
Aaron Benton is an experienced architect who specializes in creative solutions to develop innovative mobile applications. He has over 10 years experience in full stack development, including ColdFusion, SQL, NoSQL, JavaScript, HTML, and CSS. Aaron is currently an Applications Architect for Shop.com in Greensboro, North Carolina and is a Couchbase Community Champion.

FakeIt Series 4 of 5: Working with Existing Data
So far in our FakeIt series we’ve seen how we can Generate Fake Data, Share Data and Dependencies, and use Definitions for smaller models. Today we are going to look at the last major feature of FakeIt, which is working with existing data through inputs.
Rarely as developers do we get the advantage of working on greenfield applications, our domains are more often than not a comprised of different legacy databases and applications. As we are modeling and building new applications, we need to reference and use this existing data. FakeIt allows you to provide existing data to your models through JSON, CSV or CSON files. This data is exposed as an inputs variable in each of a models *run and *build functions.
Users Model
We will start with our users.yaml model that we updated to in our most recent post to use Address and Phone definitions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 |
name: Users type: object key: _id data: min: 1000 max: 2000 properties: _id: type: string description: The document id built by the prefix "user_" and the users id data: post_build: "`user_${this.user_id}`" doc_type: type: string description: The document type data: value: "user" user_id: type: integer description: An auto-incrementing number data: build: document_index first_name: type: string description: The users first name data: build: faker.name.firstName() last_name: type: string description: The users last name data: build: faker.name.lastName() username: type: string description: The username data: build: faker.internet.userName() password: type: string description: The users password data: build: faker.internet.password() email_address: type: string description: The users email address data: build: faker.internet.email() created_on: type: integer description: An epoch time of when the user was created data: build: new Date(faker.date.past()).getTime() addresses: type: object description: An object containing the home and work addresses for the user properties: home: description: The users home address schema: $ref: '#/definitions/Address' work: description: The users work address schema: $ref: '#/definitions/Address' main_phone: description: The users main phone number schema: $ref: '#/definitions/Phone' data: post_build: | delete this.main_phone.type return this.main_phone additional_phones: type: array description: The users additional phone numbers items: $ref: '#/definitions/Phone' data: min: 1 max: 4 definitions: Phone: type: object properties: type: type: string description: The phone type data: build: faker.random.arrayElement([ 'Home', 'Work', 'Mobile', 'Other' ]) phone_number: type: string description: The phone number data: build: faker.phone.phoneNumber().replace(/[^0-9]+/g, '') extension: type: string description: The phone extension data: build: chance.bool({ likelihood: 30 }) ? chance.integer({ min: 1000, max: 9999 }) : null Address: type: object properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() |
Currently, our Address definition is generating a random country. What if our ecommerce site only supports a small subset of the 195 countries? Let’s say we support six countries to start with: US, CA, MX, UK, ES, DE. We could update the definitions country property to grab a random array element:
(For brevity the other properties have been left off of the model definition)
|
1 2 3 4 5 6 |
... country: type: string description: The country code data: build: faker.random.arrayElement(['US', 'CA', 'MX', 'UK', 'ES', 'DE']); |
While this would work, what if we have other models that rely on this same country info, we would have to duplicate this logic. We can achieve this same thing by creating a countries.json file, and adding an inputs property to the data property that can be an absolute or relative path to our input. When are model is generated, our countries.json file will be exposed to each of the models build functions via the inputs argument as inputs.countries
(For brevity the other properties have been left off of the model definition)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name: Users type: object key: _id data: min: 1000 max: 2000 inputs: ./countries.json properties: ... definitions: ... country: type: string description: The country code data: build: faker.random.arrayElement(inputs.countries); countries.json [ "US", "CA", "MX", "UK", "ES", "DE" ] |
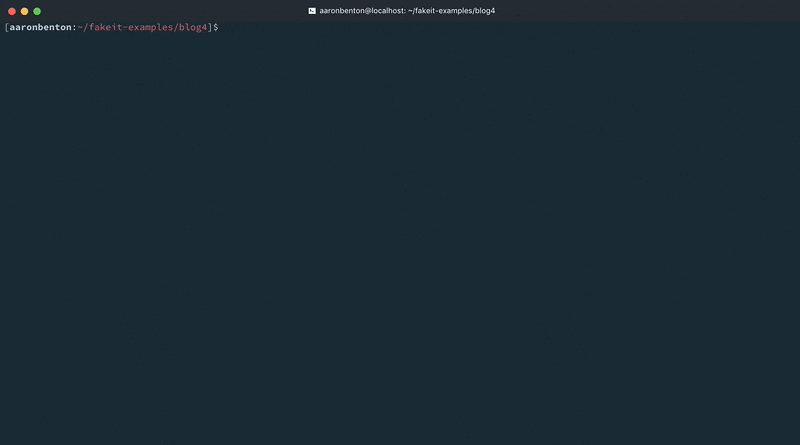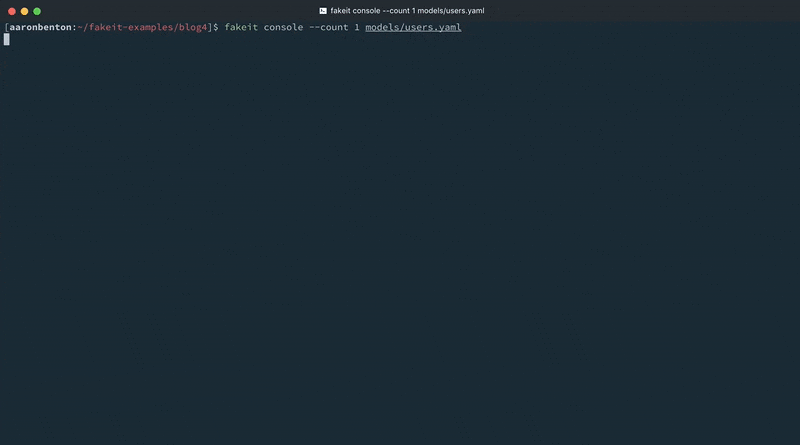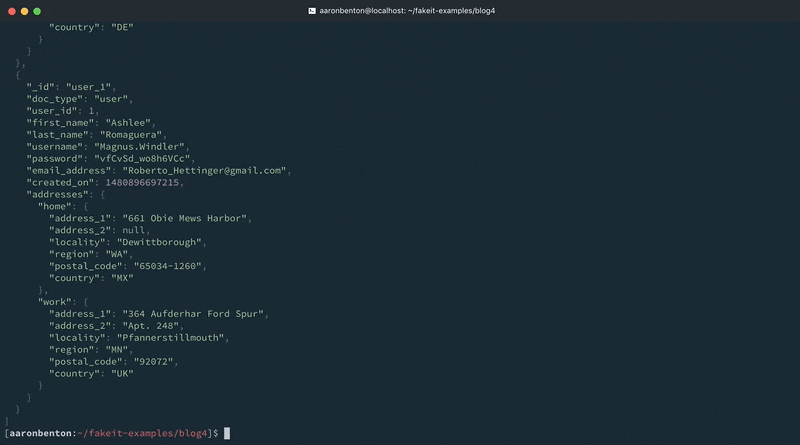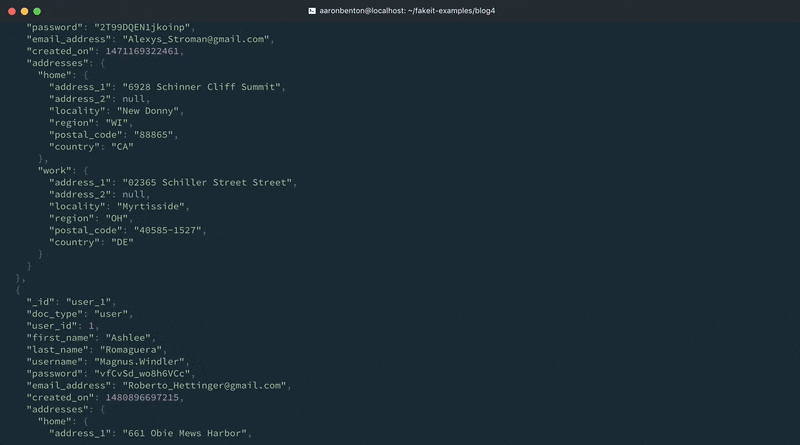
By changing one existing line and adding another line in model we have provided existing data to our Users model. We can still generate a random country, based on the countries our application supports. Lets test our changes by using the following command:
|
1 |
fakeit console --count 1 models/users.yaml |
Products Model
Our ecommerce application is using a separate system for categorization, we need to expose that data to our randomly generated products so that we are using valid category information. We will start with the products.yaml that we defined in the FakeIt Series 2 of 5: Shared Data and Dependencies post.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
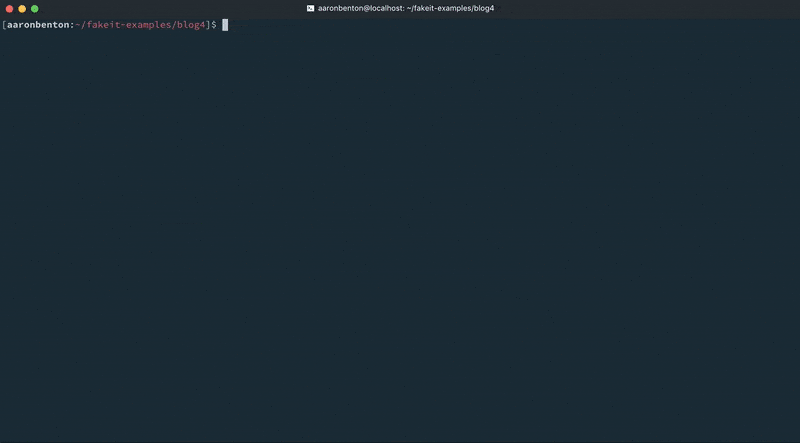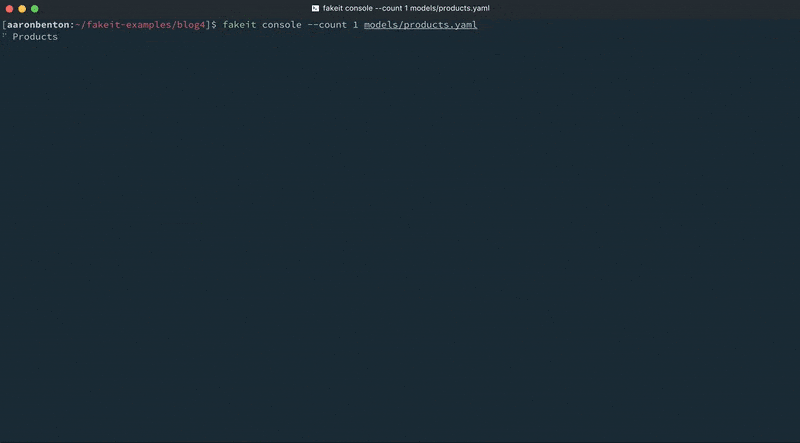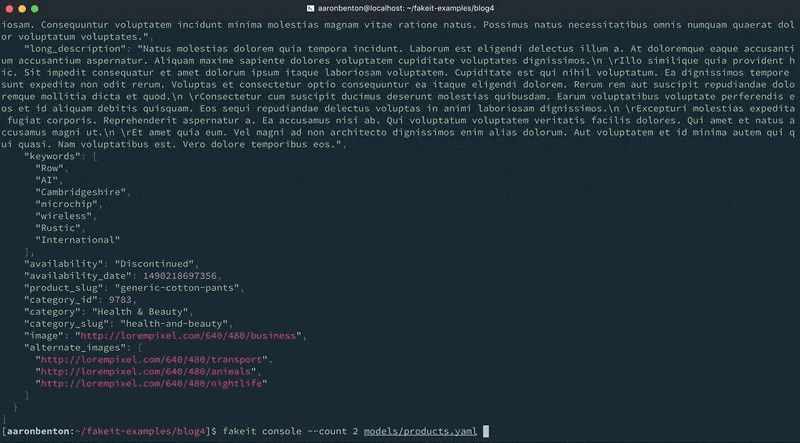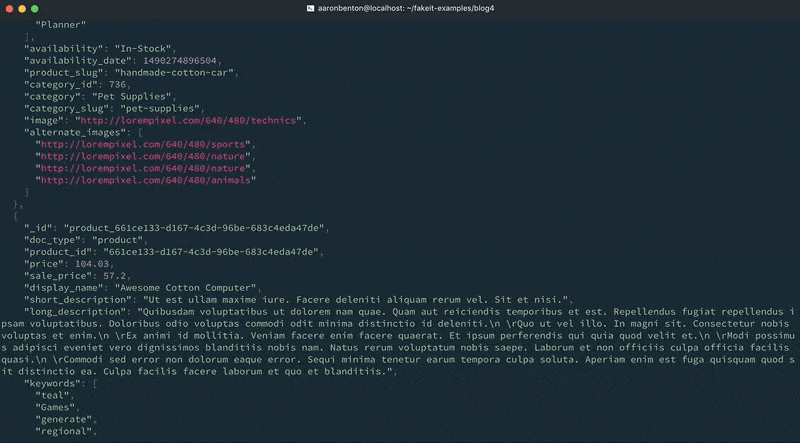
products.yaml name: Products type: object key: _id data: min: 4000 max: 5000 properties: _id: type: string description: The document id data: post_build: `product_${this.product_id}` doc_type: type: string description: The document type data: value: product product_id: type: string description: Unique identifier representing a specific product data: build: faker.random.uuid() price: type: double description: The product price data: build: chance.floating({ min: 0, max: 150, fixed: 2 }) sale_price: type: double description: The product price data: post_build: | let sale_price = 0; if (chance.bool({ likelihood: 30 })) { sale_price = chance.floating({ min: 0, max: this.price * chance.floating({ min: 0, max: 0.99, fixed: 2 }), fixed: 2 }); } return sale_price; display_name: type: string description: Display name of product. data: build: faker.commerce.productName() short_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(1) long_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(5) keywords: type: array description: An array of keywords items: type: string data: min: 0 max: 10 build: faker.random.word() availability: type: string description: The availability status of the product data: build: | let availability = 'In-Stock'; if (chance.bool({ likelihood: 40 })) { availability = faker.random.arrayElement([ 'Preorder', 'Out of Stock', 'Discontinued' ]); } return availability; availability_date: type: integer description: An epoch time of when the product is available data: build: faker.date.recent() post_build: new Date(this.availability_date).getTime() product_slug: type: string description: The URL friendly version of the product name data: post_build: faker.helpers.slugify(this.display_name).toLowerCase() category: type: string description: Category for the Product data: build: faker.commerce.department() category_slug: type: string description: The URL friendly version of the category name data: post_build: faker.helpers.slugify(this.category).toLowerCase() image: type: string description: Image URL representing the product. data: build: faker.image.image() alternate_images: type: array description: An array of alternate images for the product items: type: string data: min: 0 max: 4 build: faker.image.image() |
Our existing categories data has been provided in CSV format.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
categories.csv "category_id","category_name","category_slug" 23,"Electronics","electronics" 1032,"Office Supplies","office-supplies" 983,"Clothing & Apparel","clothing-and-apparel" 483,"Movies, Music & Books","movies-music-and-books" 3023,"Sports & Fitness","sports-and-fitness" 4935,"Automotive","automotive" 923,"Tools","tools" 5782,"Home Furniture","home-furniture" 9783,"Health & Beauty","health-and-beauty" 2537,"Toys","toys" 10,"Video Games","video-games" 736,"Pet Supplies","pet-supplies" |
Now we need to update our products.yaml model to use this existing data.
(For brevity the other properties have been left off of the model definition)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name: Products type: object key: _id data: min: 4000 max: 5000 inputs: - ./categories.csv pre_build: globals.current_category = faker.random.arrayElement(inputs.categories); properties: ... category_id: type: integer description: The Category ID for the Product data: build: globals.current_category.category_id category: type: string description: Category for the Product data: build: globals.current_category.category_name category_slug: type: string description: The URL friendly version of the category name data: post_build: globals.current_category.category_slug ... |
There are a few things to notice about how we’ve updated our products.yaml model.
- inputs: is defined as an array not a string. While we are only using a single input, you can provide as many input files to your model as necessary.
- A pre_build function is defined at the root of the model. This is because we cannot grab a random array element for each of our three category properties as the values would not match. Each time an individual document is generated for our model, this pre_build function will run first.
- Each of our category properties build functions reference the global variable set by the pre_build function on our model.
We can test our changes by using the following command:
|
1 |
fakeit console --count 1 models/products.yaml |
Conclusion
Being able to work with existing data is an extremely powerful feature of FakeIt. It can be used to maintain the integrity of randomly generated documents to work with existing system, and can even be used to transform existing data and import it into Couchbase Server.
Up Next
Previous
- FakeIt Series 1 of 5: Generating Fake Data
- FakeIt Series 2 of 5: Shared Data and Dependencies
- FakeIt Series 3 of 5: Lean Models through Definitions

This post is part of the Couchbase Community Writing Program