another interesting read about text analysis for FTS newbies here