
Aaron Benton is an experienced architect who specializes in creative solutions to develop innovative mobile applications. He has over 10 years experience in full stack development, including ColdFusion, SQL, NoSQL, JavaScript, HTML, and CSS. Aaron is currently an Applications Architect for Shop.com in Greensboro, North Carolina and is a Couchbase Community Champion.

FakeIt Series 2 of 5: Shared Data and Dependencies
In FakeIt Series 1 of 5: Generating Fake Data we learned that FakeIt can generate a large amount of random data based off a single YAML file and output the results to various formats and destination, including Couchbase Server. Today we are going to explore what makes FakeIt truly unique and powerful in the world of data generation.
There are tons of random data generators available, a simple Google Search will give you more than enough to choose from. However, almost all of these have the same frustrating flaw, which is they can only ever deal with a single model. Rarely as developers do we have the luxury of dealing with a single model, more often than not we are developing against multiple models for our projects. This is where FakeIt stands out, it allows for multiple models and those models to have dependencies.
Let’s take a look at the possible models we’ll have within our e-commerce application:
- Users
- Products
- Cart
- Orders
- Reviews
Users, the first model that we defined does not have any dependencies and the same can be said for the Products model, which we will define next. However, it would be logical to say that our Orders model would depend on both the Users and Products model. If we truly want test data, the documents created by our Orders model should be the actual random data generated from both the Users and Products models.
Products Model
Before we look at how model dependencies work in FakeIt let’s define what our Products model is going to look like.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
name: Products type: object key: _id properties: _id: type: string description: The document id data: post_build: `product_${this.product_id}` doc_type: type: string description: The document type data: value: product product_id: type: string description: Unique identifier representing a specific product data: build: faker.random.uuid() price: type: double description: The product price data: build: chance.floating({ min: 0, max: 150, fixed: 2 }) sale_price: type: double description: The product price data: post_build: | let sale_price = 0; if (chance.bool({ likelihood: 30 })) { sale_price = chance.floating({ min: 0, max: this.price * chance.floating({ min: 0, max: 0.99, fixed: 2 }), fixed: 2 }); } return sale_price; display_name: type: string description: Display name of product. data: build: faker.commerce.productName() short_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(1) long_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(5) keywords: type: array description: An array of keywords items: type: string data: min: 0 max: 10 build: faker.random.word() availability: type: string description: The availability status of the product data: build: | let availability = 'In-Stock'; if (chance.bool({ likelihood: 40 })) { availability = faker.random.arrayElement([ 'Preorder', 'Out of Stock', 'Discontinued' ]); } return availability; availability_date: type: integer description: An epoch time of when the product is available data: build: faker.date.recent() post_build: new Date(this.availability_date).getTime() product_slug: type: string description: The URL friendly version of the product name data: post_build: faker.helpers.slugify(this.display_name).toLowerCase() category: type: string description: Category for the Product data: build: faker.commerce.department() category_slug: type: string description: The URL friendly version of the category name data: post_build: faker.helpers.slugify(this.category).toLowerCase() image: type: string description: Image URL representing the product. data: build: faker.image.image() alternate_images: type: array description: An array of alternate images for the product items: type: string data: min: 0 max: 4 build: faker.image.image() |
This model is a little more complex than our previous Users model. Let’s examine a few of this property in more detail:
- _id: This value is being set after every property in the document has been build and is available to the post build function. The this context is that of the current document being generated
- sale_price: This using defining a 30% chance of a sale price and if there is a sale price ensuring that the value is less than that of the price property
- keywords: Is an array. This defined similarly to Swagger, we define our array items and how we want them constructed using the build / post_build functions. Additionally, we can define min and max values and FakeIt will generate a random number of array elements between these values. There is also a fixed property that can be used to generate a set number of array elements.
Now that we’ve constructed our Products model let’s generate some random data and output it to the console to see what it looks like using the command:
|
1 |
fakeit console models/products.yaml |
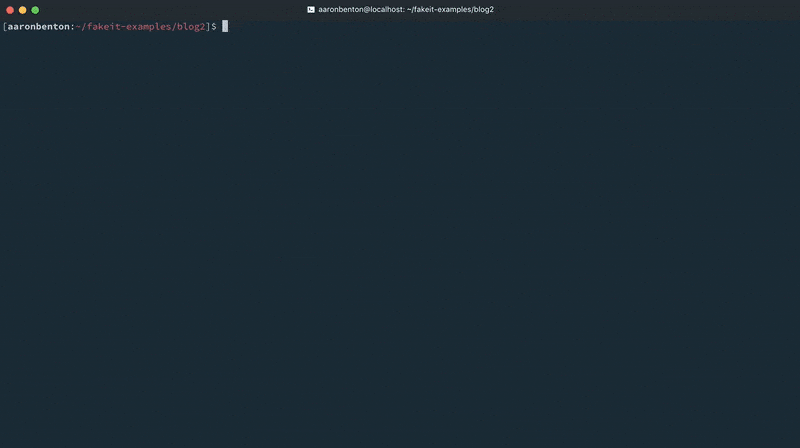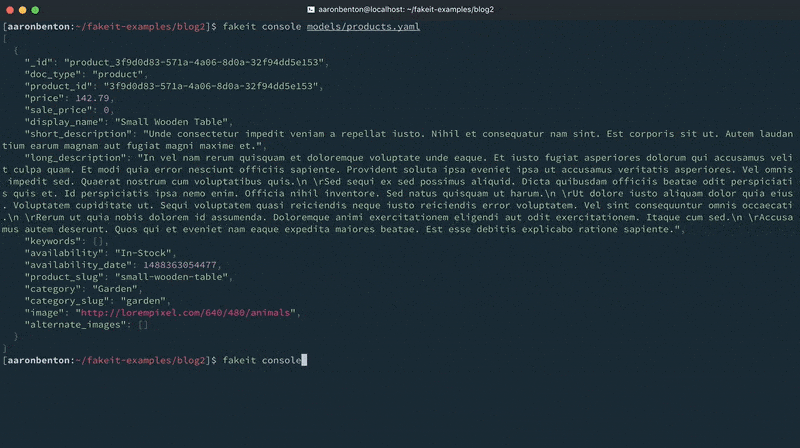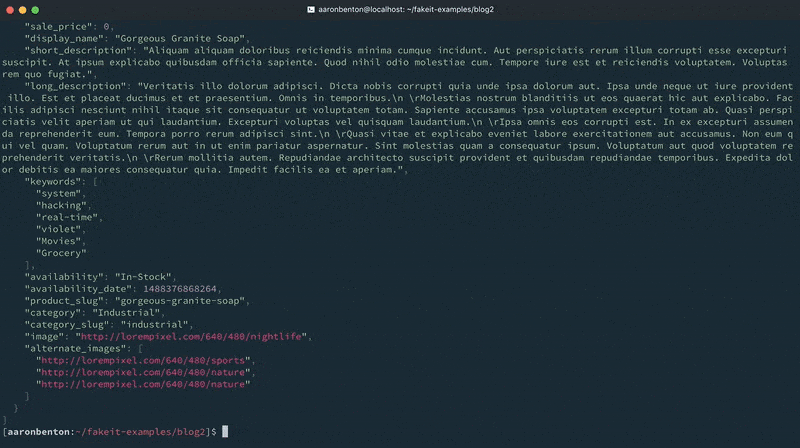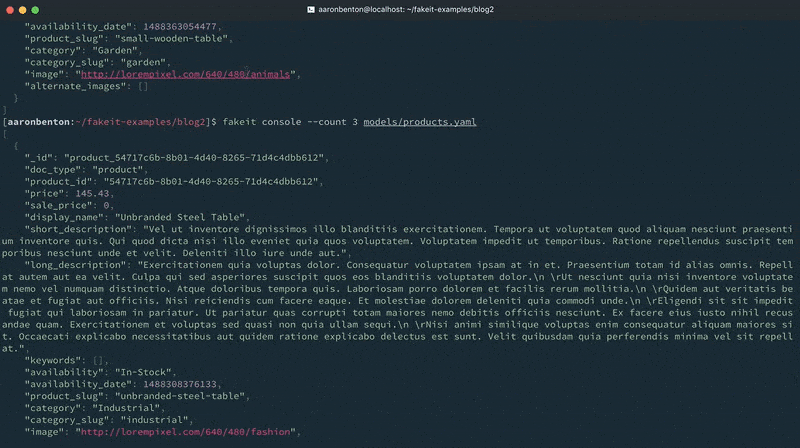
Orders Model
For our project we have already defined the following models:
- users.yaml
- products.yaml
Let’s start by defining or Orders model without any properties and specifying its dependencies:
|
1 2 3 4 5 6 7 8 |
name: Orders type: object key: _id data: dependencies: - products.yaml - users.yaml properties: |
We have defined two dependencies for our Orders model, and referenced them by their file name. Since all of our models are stored in the same directory there is no reason to specify the full path. At runtime, FakeIt will first parse all of the models before attempting to generate documents, and it will determine a run order based on each of the models dependencies (if any).
Each of the build functions in a FakeIt model is a function body, with the following arguments passed to it.
|
1 2 3 |
function (documents, globals, inputs, faker, chance, document_index, require) { return faker.internet.userName(); } |
Once the run order has been established, each of the dependencies are saved in-memory and made available to the dependant model through the documents argument. This argument is an object containing a key for each model whose value is an array of each document that has been generated. For our example of the documents property it will look similar to this:
|
1 2 3 4 5 6 7 8 |
{ "Users": [ ... ], "Products": [ ... ] } |
We can take advantage of this to retrieve random Product and User documents assigning their properties to properties within our Orders model. For example, we can retrieve a random user_id from the documents generated by the Users model and assign that to the user_id of the Orders model through a build function
|
1 2 3 4 5 |
user_id: type: integer description: The user_id that placed the order data: build: faker.random.arrayElement(documents.Users).user_id; |
Let’s define what the rest of our Orders model will look like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 |
name: Orders type: object key: _id data: dependencies: - products.yaml - users.yaml properties: _id: type: string description: The document id data: post_build: `order_${this.order_id}` doc_type: type: string description: The document type data: value: "order" order_id: type: integer description: The order_id data: build: document_index + 1 user_id: type: integer description: The user_id that placed the order data: build: faker.random.arrayElement(documents.Users).user_id; order_date: type: integer description: An epoch time of when the order was placed data: build: new Date(faker.date.past()).getTime() order_status: type: string description: The status of the order data: build: faker.random.arrayElement([ 'Pending', 'Processing', 'Cancelled', 'Shipped' ]) billing_name: type: string description: The name of the person the order is to be billed to data: build: `${faker.name.firstName()} ${faker.name.lastName()}` billing_phone: type: string description: The billing phone data: build: faker.phone.phoneNumber().replace(/x[0-9]+$/, '') billing_email: type: string description: The billing email data: build: faker.internet.email() billing_address_1: type: string description: The billing address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` billing_address_2: type: string description: The billing address 2 data: build: chance.bool({ likelihood: 50 }) ? faker.address.secondaryAddress() : null billing_locality: type: string description: The billing city data: build: faker.address.city() billing_region: type: string description: The billing region, city, province data: build: faker.address.stateAbbr() billing_postal_code: type: string description: The billing zip code / postal code data: build: faker.address.zipCode() billing_country: type: string description: The billing region, city, province data: value: US shipping_name: type: string description: The name of the person the order is to be billed to data: build: `${faker.name.firstName()} ${faker.name.lastName()}` shipping_address_1: type: string description: The shipping address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` shipping_address_2: type: string description: The shipping address 2 data: build: chance.bool({ likelihood: 50 }) ? faker.address.secondaryAddress() : null shipping_locality: type: string description: The shipping city data: build: faker.address.city() shipping_region: type: string description: The shipping region, city, province data: build: faker.address.stateAbbr() shipping_postal_code: type: string description: The shipping zip code / postal code data: build: faker.address.zipCode() shipping_country: type: string description: The shipping region, city, province data: value: US shipping_method: type: string description: The shipping method data: build: faker.random.arrayElement([ 'USPS', 'UPS Standard', 'UPS Ground', 'UPS 2nd Day Air', 'UPS Next Day Air', 'FedEx Ground', 'FedEx 2Day Air', 'FedEx Standard Overnight' ]); shipping_total: type: double description: The shipping total data: build: chance.dollar({ min: 10, max: 50 }).slice(1) tax: type: double description: The tax total data: build: chance.dollar({ min: 2, max: 10 }).slice(1) line_items: type: array description: The products that were ordered items: type: string data: min: 1 max: 5 build: | const random = faker.random.arrayElement(documents.Products); const product = { product_id: random.product_id, display_name: random.display_name, short_description: random.short_description, image: random.image, price: random.sale_price || random.price, qty: faker.random.number({ min: 1, max: 5 }), }; product.sub_total = product.qty * product.price; return product; grand_total: type: double description: The grand total of the order data: post_build: | let total = this.tax + this.shipping_total; for (let i = 0; i < this.line_items.length; i++) { total += this.line_items[i].sub_total; } return chance.dollar({ min: total, max: total }).slice(1); |
And output it to the console using the command:
|
1 |
fakeit console models/orders.yaml |
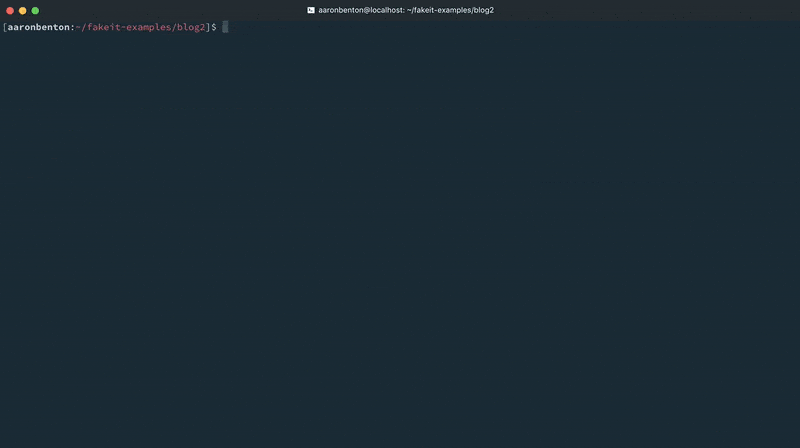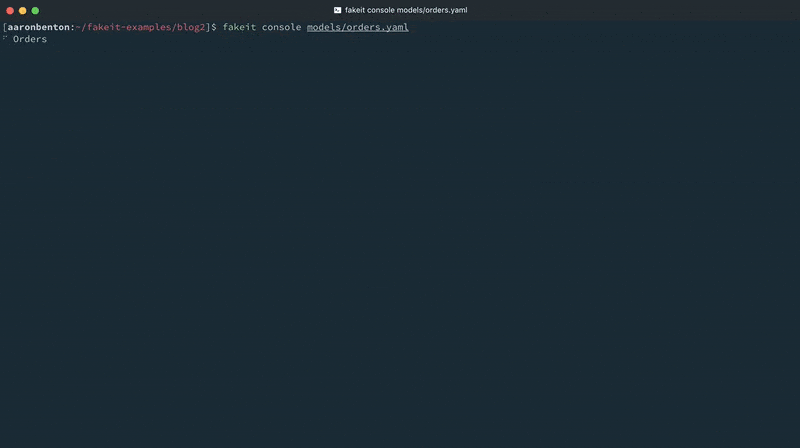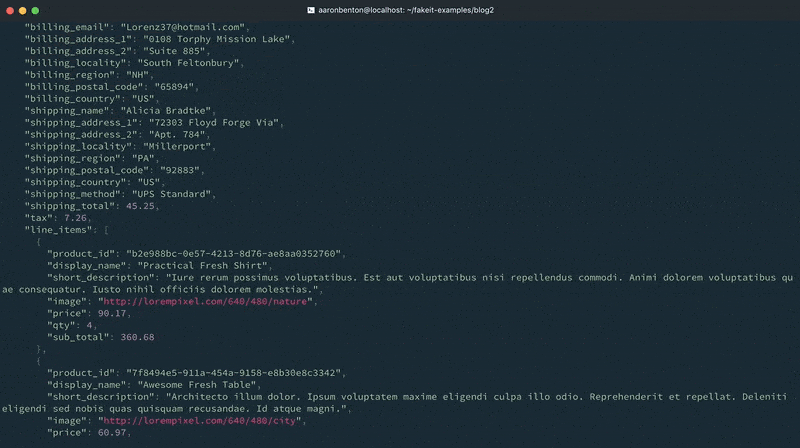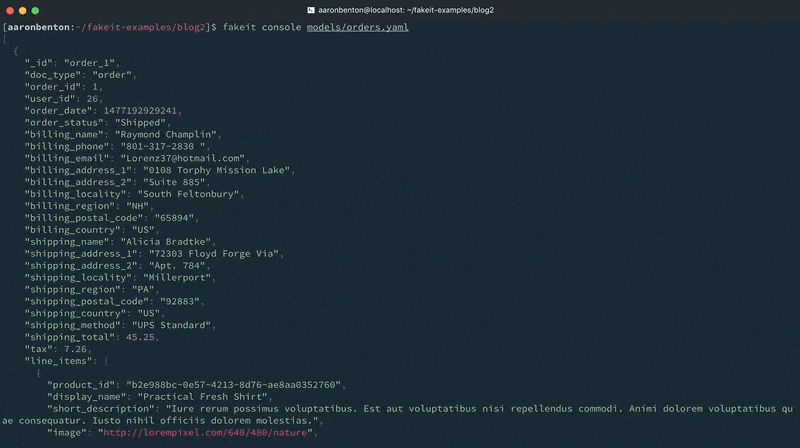
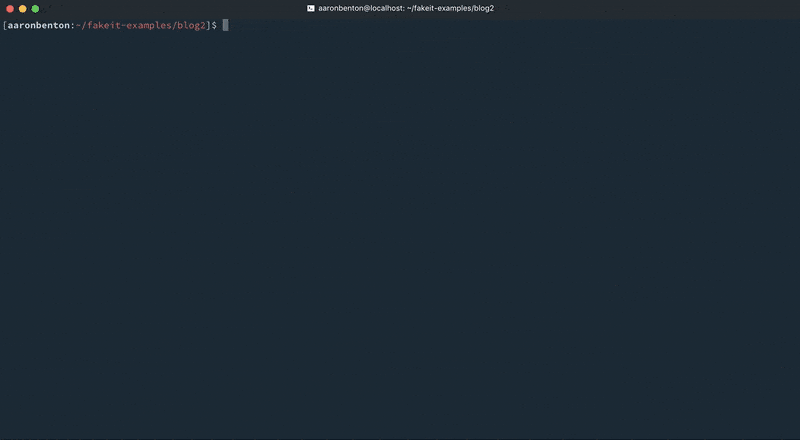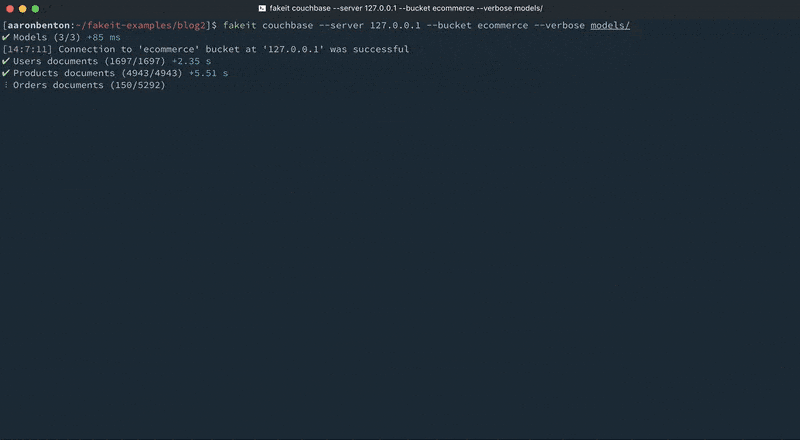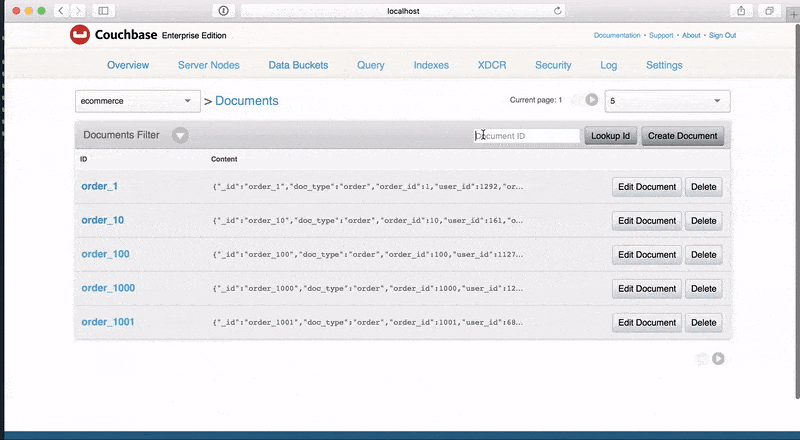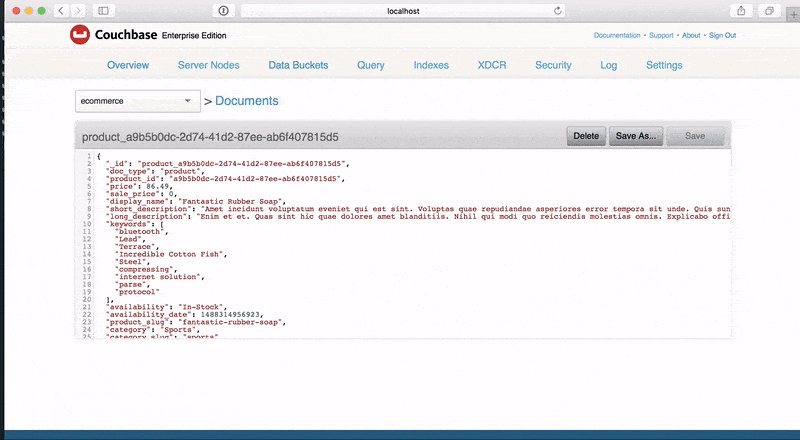
As you can see from the console output, the documents were generated for the Users and Products models, and those documents were made available to the Orders model. However, they were excluded from output because all that was requested to be output was the Orders model.
Now that we have defined 3 models with dependencies (Users, Products and Orders), we need to be able to generate multiple documents for each of these and output them to Couchbase Server. Up to this point we have been specifying the number of documents to generate via the –count command line argument. We can specify the number of documents or a range of documents by using the data: property at the root of the model.
|
1 2 3 4 5 6 7 8 |
users.yaml name: Users type: object key: _id data: min: 1000 max: 2000 |
|
1 2 3 4 5 6 7 8 |
products.yaml name: Products type: object key: _id data: min: 4000 max: 5000 |
|
1 2 3 4 5 6 7 8 9 10 11 |
orders.yaml name: Orders type: object key: _id data: dependencies: - products.yaml - users.yaml min: 5000 max: 6000 |
We can now generate random sets of related document models and output those documents directly into Couchbase Server using the command:
|
1 |
fakeit couchbase --server 127.0.0.1 --bucket ecommerce --verbose models/ |
Conclusion
We’ve seen through three simple FakeIt YAML models how we can create model dependencies allowing for randomly generated data to be related across models and streamed into Couchbase Server. We’ve also seen how we can specify the number of documents to generate by model by using the data: property at the root of a model.
These models can be stored in your projects repository, taking up very little space and allow your developers to generate the same data structures with completely different data. Another advantage of being able to generate documents through multi-model relationships is to explore different document models and see how they perform with various N1QL queries.
Up Next
- FakeIt Series 3 of 5: Lean Models through Definitions
- FakeIt Series 4 of 5: Working with Existing Data
- FakeIt Series 5 of 5: Rapid Mobile Development w/ Sync-Gateway
Previous
- FakeIt Series 1 of 5: Generating Fake Data
 This post is part of the Couchbase Community Writing Program
This post is part of the Couchbase Community Writing Program
[…] our previous post FakeIt Series 2 of 5: Shared Data and Dependencies we saw how to create multi-model dependencies with FakeIt. Today we […]
[…] far in our FakeIt series we’ve seen how we can Generate Fake Data, Share Data and Dependencies, and use Definitions for smaller models. Today we are going to look at the last major feature of […]