
In a distributed system, updates to a shared database from multiple clients will have to be synchronized. The goal of the replication process is to ensure that all the mobile clients and the server(s) have a consistent view of the data by synchronizing changes across the local and remote databases. In Couchbase Mobile, replication occurs between the clients running Couchbase Lite and the server’s Sync Gateway.
The Couchbase Mobile 2.0 release brings a plethora of new features and enhancements. A key enhancement is the new and improved replication protocol. This post will introduce you to the fundamentals of the new replication protocol in Couchbase Mobile 2.0.
You can download Couchbase Mobile 2.0 from here.
It should be noted that the protocol may change over time and and should not be used directly. The purpose of the post is to give you a broad understanding of the protocol to facilitate debugging
Background
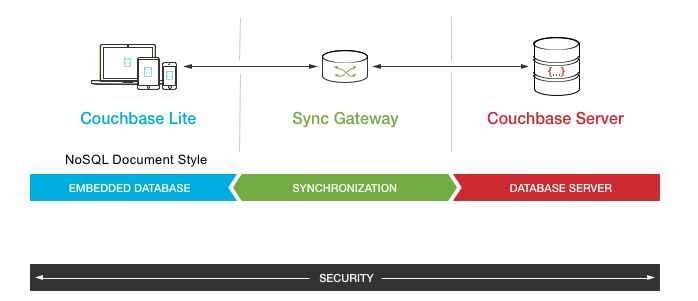
The Couchbase Mobile Platform comprises the Couchbase Lite NoSQL embedded database running on clients; the Sync Gateway responsible for data synchronization, data routing and user authentication/authorization; and Couchbase Server for data persistence and management.
In V1.x of Couchbase Mobile, replication was implemented using a REST-based protocol originated by CouchDB over HTTP(s). Effectively, the replication logic was implemented as a series of API calls over HTTP.
New Layered Architecture
Replication Protocol 2.0 is implemented as a new messaging protocol layered over WebSockets. It is supported across all supported Couchbase Lite 2.0 platforms and Sync Gateway 2.0.
The WebSocket protocol enables full-duplex message passing between remote hosts over a single TCP socket connection. The WebSocket protocol starts off as an HTTP(s) connection and switches over to Websockets if the remote host supports it.
The new messaging protocol, invented by Jens Alfke, adds multiplexing and request/response support to the Websockets layer. The new layered architecture is cleaner and allows for a separation of concerns between the replication logic and the underlying messaging transport. The new protocol is faster and requires reduced bandwidth and socket resources. The savings in socket resources would allow for increased support for concurrent connections at the server. Finally, the bi-directional nature of the WebSocket protocol lends itself well to peer-to-peer configurations.

Compatibility
The new replication protocol is supported on Couchbase Lite 2.0 clients and Sync Gateway 2.0. Check out the compatibility guide for details.
This is the default replication protocol that will be used in Couchbase Mobile 2.0. You do not have to specifically enable it in the Sync Gateway configuration. In case of Couchbase Lite 1.x clients, the Sync Gateway will automatically switch to the older replication protocol.
Terminology
Here are some terms we will be using in this discussion
- “Client” : Couchbase Lite 2.0 client
- “Server” : Sync Gateway 2.0
- “Source Database” : The local database from which changes are replicated
- “Target Database” : The remote database to which changes are replicated
- “Source Replicator” : The replicator that is sending database changes
- “Target Replicator” : The replicator that is receiving database changes
- “Push Replication” : Process by which clients upload database changes from the local source database to the remote (server) target database
- “Pull Replication” : Process by which clients download database changes from the remote (server) source database to the local target database
- “Active Replicator” : Couchbase Lite Replicator which automatically pushes or pulls database changes
- “Passive Replicator” : Sync Gateway Replicator which responds to push or pull requests for changes
Replication Modes
The replication process can be “continuous” or “one shot“.
- In “Continuous” replication mode, the changes are continually synchronized between the client and Sync Gateway.
- In “One shot” mode, the changes are synchronized once and the connection between the client and server disconnects. When any future changes need to be pushed up or pulled down, the client must start a new replication.
Concepts
Before we look at the protocol, we need to have an understanding of some key concepts.
Revision Trees
Couchbase uses a Multi Version Concurrency Control (MVCC) system for managing documents. In such a system, every document in Couchbase Mobile is stored as a sequence of revisions. A new revision is automatically created when a document is created. Every update to the document, whether an edit or a delete, will result in the creation of a new revision for the document. The special revision marking a deletion is called the tombstone revision. The current revision is the leaf revision of the document and in case of conflicting revisions, it corresponds to the winning revision. For more details on revisions trees and conflict resolution in 2.0, stay tuned for an upcoming blog post on this topic.
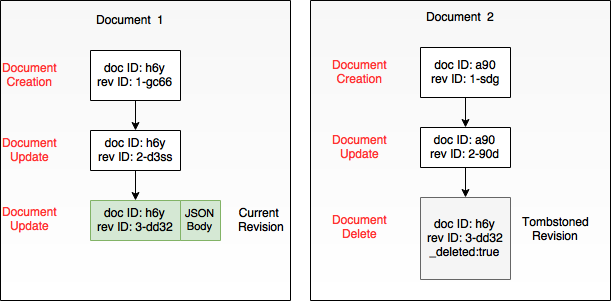
Change
The current revision that exists in the source database but not in the target database is referred to as a change. So effectively, the replication process synchronizes changes between remote databases.
Sequence ID
Every change is associated with a unique Sequence ID that is in chronologically increasing order. It’s similar to a last-modified timestamp except that it’s not a wall-clock time, rather an auto-incrementing counter. Sequence IDs are specific to a particular database, so when a document is replicated it does not end up with the same sequence ID.
Note: While Couchbase Lite’s sequence IDs are simple integers, Sync Gateway’s may be long base64 strings. The reasons why are complex and have to do with the internal concurrency between nodes in a Couchbase Server cluster. The exact contents of a remote sequence ID are implementation-dependent and a client should never make assumptions about them.
Checkpoint
The checkpoint is a record of the last sequenceID replicated by the replicator. At the end of every replication cycle, the replicator will checkpoint the source sequenceID corresponding to the last change sent to the target. The very first replication cycle will have no checkpoints.
What does Replication really do ?
Now that you have an understanding of the key concepts, replication can be described as the process by which the source replicator sends all the changes, whose sequence IDs are greater than the last checkpoint, to the target replicator. Revision bodies of the current revisions along with associated blobs/attachments and the revision history are replicated.
Note: It is possible that the same document gets edited concurrently at the source and target database, resulting in a conflict. We will discuss conflicts and replication a little later in the post.
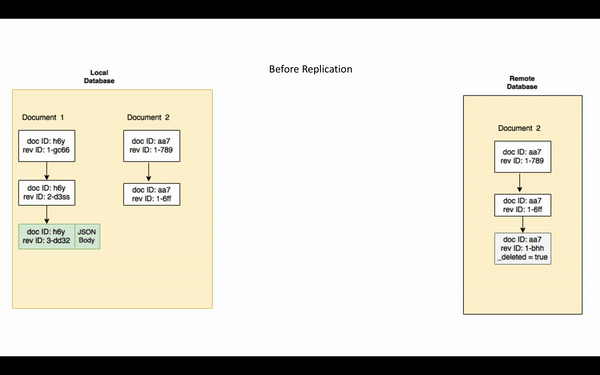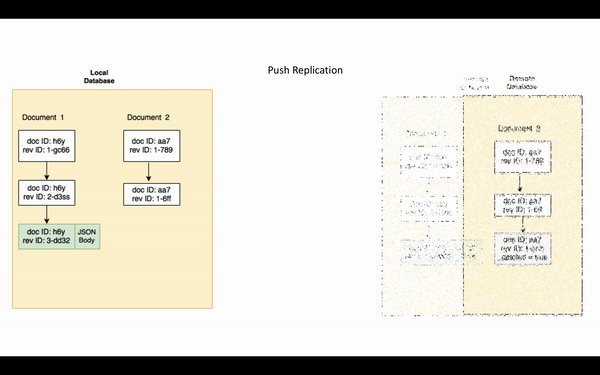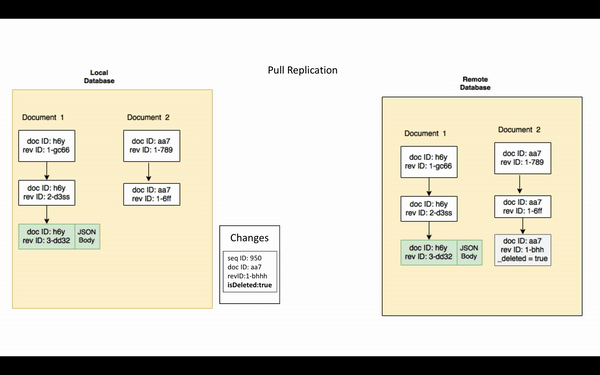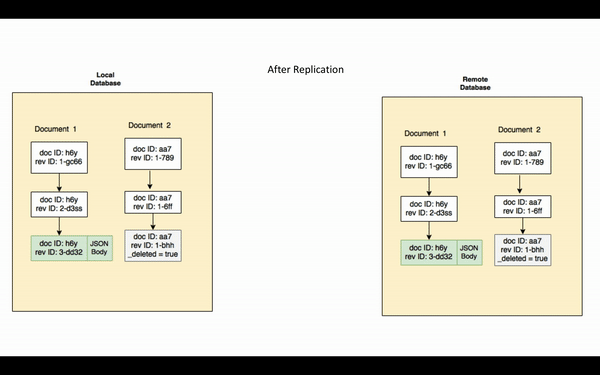
Note that if a document is purged from the database, the purge will not be replicated. Purging removes all traces of the document from the database.
The URL Scheme
Couchbase Lite clients must use the ws URL scheme to connect to the Sync Gateway
Here are some examples –
|
1 2 3 4 |
ws://sync-gw-address:4984 wss://sync-gw-address:4984 |
The Protocol
Connection Establishment
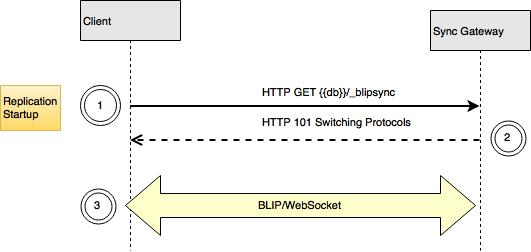
- When replication starts up, the client sends a WebSocket handshake request to the server over HTTP(s) indicating that it wants to switch to WebSocket. This is an HTTP GET request, with special headers, to the resource
_blipsyncrelative to the database’s URL. - The server responds indicating that it agrees to the protocol switch.
- Once the Websockets Handshake is done, the socket stops being used for HTTP, and all further communication is WebSocket messages.
A single socket can support both a push and a pull replication simultaneously. Both types store and retrieve checkpoints, and require those checkpoints in order to proceed, so checkpoint management will be described first.
Checkpoint Management
Both push and pull replications store and fetch checkpoints on the server.
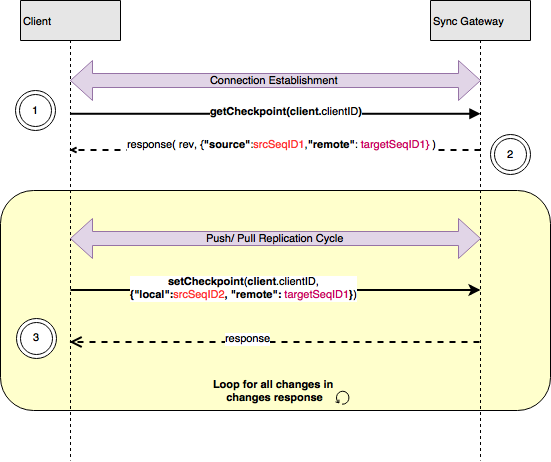
- After connection establishment, the client sends a
getCheckpointmessage to the server in order to determine the last known source sequence ID at the server. The request includes:- client ID which identifies the client
- The response to
getCheckpointrequest includes the last recorded checkpoint for the client. The checkpoint is a JSON object previously created and stored by the client ; it can contain whatever data the client wants, but it’s currently of the form:- local sequence ID which is the last known sequence pushed up by the client
- remote sequence ID which is the last sequence ID received by the client
- As sequences are successfully replicated, the client periodically sends a
setCheckpointmessage to record the last local sequence ID that was sent, and/or the last remote sequence ID that was received.
Push Replication
During push replication, a series of changes are automatically sent out automatically by the active replicator to the passive replicator
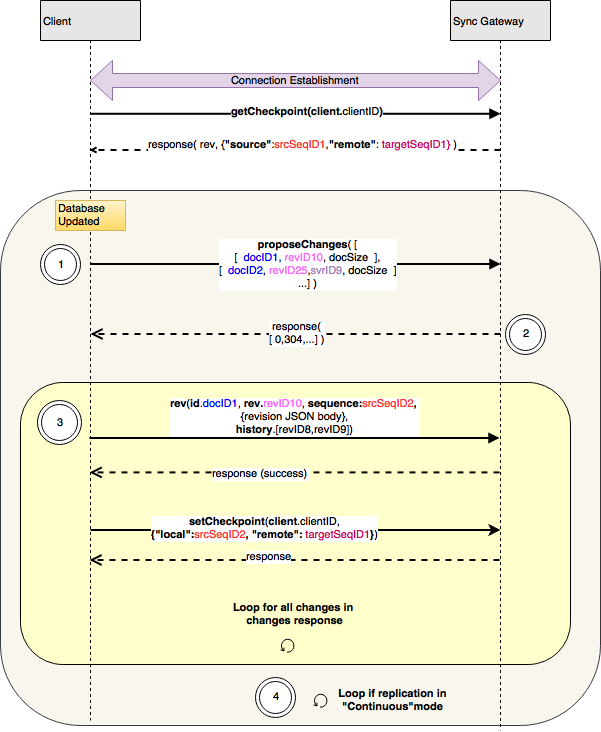
- After the checkpoint is retrieved, and when the client side replicator detects changes to its local database since the local sequence ID, the client sends a
proposeChangesmessage to server with an array ofchangeobjects corresponding each current revision that has changed. This includes tombstoned revisions. The change itself is encoded as a nested JSON array and includes:- document ID of the document associated with the change
- revision ID of the current revision of the document
- server Rev ID of known server revision, if any . It is omitted if there is no known server Rev ID
- Optionally, approximate size of the document body
- The server’s response to the
proposeChangesrequest includes a JSON object containing:- an array of status codes, with each entry corresponding to the revision ID specified in the
proposeChangesrequest.- A value of 0 indicates that the server is interested in the rev
- A value of 304 indicates that the server has this revision
- A value of 409 indicates that the changes would cause a conflict
- an array of status codes, with each entry corresponding to the revision ID specified in the
- The client sends a
revmessage for each of the revisions requested in theproposeChangesresponse in step 2. Therevmessage’s body contains the document in JSON form, and the message’s headers contain metadata:idfield whose value is the document ID of the document whose body is includedrevfield with value corresponding to the revision includedsequencefield with the Sequence ID of the changehistoryfield which includes a comma separated list of revision IDs since the known ancestor revision as specified in thechangesresponse
- After all the
revmessages have been sent, in continuous mode, the client waits for the local database to change and returns to Step 1. In one shot mode, the connection disconnects and replication ends.
Pull Replication
During pull replication, a series of changes are sent by the server’s passive replicator in response to a pull request from the client’s active replicator.
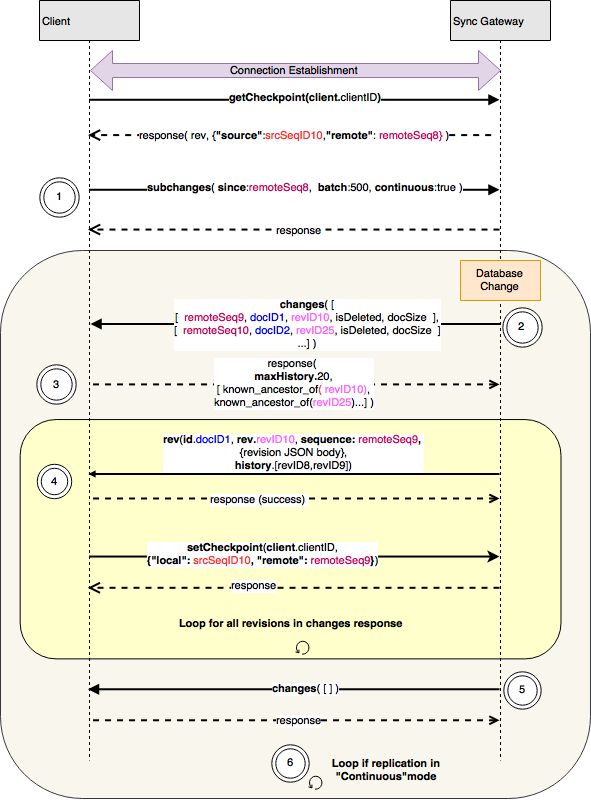
- After the checkpoint is retrieved, the client sends a
subchangesmessage to the server that includes headers:sincefield with the value of the remote sequence IDcontinuousfield to indicate if in continuous mode. A value oftrueindicates that the client wants to be continuously notified of changes.batchfield with value that indicates the maximum number of changes to be sent in a single message
- The server sends a
changesmessage to the client with an array ofchangeobjects corresponding each current revision that has changed. This includes tombstoned revisions. The change itself is encoded as a nested JSON array and includes:- remote Sequence ID which is the sequence ID of the change on the server side
- document ID of the document associated with the change
- revision ID of the current revision of the document
- isDeleted flag to indicate if the revision is a tombstone or not. A value of 1 indicates that this is a tombstone revision
- Optionally, approximate size of the document body
- The client’s response to the
changesrequest includes a JSON object containing:maxHistoryfield whose value is the maximum size of history that the client will accept- an array of known ancestors, one entry for each revision ID specified in the
changesrequest. A null value for an entry indicates that the client is not interested in the corresponding revision.
- The server sends a
revmessage for each of the revisions requested in thechangesresponse in step 3. Therevmessage’s body contains the document in JSON form, and the message’s headers contain metadata:idfield whose with value corresponding to the document ID of the document whose body is includedrevfield with value corresponding to the revision includedsequencefield with value corresponding to the Sequence ID of the changehistoryfield which includes comma separated list of revision Ids since the known ancestor revision as specified inchangesresponse
- When done sending the changes, the server sends an empty
changesmessage to indicate that it has no more changes to send. - After all the changes have been sent, in continuous mode, the connection remains open while the server waits for the database to change and then returns to Step 2. In one shot mode, the connection disconnects and replication ends.
Note that steps 2-4 are identical to push replication steps 1-3, just with the ‘client’ and ‘server’ roles swapped. The replication protocol is quite symmetrical, unlike an HTTP-based API where the roles of client and server require entirely different code. This helps simplify the design and implementation, especially for peer-to-peer replication between clients.
Handling Conflicts
Conflicts occur when there are concurrent updates to the same document revision from multiple sources. Here “concurrent” means “in between replications”: if a client goes offline for an hour and comes back, any changes made on that client during that hour would be effectively concurrent with changes made by all other clients. In such a distributed system, concurrency is not a rare race condition, but a fact of life.
Couchbase Mobile 2.0 supports a new conflict free mode. Details of how conflicts are handled in 2.0 are outside the scope of this blog post but you can read more about it here. At a high level, when the client encounters a conflict while saving a revision, the conflict resolver callback associated with the document is invoked and the resulting merged revision is used. Thus the document never exists visibly in a conflicted state. You can read more about it an upcoming blog post.
Loss of connection to Server
During replication, if the client is unable to connect to the server or if the connection to the server is lost, the client will attempt to reconnect using an exponential backoff algorithm, where it waits longer and longer every time it retries.
- In case of a one shot replication, a maximum of two retry attempts will be made before the client gives up.
- In case of continuous replication, the client will attempt to re-connect indefinitely, but the retry interval will not increase beyond 10 minutes.
The replicator will cancel its timer and immediately retry if notified that the device’s network connection has changed (it’s made a connection to WiFi or a cellular network), But, due to the way IP networking works, the device can only detect changes to its own network interfaces, not changes happening elsewhere along the path to the server, not even on the local WiFi router. So plugging the cable or Ethernet connection back into the router will not be detected immediately. However, turning the router off will be detected, because the device’s WiFi network interface will go down.
Detecting a lost connection can also be problematic. When a TCP connection is idle no packets are being sent in either direction, so neither peer can tell if the other one is abruptly unplugged, or if a connection along the path between them is severed (for example, if the router’s cable or Ethernet is unplugged.) To work around this, the participants send periodic “heartbeat” messages. If the sender doesn’t receive a TCP ACK packet in response to its message within a few seconds, it knows the connection is down.
What Next
The replication 2.0 architecture in Couchbase Mobile 2.0 is cleaner, simpler and more resource efficient than previous versions based on REST API/HTTP.
If you have questions or feedback, please leave a comment below or feel free to reach out to me at Twitter @rajagp or email me priya.rajagopal@couchbase.com. The Couchbase Forums are another good place to reach out with questions.
Finally, special thanks to Jens Alfke (https://github.com/snej), for his feedback.