
Moving data between data sources. This is one of the key activities in data integration projects. Traditionally, techniques around data movement has been part of Data Warehouse, BI and analytics. More recently Big Data, Data Lakes, Hadoop, are frequent players in this area.
In this entry, we will discuss how Couchbase N1QL language can be used to make massive manipulation on the data in this kind of scenarios.
First, let us remember the two classical approaches when doing data movement:
ETL (Extract-Transform-Load). With this model the data is extracted (from the original data source), transformed (data is reformatted to fit in the target system) and loaded (in the target data store).
ELT (Extract- Load-Transform). With this model the data is extracted (from the original data source), loaded in the same format in the target system. Then we do a transformation in the target system to obtain the desired data format.
We will focus in a ELT exercise in this example. Let us do a simple export from a relational database, and load the data into Couchbase. We will use Oracle Database as input data source, with the classical HR schema example built in, which models a Human Resources department.
This is the source data model:
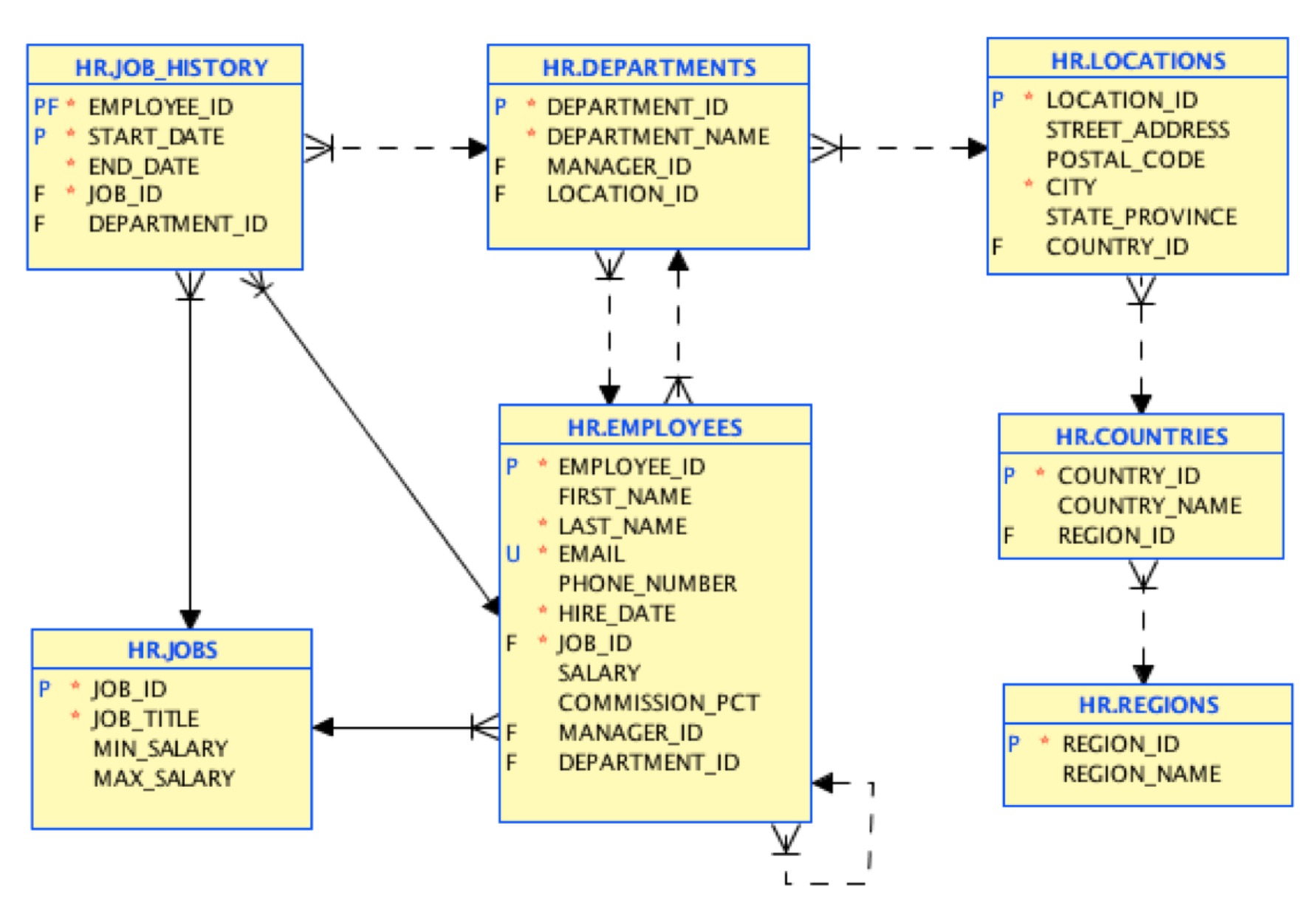
In the first step, we will load the data with the same structure. There is a free tool you can use to perform this initial migration here. At the end, we will have JSON documents mapping this table model:
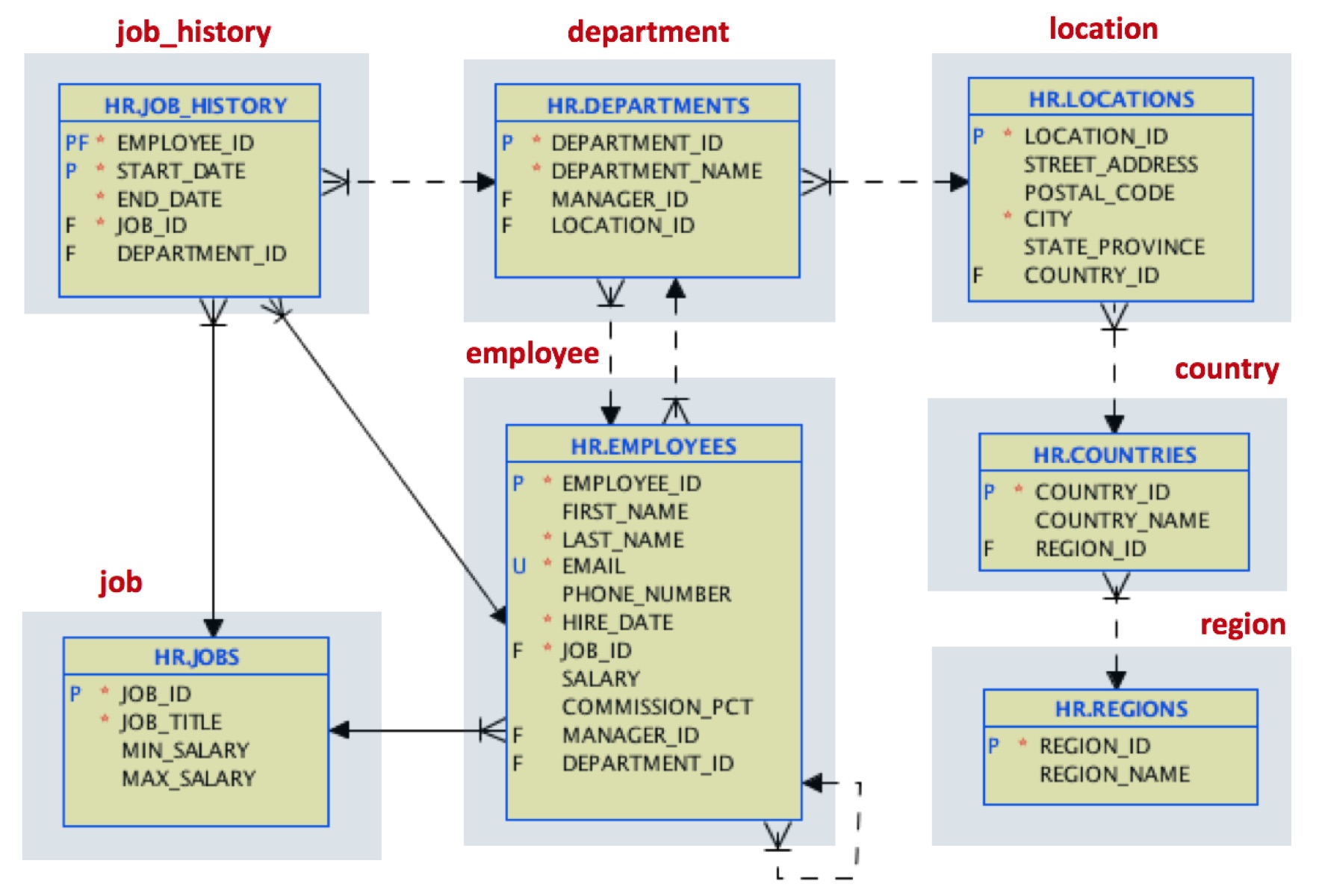
For example, a location document will look like this:
|
1 2 3 4 5 6 7 8 9 10 |
{ "street_address": "2017 Shinjuku-ku", "city": "Tokyo", "state_province": "Tokyo Prefecture", "postal_code": "1689", "type": "locations", "location_id": 1200, "country_id": "JP" } |
This was an easy first step. However, this mapping table-to-document is often a bad design in the NoSQL world. In NoSQL is frequent to de-normalize your data in favour of a more direct access path, embedding referenced data. The goal is to minimize database interactions and joins, looking for the best performance.
Let us assume that our use case is driven by a frequent access to the whole job history for employees. We decide to change our design to this one:
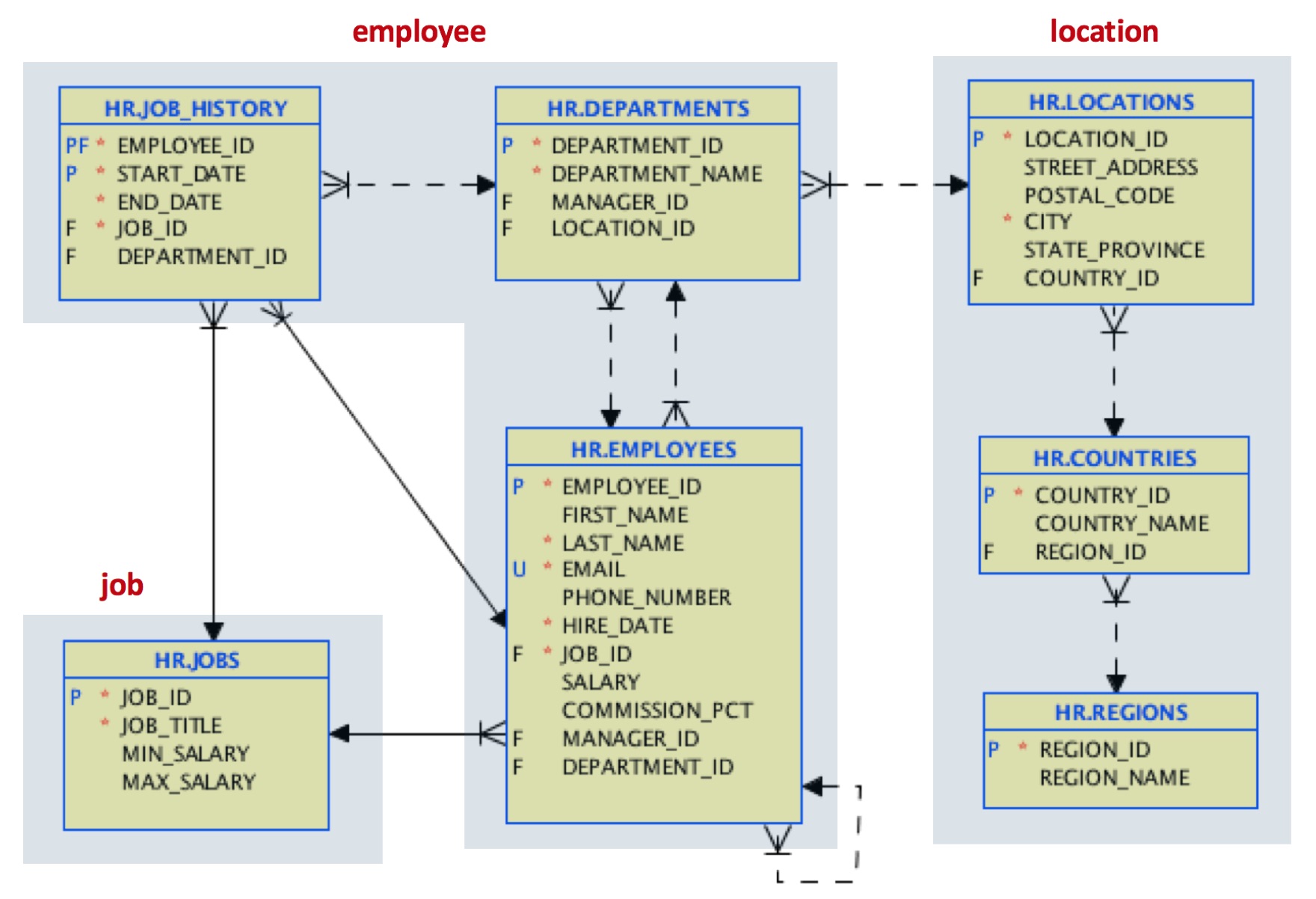
For locations, we are joining in a single location document the referenced data for country and region.
For the employee document, we will embed the department data, and will include an array with the whole job history or each employee. This array support in JSON is a good improvement over foreign key references and joins in the relational world.
For the job document, we will maintain the original table structure.
So we have extracted and loaded the data, now we will transform into this model to finish our ELT example. How can we do this job? It is time for N1QL
N1QL is the SQL-like language included with Couchbase for data access and data manipulation. In this example, we will use two buckets: HR, which maps to the original Oracle HR schema, and HR_DNORM which will hold our target document model.
We have already loaded our HR schema. Next step is to create a bucket named HR_DNORM. Then we will create a primary index in this new bucket:
|
1 |
CREATE PRIMARY INDEX ON HR_DNORM |
Now it is time for creating the location documents. This documents are composed of original locations, country and region documents:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
INSERT INTO HR_DNORM (key _k, value _v) SELECT meta().id _k, { "type":"location", "city":loc.city, "postal_code":loc.postal_code, "state_province":IFNULL(loc.state_province, null), "street_address":loc.street_address, "country_name":ct.country_name, "region_name":rg.region_name } as _v FROM HR loc JOIN HR ct ON KEYS "countries::" || loc.country_id JOIN HR rg ON KEYS "regions::" || TO_STRING(ct.region_id) WHERE loc.type="locations" |
Few things to notice:
- We are using here the projection of a SELECT statement to make the insert. In this example, the original data comes from a different bucket.
- JOINs are used in the original bucket to reference countries and regions
- IFNULL function used to set explicitly null value for the field state_province
- TO_STRING function applied on a number field to reference a key
Our original sample becomes this:
|
1 2 3 4 5 6 7 8 9 |
{ "city": "Tokyo", "country_name": "Japan", "postal_code": "1689", "region_name": "Asia", "state_province": "Tokyo Prefecture", "street_address": "2017 Shinjuku-ku", "type": "location" } |
Note we got rid of our references location_id and country_id.
Now it is time for our employee documents. We will do it in several steps. First one is to create the employees from the original HR bucket, including department and actual job information:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
INSERT INTO HR_DNORM (key _k, value _v) SELECT meta().id _k, { "type":"employees", "employee_id": emp. employee_id, "first_name": emp.first_name, "last_name": emp.last_name, "phone_number": emp.phone_number, "email": emp.email, "hire_date": emp.hire_date, "salary": emp.salary, "commission_pct": IFNULL(emp.commission_pct, null), "manager_id": IFNULL(emp.manager_id, null), "job_id": emp.job_id, "job_title": job.job_title, "department" : { "name" : dpt.department_name, "manager_id" : dpt.manager_id, "department_id" : dpt.department_id } } as _v FROM HR emp JOIN HR job ON KEYS "jobs::" || emp.job_id JOIN HR dpt ON KEYS "departments::" || TO_STRING(emp.department_id) WHERE emp.type="employees" RETURNING META().id; |
Second, we will use a temporary construction to build the job history array:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
INSERT INTO HR_DNORM (key _k, value job_history) SELECT "job_history::" || TO_STRING(jobh.employee_id) AS _k, { "jobs" : ARRAY_AGG( { "start_date": jobh.start_date, "end_date": jobh.end_date, "job_id": jobh.job_id, "department_id": jobh.department_id } ) } AS job_history FROM HR jobh WHERE jobh.type="job_history" GROUP BY jobh.employee_id RETURNING META().id; |
Now is easy to update our employees documents adding a job_history array:
|
1 2 3 4 5 6 7 8 9 |
UPDATE HR_DNORM emp SET job_history=( SELECT RAW jobs FROM HR_DNORM jobh USE KEYS "job_history::" || SUBSTR(meta(emp).id, 11) )[0] WHERE emp.type="employees" RETURNING meta().id |
This is how our employee document looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
{ "commission_pct": null, "department": { "department_id": 10, "manager_id": 200, "name": "Administration" }, "email": "JWHALEN", "employee_id": 200, "first_name": "Jennifer", "hire_date": "2003-09-16T22:00:00Z", "job_history": [ { "department_id": 80, "end_date": "2007-12-31T23:00:00Z", "job_id": "SA_REP", "start_date": "2006-12-31T23:00:00Z" }, { "department_id": 90, "end_date": "2001-06-16T22:00:00Z", "job_id": "AD_ASST", "start_date": "1995-09-16T22:00:00Z" }, { "department_id": 90, "end_date": "2006-12-30T23:00:00Z", "job_id": "AC_ACCOUNT", "start_date": "2002-06-30T22:00:00Z" } ], "job_id": "AD_ASST", "job_title": "Administration Assistant", "last_name": "Whalen", "manager_id": 101, "phone_number": "515.123.4444", "salary": 4400, "type": "employees" } |
Note the job_history array of previous positions.
We can delete now the temporary job_history documents:
|
1 2 |
DELETE FROM HR_DNORM emp WHERE meta().id LIKE "job_history::%" |
As last step we insert the original jobs documents:
|
1 2 3 4 |
INSERT INTO HR_DNORM (key _k, value _v) SELECT meta().id _k, _v FROM HR _v WHERE _v.type="jobs" |
We are done. This is a simple example, but shows can powerful can be N1QL data manipulation. Happy data migration!