
We saw in a previous post how easy is to set up a Cross Data Center Replication (XDCR), today let’s go a little bit deeper to understand what makes XDCR such a great feature.
First of all, XDCR allows you to replicate data between different-sized clusters, which makes it an excellent option for disaster and recovery plan. Apart from that, it is a simple yet powerful way to bring data closer to your users.
The replication is made from Memory-to-Memory. Thus all writes are saved in the memory first and then put in a replication queue, which sends it over the network through multiple threads. So, the whole performance is only limited by your network speed.
It is also topology-aware, and therefore whenever you add or remove nodes from the source cluster, no action needs to be taken on the destination cluster. It will re-establish the connection and handle everything automatically.
Moreover, it also provides rack zone awareness, which helps to protect against multi-node failure events by separating active data and its replicas across “groups” which can then be mapped such that they occupy different racks, zones, or VM hosts.
Replications are made on the bucket level (between buckets of two or more clusters), and can be configured as follows.
- Unidirectional: Only the data written in one of the clusters is replicated, it is used when you want to configure a standby cluster for example.
- Bidirectional: (also known as active-to-active deployment) where both clusters can write data and all changes are synchronized between them. In summary, a bidirectional mapping is just two unidirectional replications pointing to each other.
- Hybrid: A combination of Bidirectional and Unidirectional topologies.
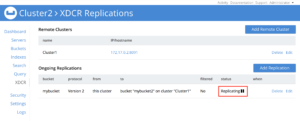
Thanks to DCP, you can also pause the replication at any time, and once you resume it, the recovery starts at the most recent checkpoint.
Database Change Protocol
Database Change Protocol (DCP) is a high-performance streaming protocol we use internally to communicate the state of data using an ordered changelog. It is robust and resilient in the face of transitory errors, for example, if the communication is interrupted, DCP is capable of resuming from the exact point of the last successful update once the connectivity is back.
It is also optimized to send only necessary data. For example, if there are several changes in a document, just the most recent version is marked to be replicated.
XDCR relies on DCP to propagate changes. This way it guarantees the same document will be replicated among all clusters regardless of connectivity problems.
Let’s also highlight another two exciting features of XDCR: Conflict Resolution and Data Filtering:
Conflict Resolution
A conflict is where the same document is modified in two different locations before it has been synchronized between the locations. To maintain consistency, one version has to be chosen as the ‘correct’ version. Conflict resolution provides a method to consistently and deterministically select which version of the document to use.
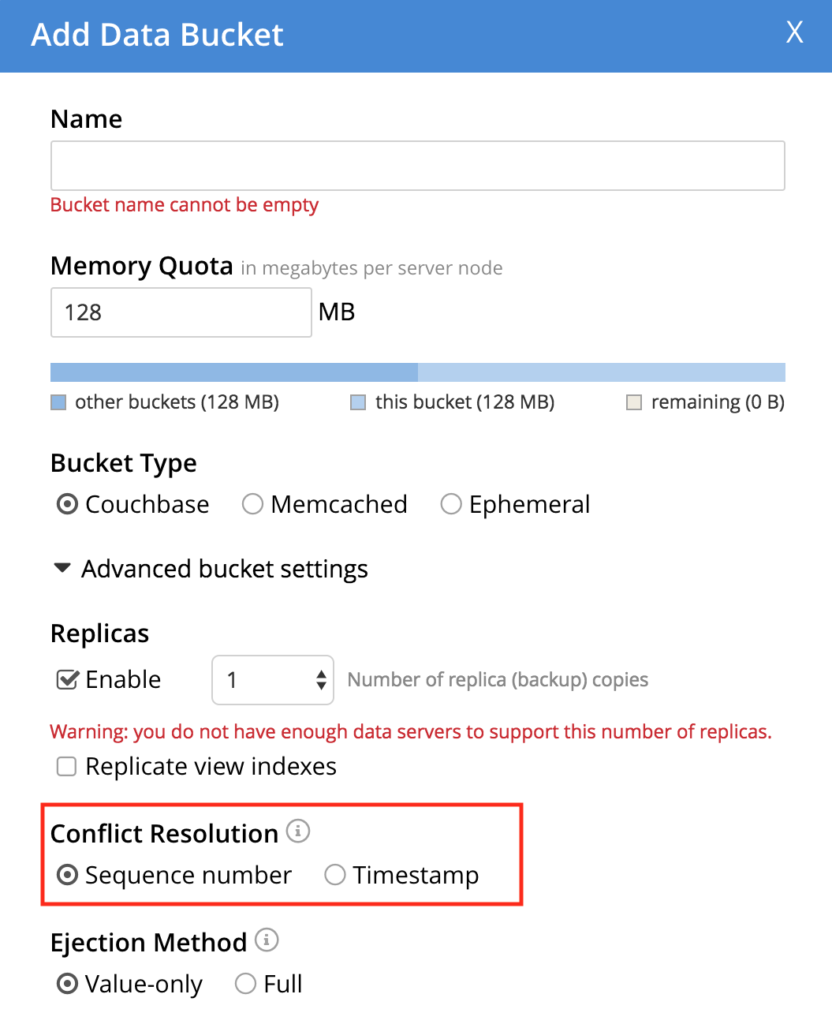
Couchbase’s conflict resolution is set during the bucket creation and can’t be changed later. Currently, two types of conflict resolutions are supported: Timestamp and Sequence Number.
Sequence Number
After every mutation in a document we increase a counter called revision number, so whenever there is a conflict between two documents, the one with the highest revision number will take precedence on both clusters.
Timestamp
Timestamp-based Conflict Resolution (TCR) is the most commonly supported conflict resolution mechanism in databases, TCR resolves conflicts by selecting the document with the most recent timestamp. To be able to perform this effectively it is essential that the time stamps created by each server are closely aligned.
However, TCR might increase data loss, as it ignores how many times a document has been updated, and if one of the server’s clock is fast/slow you will end up with a messed up conflict resolution. That is why the default option in Couchbase is “Sequence Number”.
Data Filtering
By default, all documents within a target bucket will be replicated, but since Couchbase 6.5 you can use Filtering Expressions to filter which data you want to replicate.
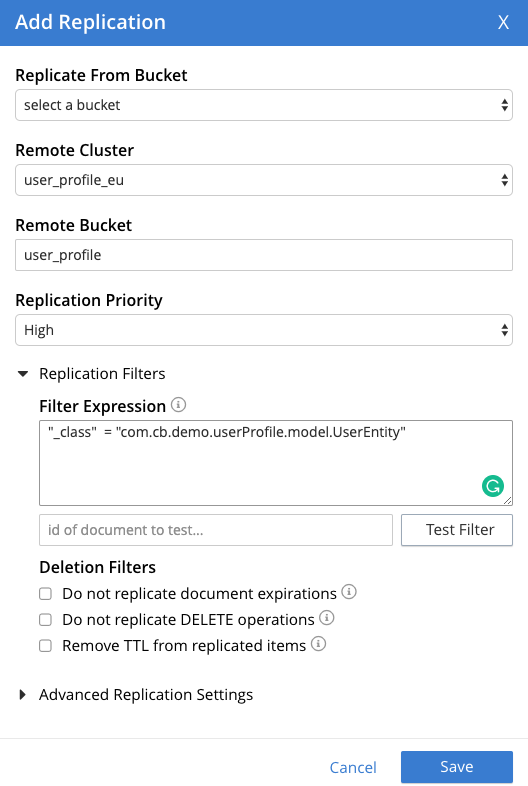
Advanced filtering supports various language constructs to build filters such as regex, arithmetic, logical and relational operators, keywords, expressions, number Functions, date functions, negative lookahead, etc. You can apply those features on the document’s keys, values, metadata, and CAS. Just like predicate of N1QL queries, expressions can be constructed using the supported language constructs.
In the Deletion Filters session, you can also choose to not replicate delete operations, document expirations or remove TTL and store it for archival purposes.
The filters can also be edited on the fly and the replication will continue without any pause/resume.
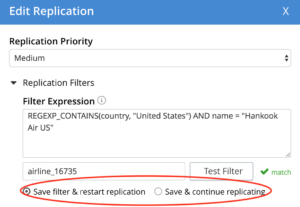
XDCR, by default, will not flush any buckets when filters are modified. This step should be manually executed by the administrator if necessary.
Conclusion
If you need a Disaster & Recovery plan or just would like to bring your data closer to the user, Cross Data Center Replication (XDCR) is a feature you should consider using, It is simple to set up, requires almost no maintenance and has been heavily tested in several high load use cases like Amadeus, eBay and Viber.
For more information on XDCR with Couchbase, check out the Couchbase Developer Portal or tweet me at @deniswsrosa
Updated on 08/08/19 – Adding new XDCR features for Couchbase 6.5