
There is a great blog on getting the best performance out of our Indexing service: “Create the Right Index, Get the Right Performance.”, both that blog and its advice have stood the test of time. So why not have a query related blog in its namesake?
Anyway I think the same can be said about our Query service – to get the right performance, craft the right query. The Index service can take a lot of flak for being the single contributor to query performance. But there are times where both the query and the index you’re using needs to be changed.
Hopefully here we can show an example where it could just be a query tweak which has to happen in order to get the enterprise grade performance which Couchbase is renowned for. The following example is based on a question which was brought to us from one of our customers, so hopefully this will be helpful to a number of people using Couchbase “in anger”.
Your Environment
Let us use an example, and furthermore lets make this easy to follow, I’m a big fan of blogs which allow readers to follow along if they wish. To set the ground rules here are a few components you could use to make this example happen:
- The ever useful couchbase.live development environment. Hanging out in your hammock on a beach in Bali? I understand, if you fire up your own Couchbase docker container, fans ablaze and there will be sand straight in your Mojito. As long as you have an Internet connection we can give you 30 minutes dev environment free of charge! Obviously you’re free to use any Couchbase environment you have already.
- The travel sample data set
- Your handy N1QL array documentation
- This handy pocket reference blog on working with arrays
N.B. The N1QL examples here will be using our scopes/collections feature – as such the bucket context is set to the default scope in the travel-sample data set.
Some Real World Context
To set the scene of this example we can use a common use case – marketing campaign generation. One example of this query could be to find visitors to the hotel who have left a review and liked the hotel – this data could lead to them being entitled to rewards for a loyalty program, better targeted/similar hotel stays, or just an insight into users who are likely to leave a review/like. All of these insights provide valuable data to better serve our hotel guests.
The main purpose of this specific example is to show you the possibilities of querying multiple arrays within a single JSON document, and again plant the seed that sometimes you can pull even more performance out of your query service after creating the right index. Afterall, you’re making use of a system which allows for dynamic data fields and arrays are a big part of the flexibility of using JSON as a data format.
Humble Beginnings
A common way to query arrays in n1ql (as explained in the linked blog), is through the following:
|
1 |
SELECT (ANY v IN [1, 2, 3, 4, 5] SATISFIES v > 4 END) as is_found, (ANY v IN [1, 2, 3, 4, 5] SATISFIES v = 7 END) as not_found; |
In this example we’re saying: “get me items from the array, which match the condition in the SATISFIES statement”.
If we we’re to apply this method to our attempts to query multiple arrays in a JSON document it would likely look like the following:
|
1 2 3 |
SELECT public_likes, reviews FROM _default WHERE type="hotel" AND ANY r IN reviews SATISFIES r.author = "Ozella Sipes" END AND ANY l IN public_likes SATISFIES l = "Ozella Sipes" END LIMIT 1; |
However this would not lead to a performant query, as N1QL currently requires you to construct a single indexable array from the arrays in the document, as noted here.
Creating Indexes for Multiple Array Fields
So how do I construct such an index I hear? Lets walk through an example, using our use case of gathering data on guests who have liked and reviewed our hotels.
|
1 2 3 4 5 |
CREATE INDEX `reviewers_likes_idx` ON `_default`( DISTINCT ARRAY ( DISTINCT ARRAY [l,r.author] FOR r IN reviews END) FOR l in public_likes END) WHERE type="hotel"; |
What we’re doing here is creating an index with a single array of combined likes and reviews. This is best practices and supports the note in our documentation. Just to show you a way in which you might have thought would be correct: here is the unsupported and way to definitely not index multiple array fields:
|
1 |
CREATE INDEX `not_the_right_idx` ON `_default`( DISTINCT (ARRAY r.field FOR r in json_obj END), likes); |
This would index multiple array fields – not advised.
Improving the Query
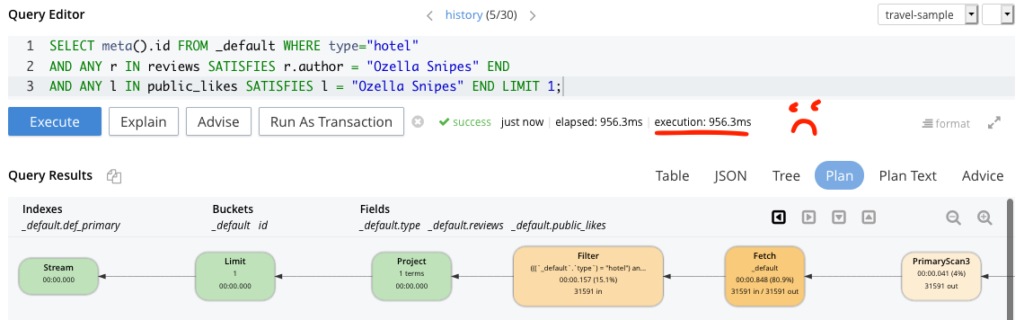
Below are two examples of queries which have been ran on our query workbench. Using my improved query I got my execution time down from 956.3ms to ~4ms. Try it out yourself, the improved query is at the end of this blog.
Non Performant Query
Improved Performant Query

In essence, both of our queries would work, however the times taken to execute both of the queries massively differ, and this is because we are making use of the carefully crafted and best practices index in the latter query. If you’ve followed along this far, you can run it for yourself. Be aware, I’ve added “Ozella Sipes” to be both a review Author and a public liker in one of the hotel documents to test my query works! Your results may differ depending on the name you use.
|
1 2 3 4 5 |
SELECT META().id FROM _default WHERE type="hotel" AND ANY l IN public_likes SATISFIES ( ANY r IN reviews SATISFIES [l,r.author] = ["Ozella Sipes", "Ozella Sipes"] END) END LIMIT 1; |
I hope this blog has been useful, and given you insight that in some cases, using the right query to get the right performance also needs to be considered!