
This is Part 2 in a series focused on leveraging the high-availability architectural capabilities and features of Couchbase Server on the Google Cloud Platform (GCP). The Couchbase concepts discussed here can be universally applied to any cloud environment where you deploy your cluster but the steps and commands are specific to GCP.
Part 1 covered how to achieve Couchbase node and service (Query, Index, Data, Search, Eventing, Analytics, Backup) resiliency. We showed how to do this by allocating services to specific nodes spread across specific GCP availability zones within a Region. You can read that blog here.
In this blog post, we enable Cross Data Center Replication (XDCR) between two Couchbase clusters running in GCP across two different regions. This implements database High Availability (HA), disaster recovery or geo-locality data enforcement. XDCR is not new to Couchbase and is available out of the box with every installed Couchbase cluster. XDCR can be used between any two versions of Couchbase Server (since version 2.5).
The five scenarios of data loss prevention
Couchbase Server architecture provides data resiliency (e.g., data loss prevention) on several different levels – from the single data mutation level all the way up to the cluster level. These are five of those levels in more detail:
Write Failure & Durability Levels
Data Write operations to Couchbase buckets can be assigned durability requirements. For example, Couchbase can be instructed to update the specified document on multiple nodes (in memory and/or disk locations across the cluster) before considering the write to be committed. The greater the number of memory/disk locations specified in the requirements, the greater the level of durability achieved. You can read more about setting these different levels in this product documentation page.
Node Failure & Failover
The Couchbase Data, Index and Full Text Search services allow replicas to be created at the document and index levels so that when a node running one of these services fails another replicate can be used. For example, the existing replicas that live on the still running nodes for those services become available so that your applications can still fully function. You can read in detail on how Couchbase’s underlying architecture supports this ability in this blog, Distributed Databases: An Overview.
Cloud Availability & Rack Zone Failures
Leveraging Multi-Dimensional Scaling (MDS) and Server Group Awareness protects your applications from losing data access due to a physical rack or cloud availability zone failure. Part 1 of this blog series covered how to separate Couchbase services across independent nodes within a cluster that is running across different physical racks in a datacenter or across cloud provider availability zones.
Cloud Region & Datacenter Failures
Replication is the key to providing high availability and fault tolerance at the cluster level. XDCR is a highly performant, memory-to-memory, replication technology used to replicate data between two Couchbase clusters. This is complementary to the intra-cluster replication behind our data auto sharding that is built into Couchbase’s architecture. XDCR provides asynchronous replication and maintains data consistency across sites via eventual consistency. We will walk through how to implement this capability between two separate Couchbase clusters in different GCP regions in this blog.
“Your World” Failure
Cluster Backups! Customers sometimes ask, “Why do I need to backup if I already have 100% availability?” The best answer to this question is another question, “What would you do if corrupt data is introduced into your cluster from an upstream system or application?” This is one of the few downsides of memory-to-memory replication: corrupt data will likely infest other clusters quickly, so you will need to restore an uncorrupted point-in-time backup. This scenario is very rare and we hope it is never encountered by our customers, but you should evaluate your current Couchbase backup practices and schedules just in case. In Couchbase 7 we introduced the Backup Service to further facilitate the automation of your backup and restore strategy. You can read about that here.
Five steps to implement cross datacenter replication (XDCR) with Couchbase on GCP
These are the high-level steps covered in this blog to implement XDCR between Regional GCP Couchbase clusters:
- Setup 2 separate Couchbase clusters in different regions of GCE
- Enable the travel-sample dataset on Cluster 1 that will be the source data for a unidirectional replication
- Create an empty bucket on Cluster 2
- Create an XDCR stream from Cluster 1 to Cluster 2 for an active/passive HA scenario
- Create an XDCR stream from Cluster 2 to Cluster 1 for an active/active HA scenario or to enforce geo-locality of data
Step 1
Follow the instructions in Part 1 to spin up two separate Couchbase clusters in different GCP Regions, such as us-east1 and us-central1. This is similar to deploying Couchbase in two different data centers in different geographic locations to protect your environments from geographical network infrastructure failure.
Step 2
In the Couchbase UI for the GCP-WEST cluster, go to the Settings section and click on the Sample Buckets link in the top right corner of the screen:
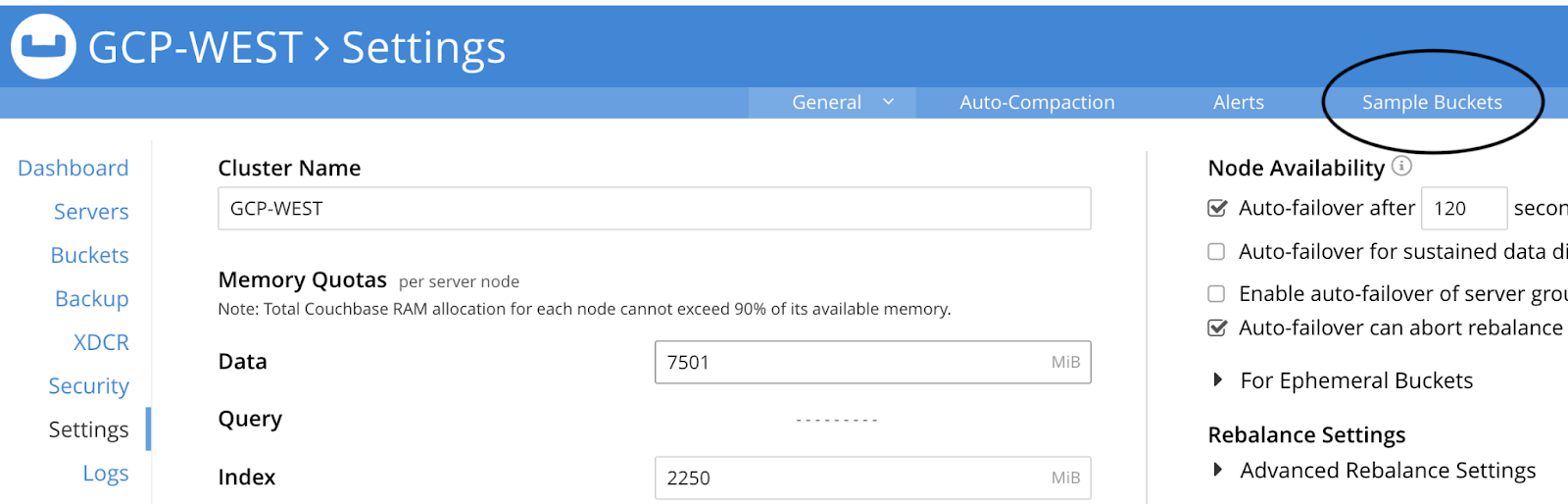
Then check the box next to travel-sample and click on Load Sample Data:
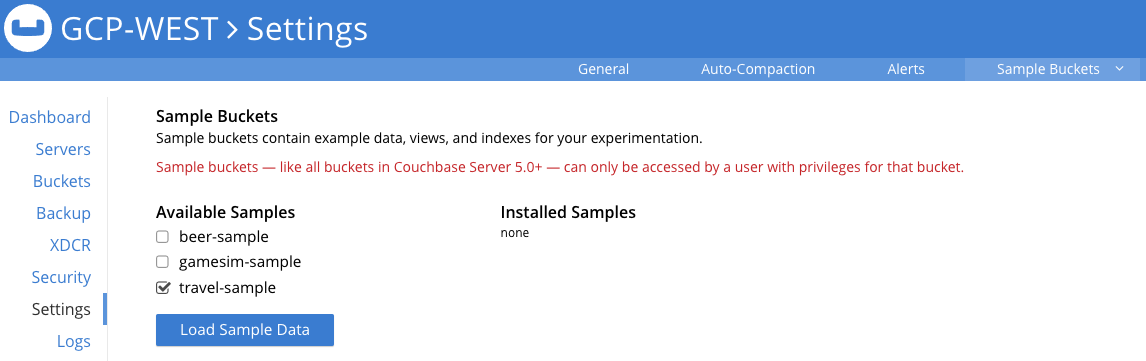
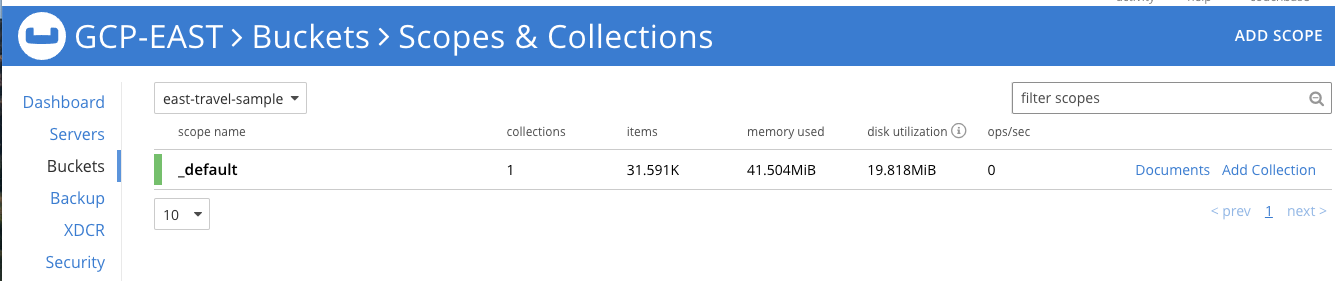
Give this a couple of minutes to load the dataset, then click over to the Buckets area in the UI to see the new bucket called travel-sample. All of the data is loaded once you see the item count shown below (version 7.x):

This will be the source bucket for our XDCR stream between the GCP East and West regional clusters. Before we can define and enable a stream to replicate this data we need to create a target empty bucket on the destination cluster to receive the data.
Step 3
On the second cluster, GCP-EAST, in the Admin UI, go to the Buckets area and click on ADD BUCKET in the upper right hand corner:

You will then see this window and can fill in the required values to create an empty target bucket.
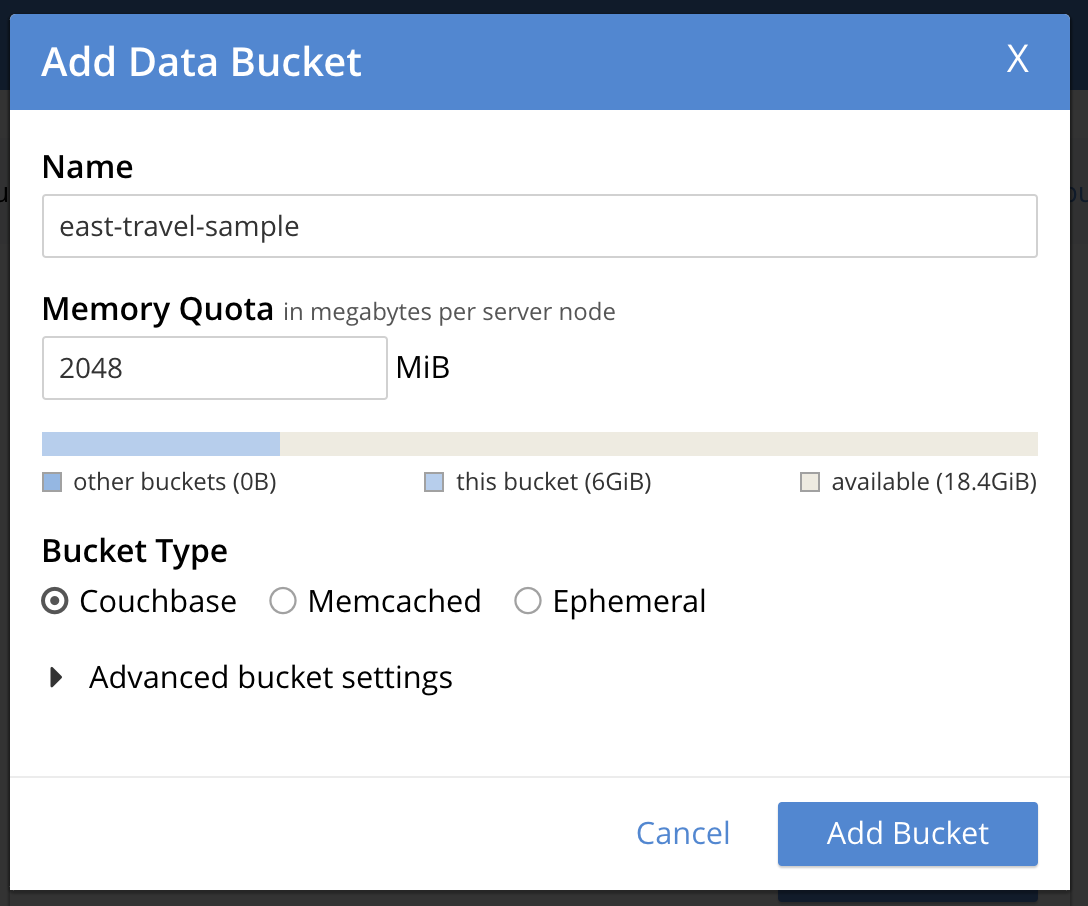
Once you click Add Bucket you should see it listed immediately. I have named the bucket differently from the source bucket to assist in knowing which cluster the screenshots are from. In real life, you would likely want to name them the same so that your application’s string values will not have to change in the event that you are switching from one cluster to the other.

Step 4
To implement an active/passive cluster strategy we set up a unidirectional XDCR stream from our GCP-WEST cluster travel-sample bucket to our GCP-EAST cluster east-travel-sample bucket. In the Admin UI for the GCP-WEST cluster in the XDCR section, click on ADD REMOTE in the upper right corner. This will open another pop-up window.
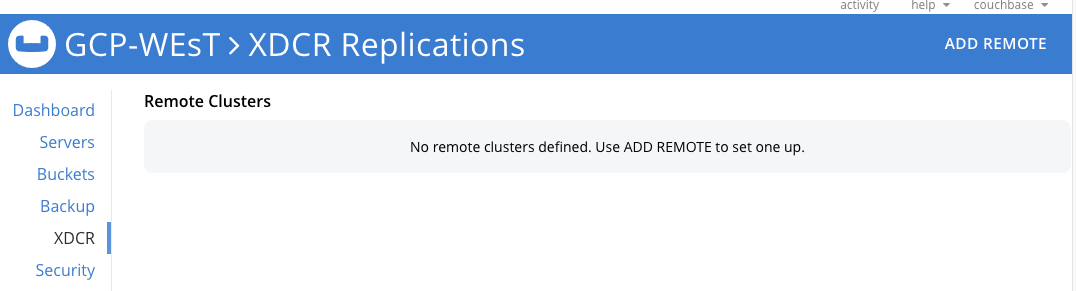
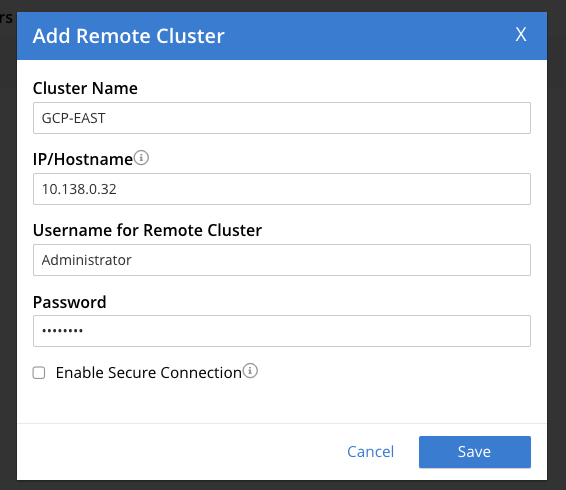
Click Save.
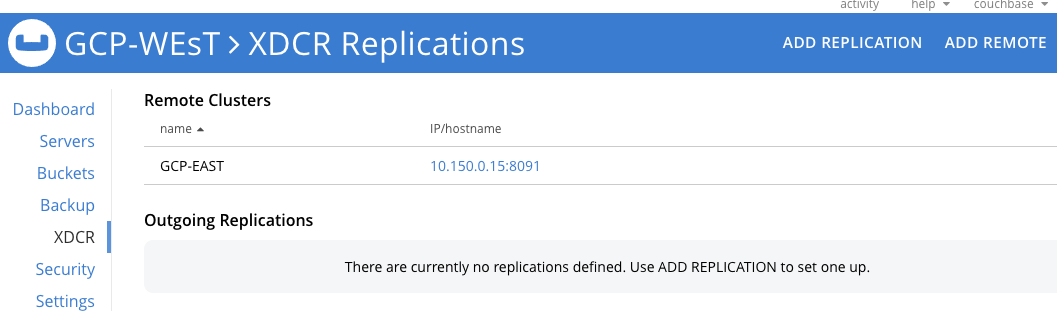
Now click on ADD REPLICATION to get to the screen where we can create a unidirectional stream from GCP-WEST to GCP-EAST.
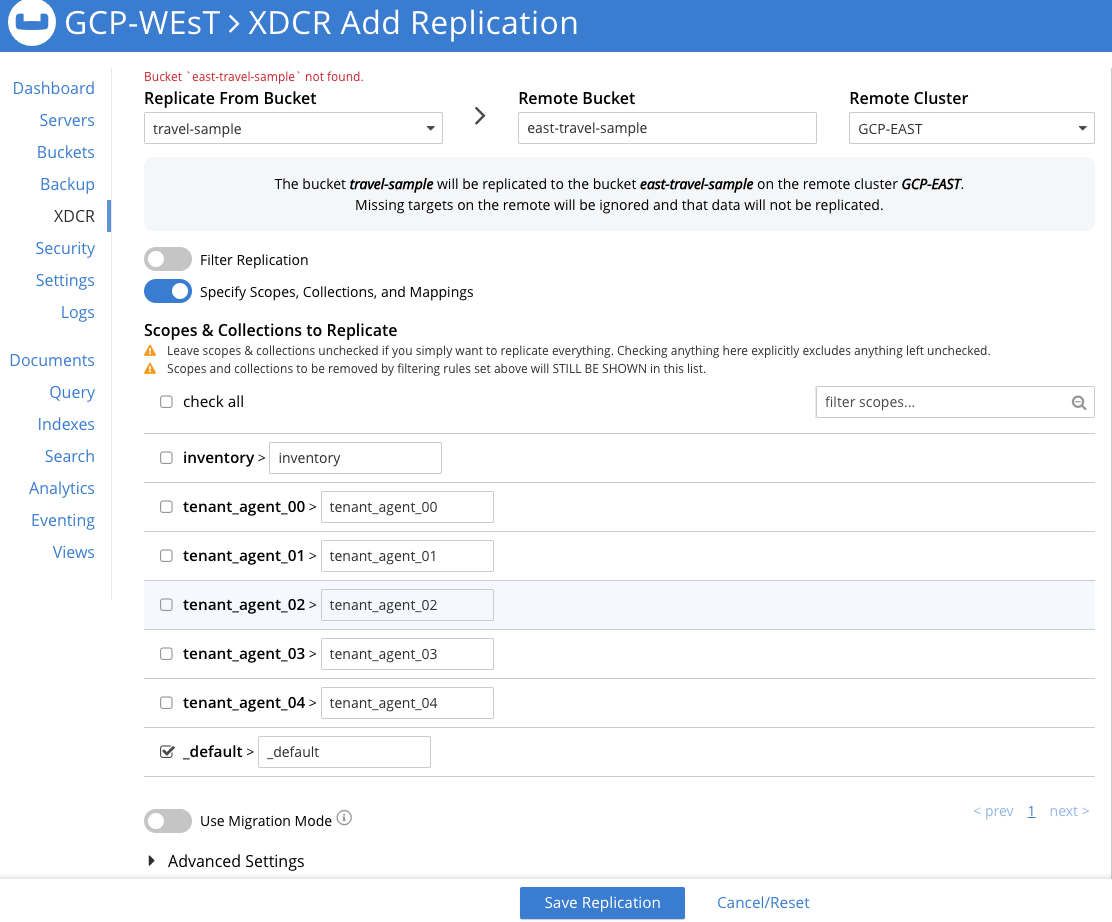
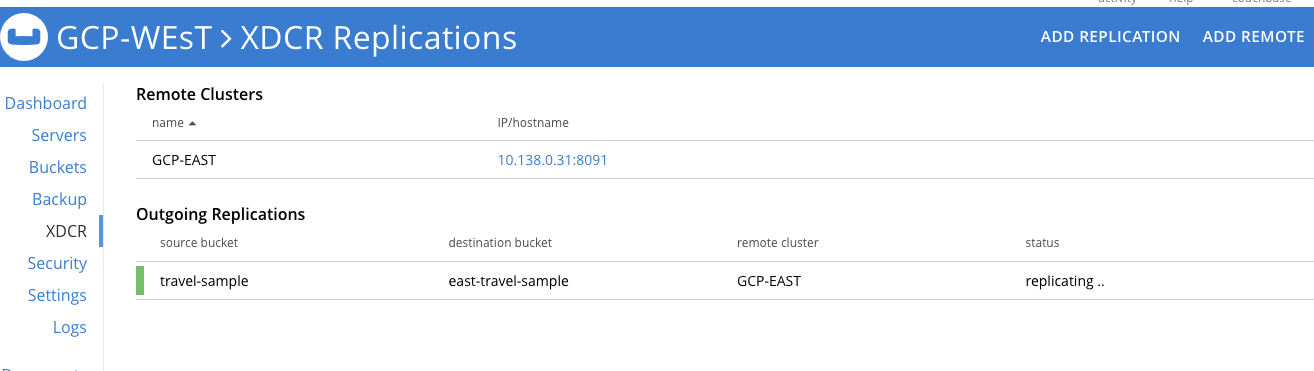
Once you enter in all of your stream customizations, click Save Replication and the stream will start immediately moving data to the GCP-EAST cluster and will continue as mutations occur in the travel-sample bucket.
I chose to only replicate the default scope in this stream so that you can see the different options now available in version 7 to split or combine scopes and collections as part of a replication stream. You can read in more detail about these options in this post: Introducing XDCR Support for Scopes and Collections in Couchbase 7.0.
Step 5
If you want to setup an active-active HA strategy for two or more Couchbase clusters you will need to create one unilateral XDCR stream going from Cluster 1 to Cluster 2 and then a parallel reverse stream from Cluster 2 to Cluster 1 for the same data set. For example as shown below, we have set up a unilateral stream on each cluster so that any mutations that hit one cluster are replicated to the other.
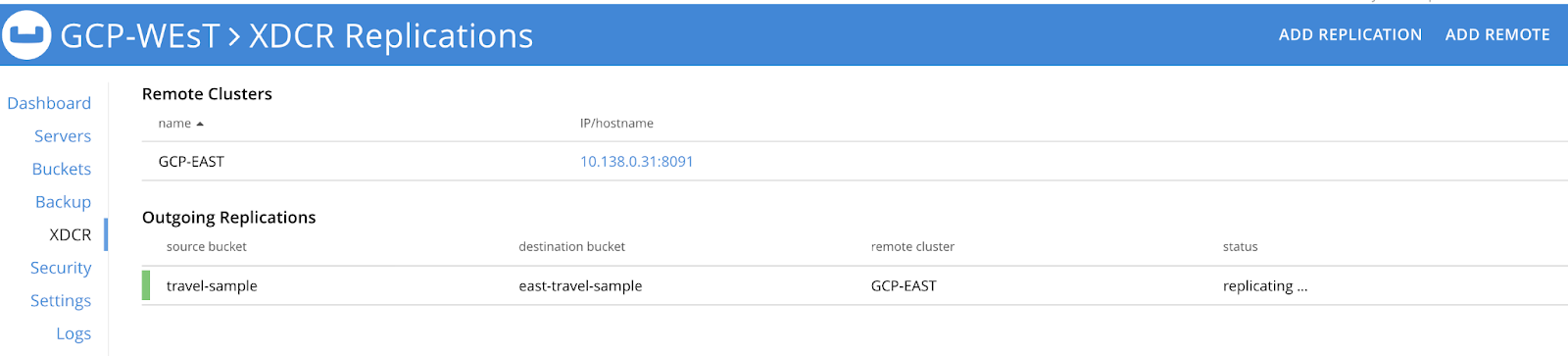
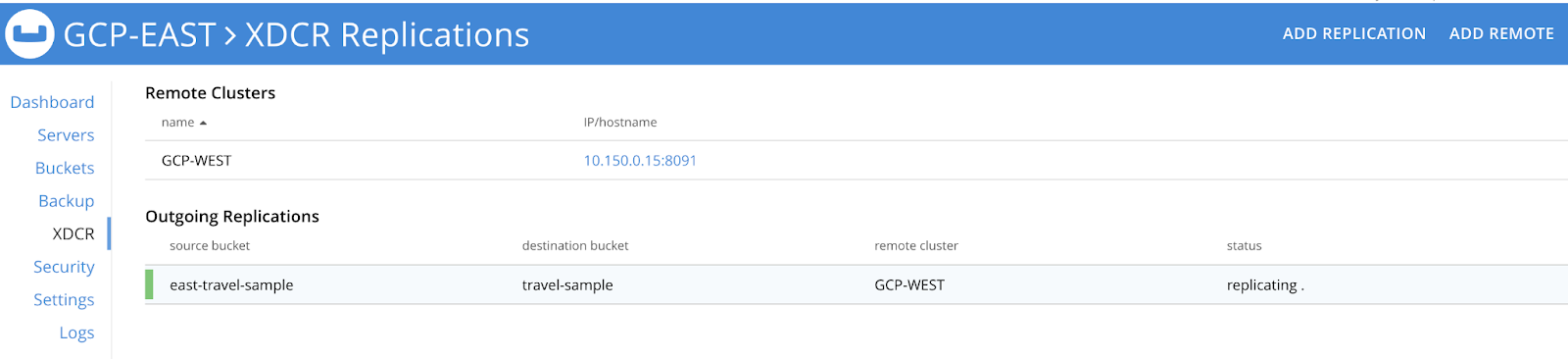
If you want to apply filtering rules to support data locality policies you can read about how to implement these capabilities here in this documentation page.
Conclusion
You’ve just seen how you can use XDCR to implement a key piece of your Couchbase Cluster HA strategy by protecting the applications using Couchbase from a Data Center or cloud network regional failure.
You can learn more about XDCR from these sources:
- Understanding Cross Data Center Replication (XDCR) Part 1
- XDCR: Replicate in Hybrid Cloud Deployments with Ease and Control is from our Couchbase Connect21 User Conference, covering tips and tricks (including new features for Scopes and Collections) for getting the most out of XDCR in Couchbase Server version 7, including new features included for Scopes & Collections.
Follow up by reading these resources to get you started with Couchbase on GCP:
- Deploying Couchbase for High-Availability in Google Cloud Platform – Part 1 – Server Group Awareness
- Couchbase offerings in GCP Marketplace
- Deploy Couchbase Server Using GCP Marketplace
- Best Practices for Running Couchbase on Google Compute Engine