
…a drawing should have no unnecessary lines and a machine no unnecessary parts. —William Strunk Jr., Elements of Style
In the book Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems, Martin Kleppmann has written about traits and trade-offs of elements of data infrastructure for modern applications. In that book, he has drawn “Figure 1-1. One possible architecture for a data system that combines several components”. This is an exploration that example and possible architecture with Couchbase.
Example 1:
Figure 1 below is the architecture from the book.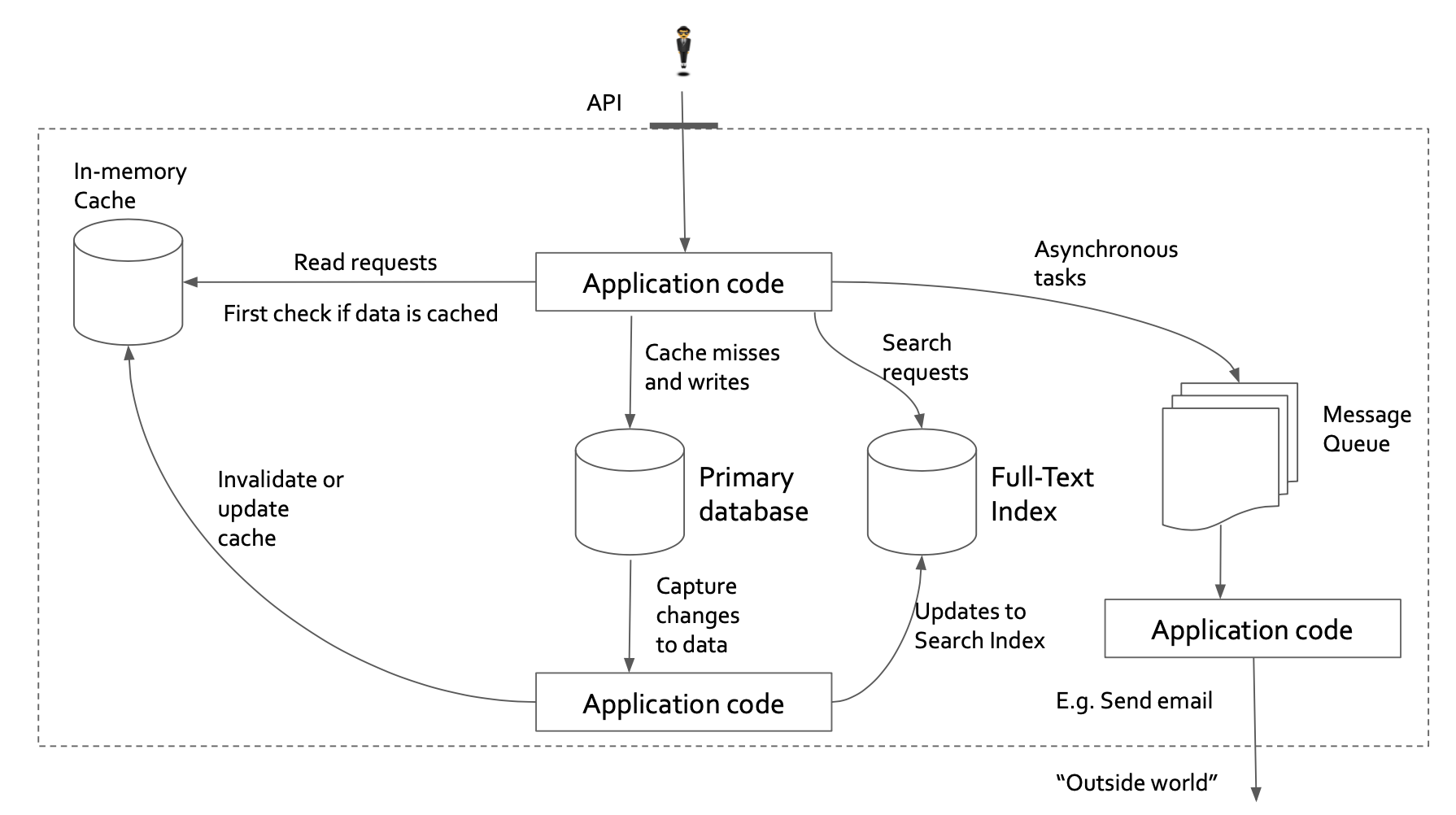
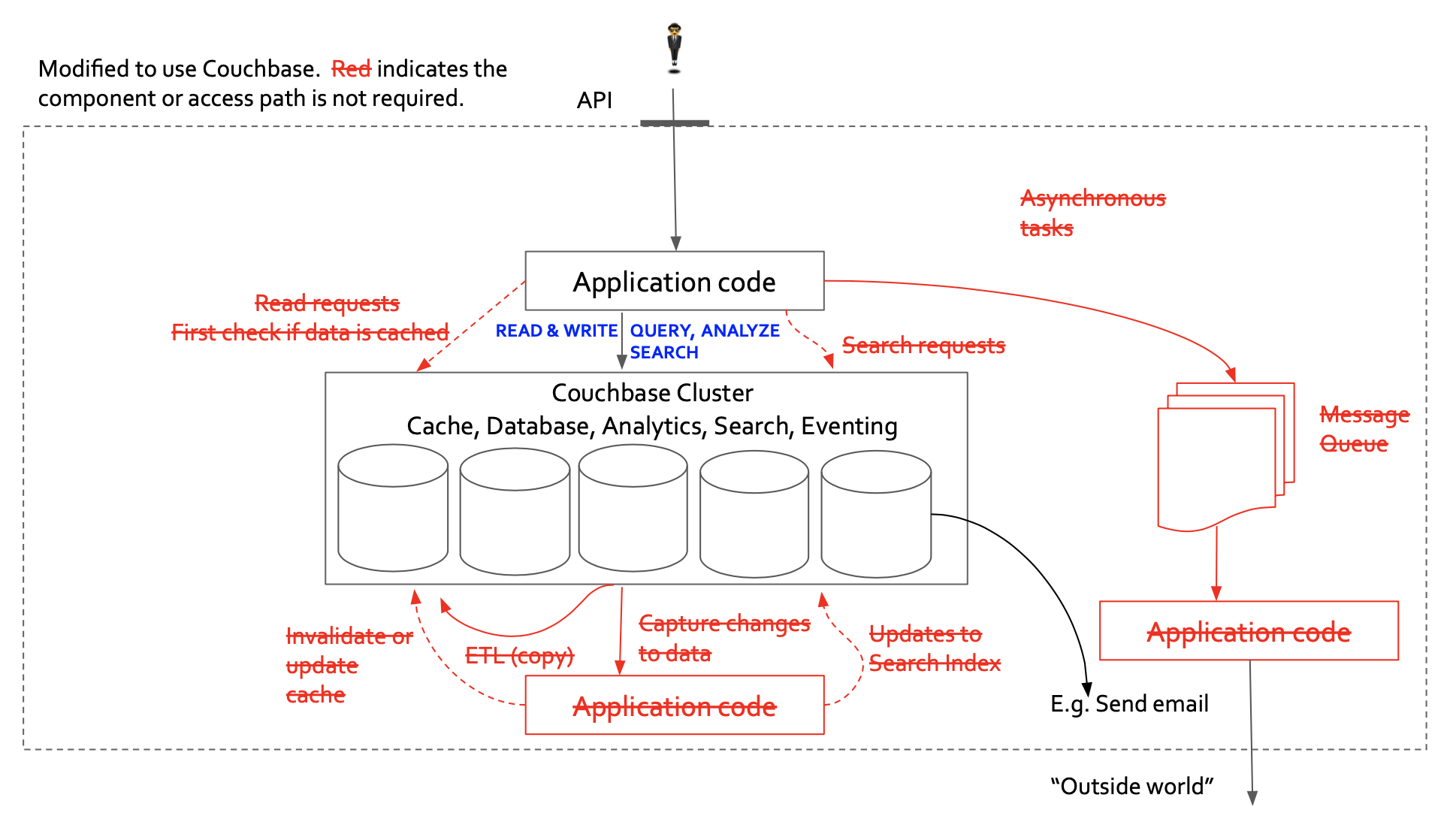
Let’s use a modern database like Couchbase which simplifies the infrastructure by providing scalable Cache, Database, Search, and Event processing within the same product. One bye one, we can replace each independent component with a scalable feature in Couchbase feature (in red).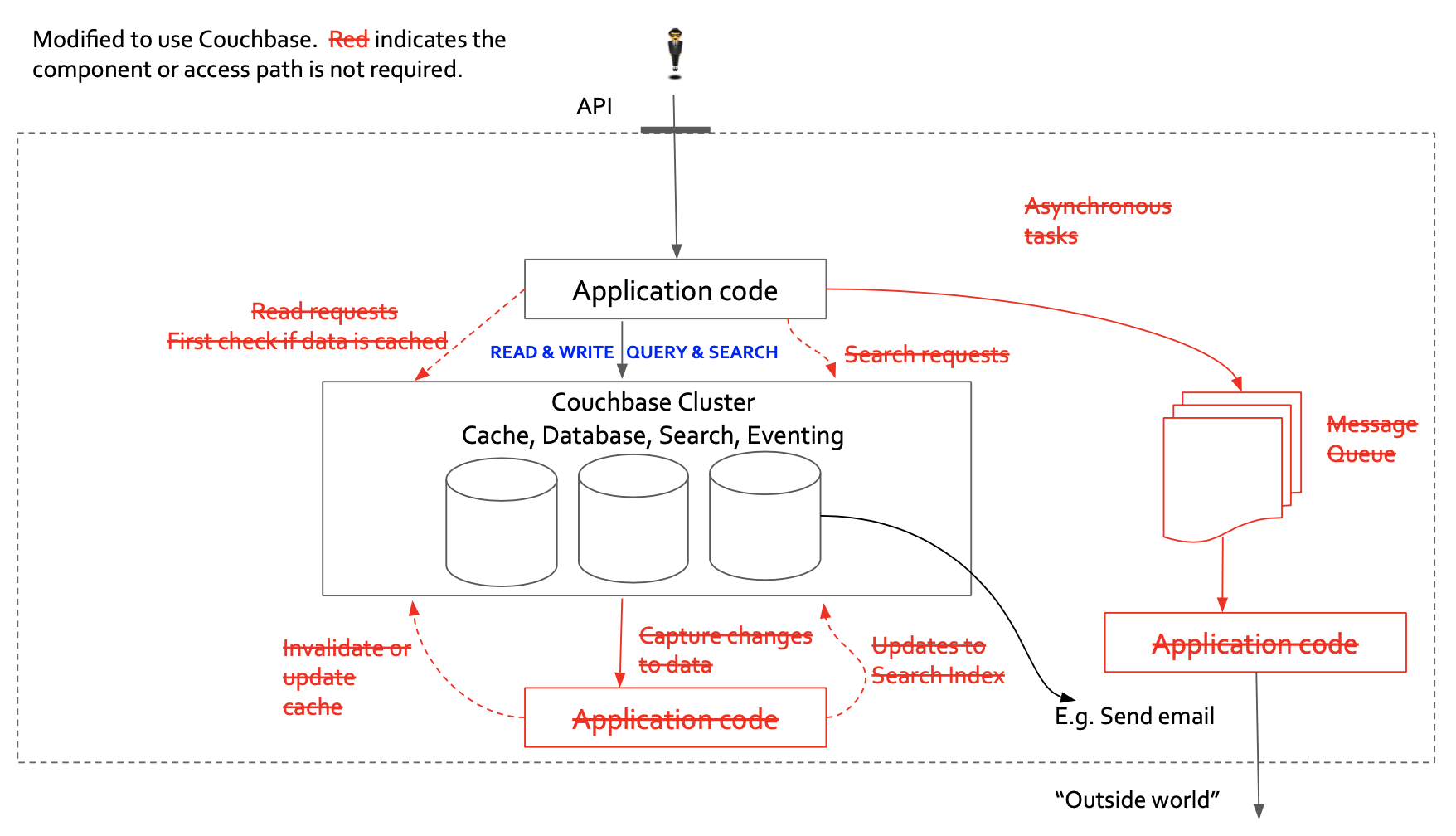
Let’s remove the unnecessary parts to get the new architecture.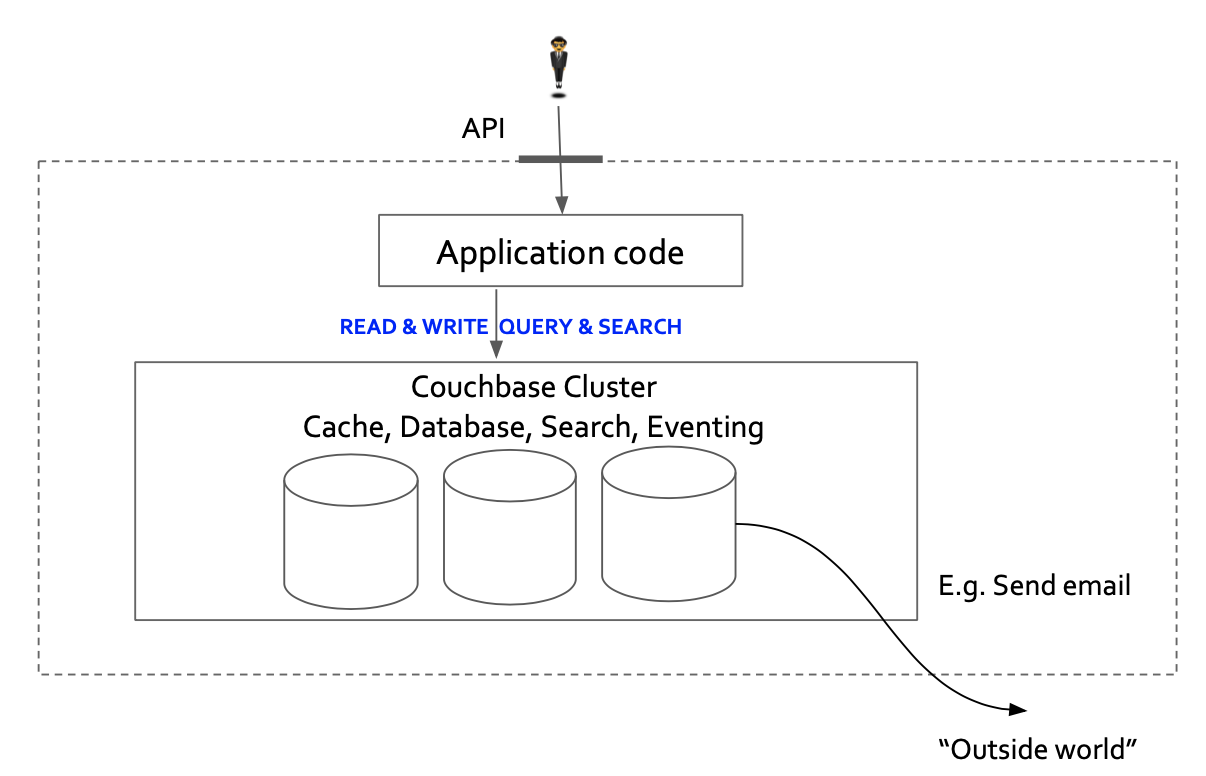
Example 2: I’ve added an additional common use case: data analysis and DataViz.
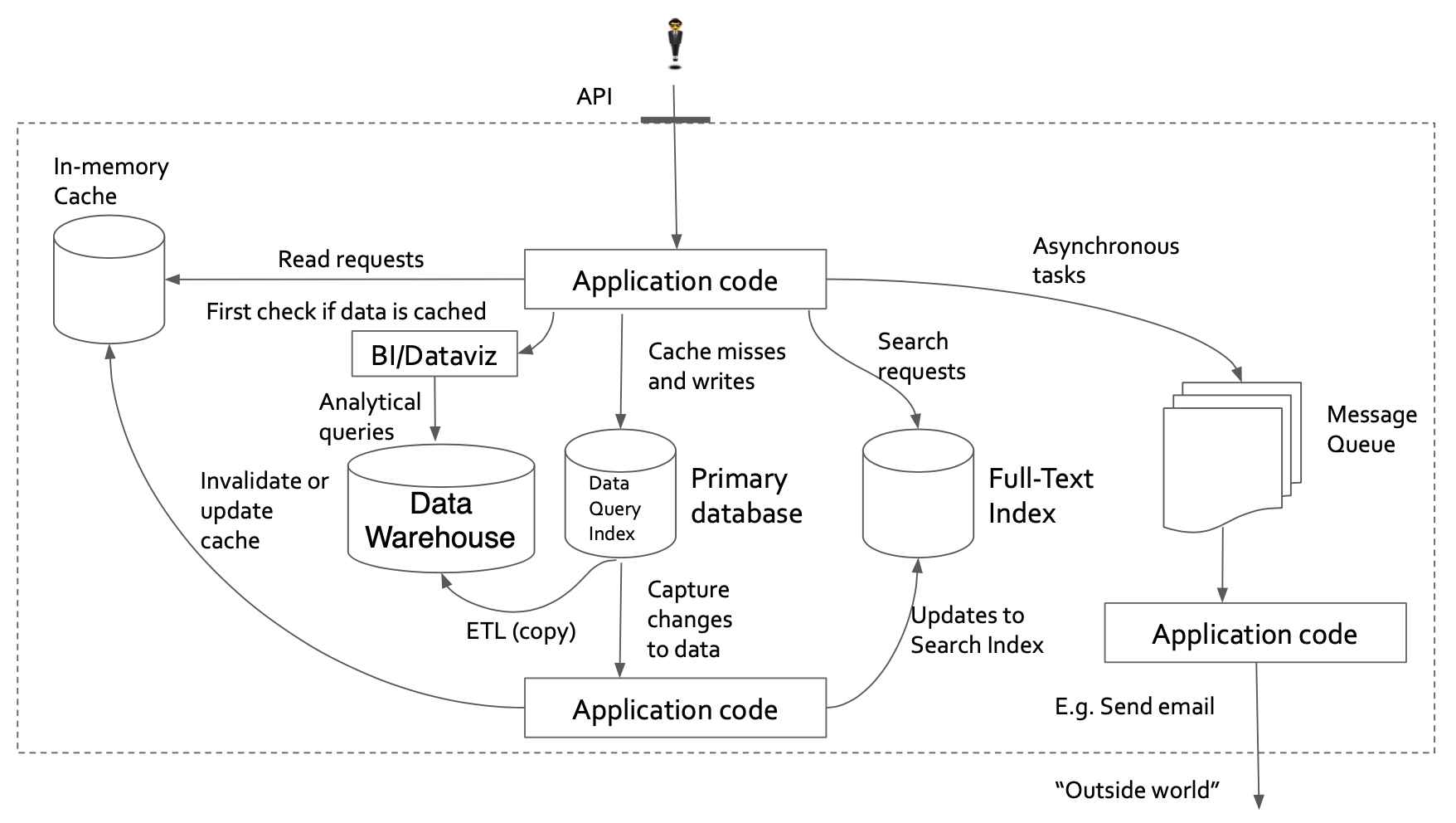
After using the same technique to use Couchbase and remove unnecessary components, we get this:
 Again, let’s remove the unnecessary parts to get the new architecture. Here, we’ve exploited the Analytics service available within Couchbase.
Again, let’s remove the unnecessary parts to get the new architecture. Here, we’ve exploited the Analytics service available within Couchbase.

This doesn’t mean everything can be simply rearchitected to use one or two products. The tendency of any infrastructure is to increase complexity. More components will increase complexity. This is a guide to continuously add, remove, and refactor the components to meet your business objective and to fight complexity.
What does Mesos have to do with something like execution of UDF?
——– Included Text ——–
On the other hand, deployment and cluster management tools such as Mesos, YARN, Docker, Kubernetes, and others are designed specifically for the purpose of running application code. By focusing on doing one thing well, they are able to do it much better than a database that provides execution of user-defined functions as one of its many features.
What does it mean to have serializable transactions run at a small scope?
——– Included Text ——–
For example, such a system could operate distributed across multiple datacenters in a multi-leader configuration, asynchronously replicating between regions. Any one datacenter can continue operating independently from the others, because no synchronous cross-region coordination is required. Such a system would have weak timeliness guarantees — it could not be linearizable without introducing coordination — but it can still have strong integrity guarantees.
In this context, serializable transactions are still useful as part of maintaining derived state, but they can be run at a small scope where they work well.
What does it mean to exhibit write skew anomalies?
——– Included Text ——–
I have personally seen cases of MySQL failing to correctly maintain a uniqueness constraint and PostgreSQL’s serializable isolation level exhibiting write skew anomalies, even though MySQL and PostgreSQL are robust and well-regarded databases that have been battle-tested by many people for many years.